









最近发现线上服务器经常报连接Redis异常:Uncaught exception 'RedisException' with message 'redis server went away'。
于是摘下一台线上机,对服务器一半以上的接口进行压测:
$ http_load -p 100 -f 100000 urls.txt
100000 fetches, 100 max parallel, 2.46403e+09 bytes, in 46.6896 seconds
24640.3 mean bytes/connection
2141.81 fetches/sec, 5.27747e+07 bytes/sec
msecs/connect: 1.04977 mean, 3.755 max, 0.859 min
msecs/first-response: 44.0343 mean, 142.5 max, 11.804 min
HTTP response codes:
code 200 -- 100000
$ http_load -p 100 -s 100 urls.txt
145919 fetches, 100 max parallel, 3.65654e+09 bytes, in 100 seconds
25058.7 mean bytes/connection
1459.19 fetches/sec, 3.65654e+07 bytes/sec
msecs/connect: 1.10872 mean, 14.339 max, 0.863 min
msecs/first-response: 65.4696 mean, 1012.95 max, 12.124 min
11082 bad byte counts
HTTP response codes:
code 200 -- 134837
code 500 -- 11082
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
发现当接口的请求量达到10w的时候,QPS可以达到2000以上;请求量超过10w的时候,QPS会降到1500以下,需要访问redis服务的接口会出现Redis server went away异常,并返回500。
难道说现在机器负载的瓶颈就是redis了吗?压力测试时的redis服务器压力大么?
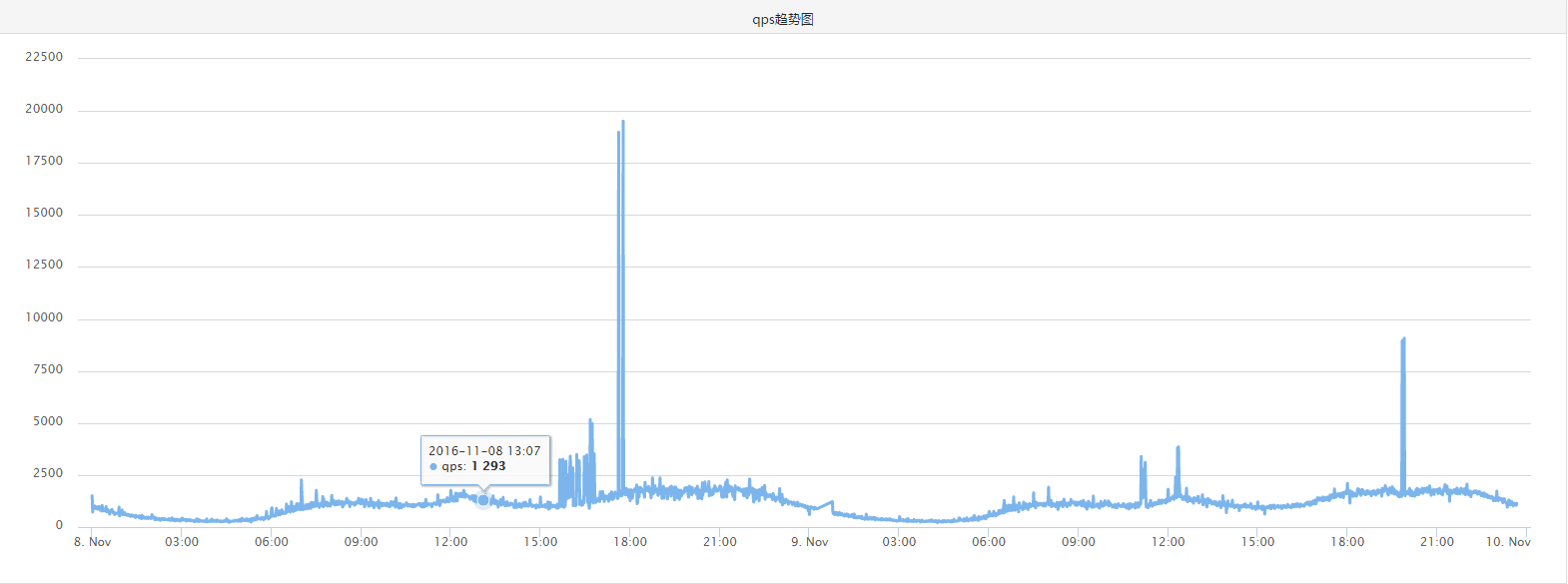
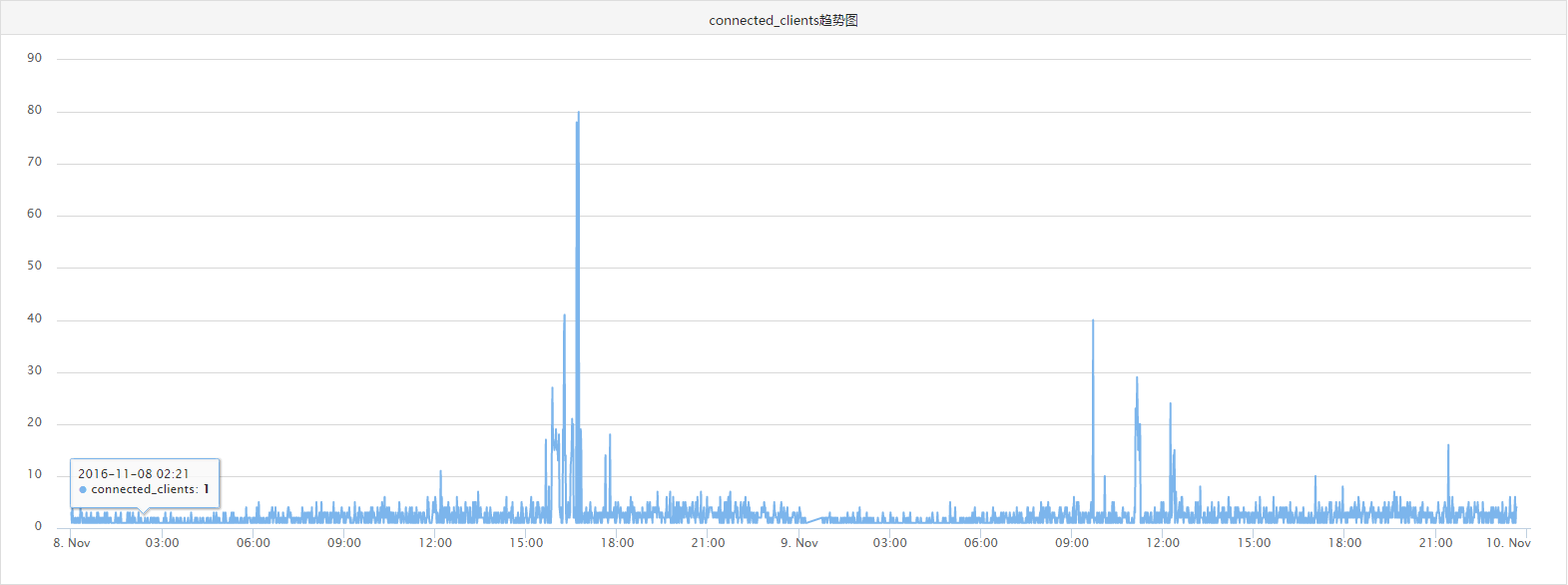
从监控的趋势图可以看到,压测接口请求的redis最高QPS也就20000,客户端连接数只有不到80,压力并不大。所以瓶颈不会是在redis服务器上。
在排除了Linux,PHP,nginx,redis配置方面可能出现的问题后,最后锁定问题,应该是在连接Redis的时候出现异常。那php是如何连接redis的呢?使用redis扩展。而问题很有可能出在php的redis扩展上,就是phpredis。
通常我们在使用phpredis连接redis的时候,都是用的connect()方法,在大量的php请求请求到redis的时候,这种方式会不断的建立和关闭连接,占用很多资源,导致服务器出现大量的TIME_WAIT,这样就会有很多php请求无法连接redis,出现Redis server went away这个异常,实际就说明redis服务没有收到请求,所以昨天看到在压测过程中redis负载压力并不大,但php还是返回500。
之前的思路都是以为redis层面问题或者服务器配置甚至硬件问题,在换个思路之后,发现phpredis还有个连接redis的方法,就是pconnect(),这个方法很多人都知道,但是很少把它和高并发联系到一起,pconnect()和connect()的区别网上有很多,总结一下就是pconnect方法建立后的连接并不随这请求的结束而关闭,而是依赖于php-fpm进程,php-fpm进程不死,redis connect就一直存在,直到空闲超时自动断开(目前redis timeout 600),这样就极大的提高了redis connect的重复利用,减少大量的IO开销。不过这样也就出现一个瑕疵,就是redis的connect clients数量要比以前高出很多,目前线上机单台服务器php-fpm进程300,线上服务器共有12台,单台redis最高connect clients可以达到3600,不过这也远低于单台redis配置的maxclients 200000。
所以我在之前的机器上做了修改,然后重新压测:
$ http_load -p 100 -s 100 urls.txt
253884 fetches, 100 max parallel, 6.44571e+09 bytes, in 100 seconds
25388.4 mean bytes/connection
2538.84 fetches/sec, 6.4457e+07 bytes/sec
msecs/connect: 1.07964 mean, 13.918 max, 0.858 min
msecs/first-response: 36.6679 mean, 250.973 max, 7.66 min
1 bad byte counts
HTTP response codes:
code 200 -- 253884
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以看到100个进程跑了100s,请求量253884,QPS达到2538.84,这个数字基本正常。
再看一下redis负载情况:
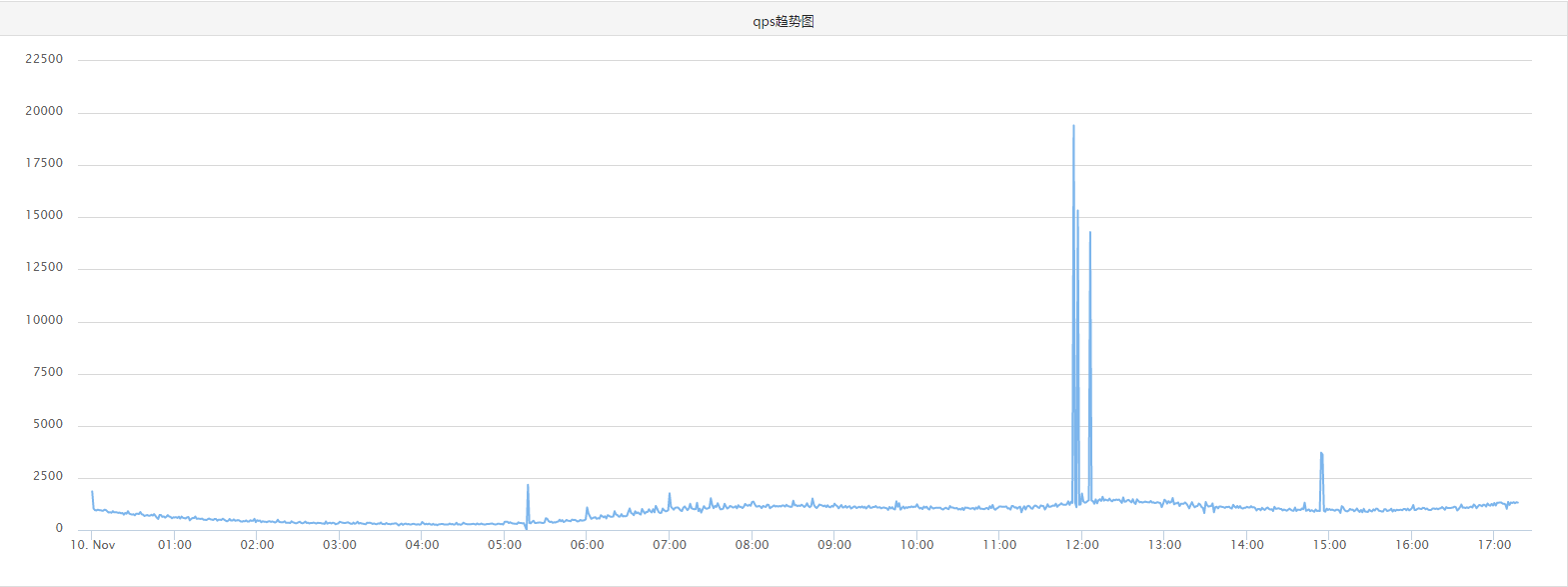
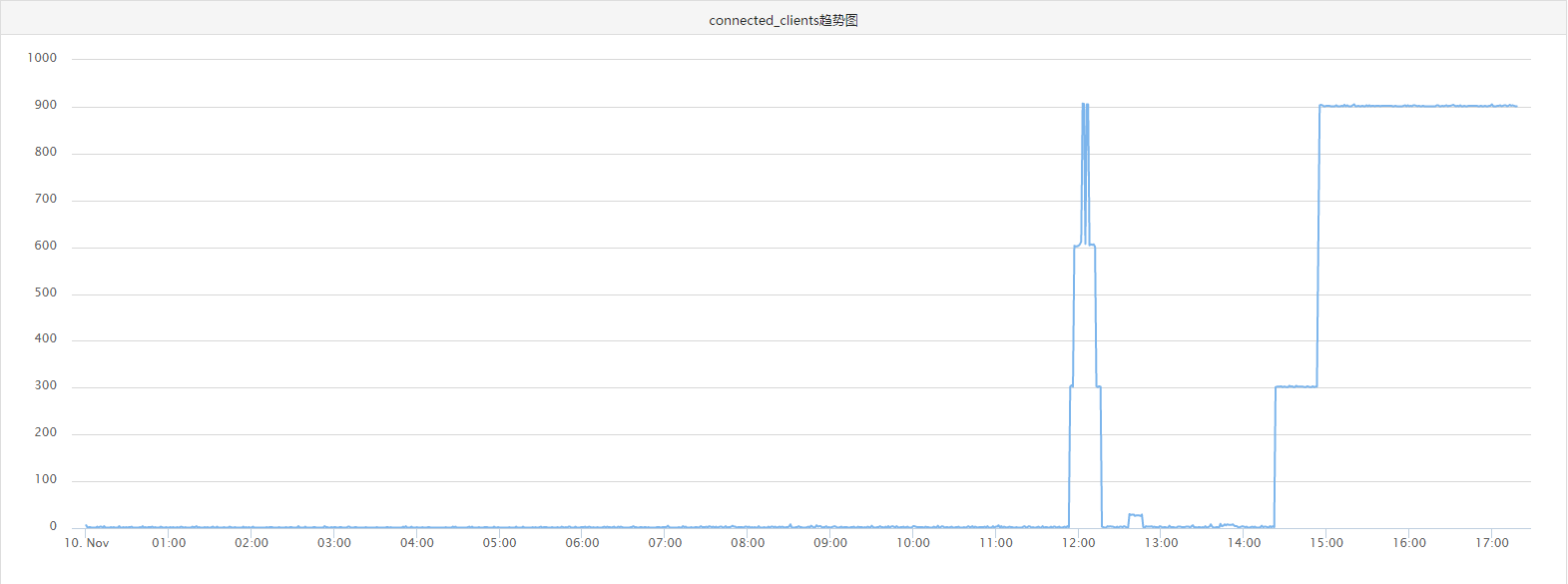
重新上线了三台机器之后,可以看到redis端connect_clients明显增加,但是QPS还是很平稳(请忽略压测导致的凸起点)。
最后有必要反思一下这个过程,其实最后解决问题的方法是有点狗血的,因为pconnect方法很多人都知道,但是都没有把这个方法和高并发请求redis联系起来,所以我严重怀疑很多人对这个方法理解的并不深刻。在遇到问题时,一定要敢于尝试,如果你发现这个问题Google上都没有答案的时候,你应该觉得这是个挑战,所以不要轻易放弃。还有眼界要广,不要纠结于一个点,像redis这么成熟的软件系统,十万级的访问量基本不会构成威胁,所以要检查一个请求经过的每一个环节。















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









