






论文标题
Position-Aware Depth Decay Decoding (D^3): Boosting Large Language Model Inference Efficiency
论文地址
https://arxiv.org/pdf/2503.08524
作者背景
BAAI智源研究院,电子科技大学,中科院自动化研究所
前言
“自适应神经网络”并不是一个新概念,它通过动态调整模型的计算深度来提高计算效率,让简单的结果快速输出。在传统CV/NLP领域便有过诸多探索,Transformer架构上也有过像FastBERT这样的工作;
对神经网络架构做自适应调整,关键是分析出哪些模块适合动态调整,哪些不适合。相比于之前的在LLM上做自适应调整的成果(是Early Exit和SkipDecode),此工作做了更有说服力的探索
以下方法都不需要重新训练LLM
Early Exit
如图所示,大模型的大部分 token 并不需要通过所有层进行计算就能达到较高的置信度
Early Exit是一种“早退出”的自适应推理方法,通过训练一个分类器来决定每个token在每一层上是否需要提前退出
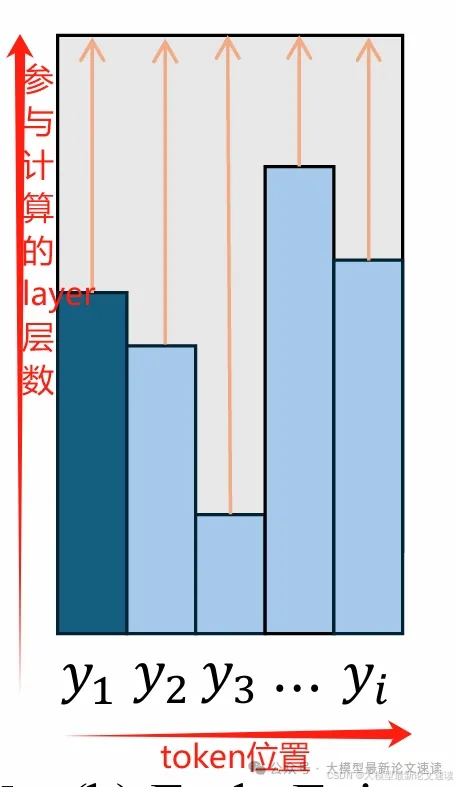
考虑到当前KV-Cache已成为广泛使用的加速手段,上述做法有一个很大的问题:如果上一步的token是在L1层退出的,并且当前token需要在L2层退出,并且L2>L1,那么当前token计算到L1时就无法使用KV-Cache了!(因为上一步根本就没算这些层的KV状态)
此时需要有一个弥补性操作:把L1末尾的KV状态复制到与L2对齐
SkipDecode
跳过开头部分layer的自适应推理方法,跳过layer的数量随推理长度线性增加
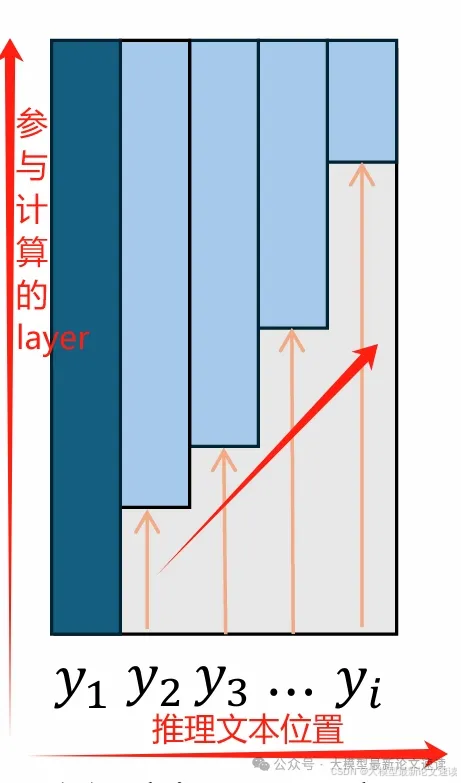
同样地,此方法也会遇上KV状态缺失的问题,同样也是通过复制解决
本文方法
本文提出D3方法(Position-Aware Depth Decay Decoding),主要有以下几个创新点:
一、核心层与灵活层划分
通过观察LLM各模块、各层次的输入输出,发现信息流主要在模型的开头和末尾部分发生变化
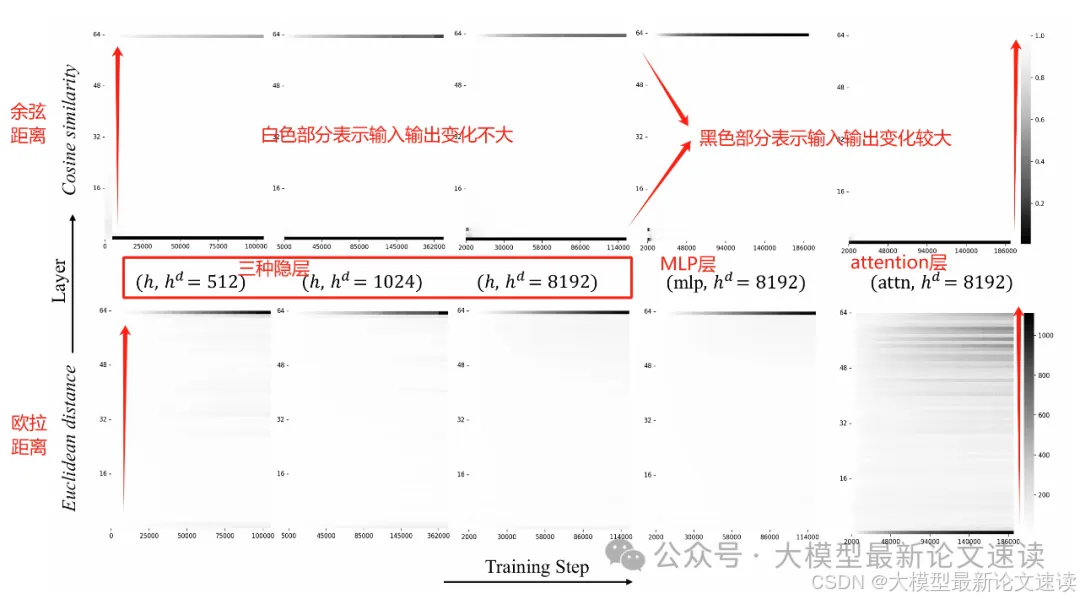
如上图所示,大模型的各个模块,无论是从欧氏距离还是余弦距离来看,输出输出的差异主要产生于开头和结尾部分(attention模块的欧氏距离稍有不同)
直观的解释为:靠近embedding的层次主要处理抽象、基础的特征;靠近输出的层次主要负责对齐
所以不同于Early Exit跳过结尾、SkipDecode跳过开头,D3是在经过分析后选择跳过了中间部分:
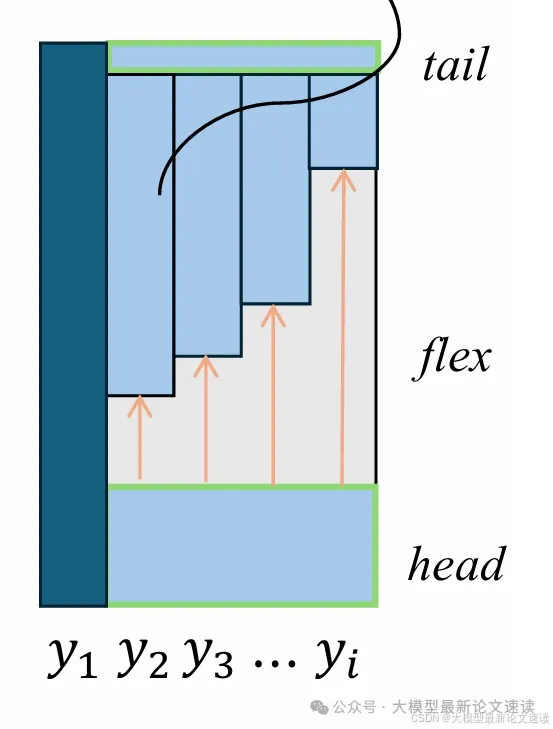
而开头和结尾部分的具体范围取值,可以作为超参数来设置
二、指数扩大的跳过范围
之前提到的KV状态对齐问题,在自适应计算中是不可避免的:“自适应”一定会跳过一些模块,模块跳过后一定会导致对齐问题
所以作者退而求其次,观察从不同层次开始复制,对模型性能的影响
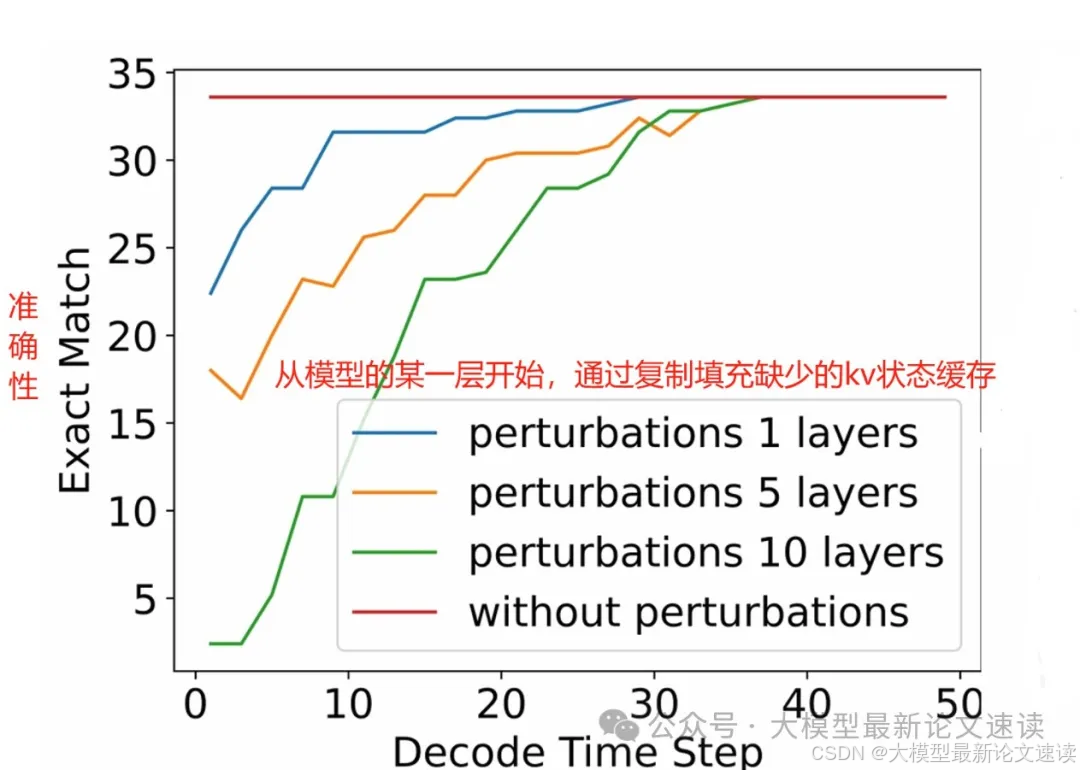
如上图所示,越从浅层开始影响模型,对模型效果的伤害越大
此外,还发现大模型在推理时,位置越往后的token困惑度越低,表明生成任务的难度随文本长度的增加而减少
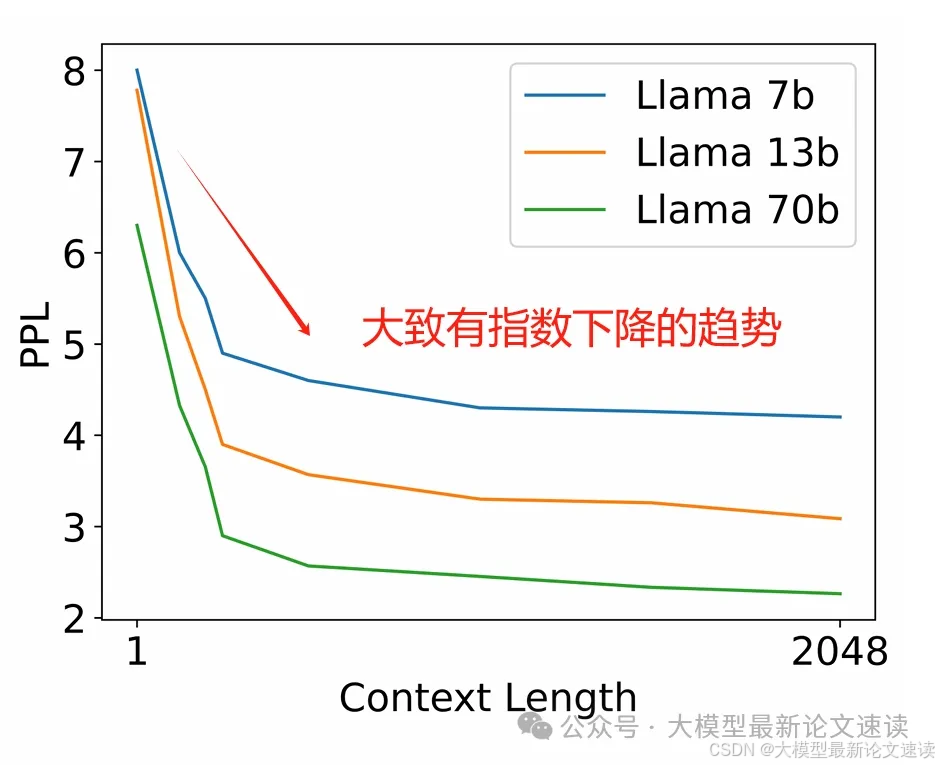
于是作者设计了这样一种简单的方法:让灵活层参与计算的layer随着推理步的增加而指数衰减
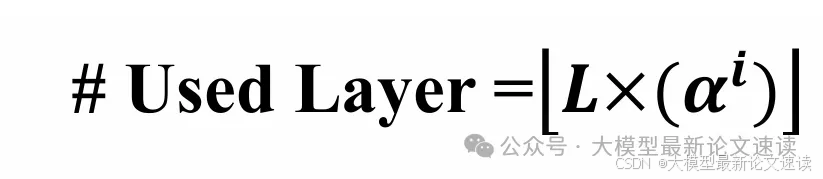
注:为什么不适用分类器?作者认为会引入新的复杂度,当前方式效果已足够好
效果
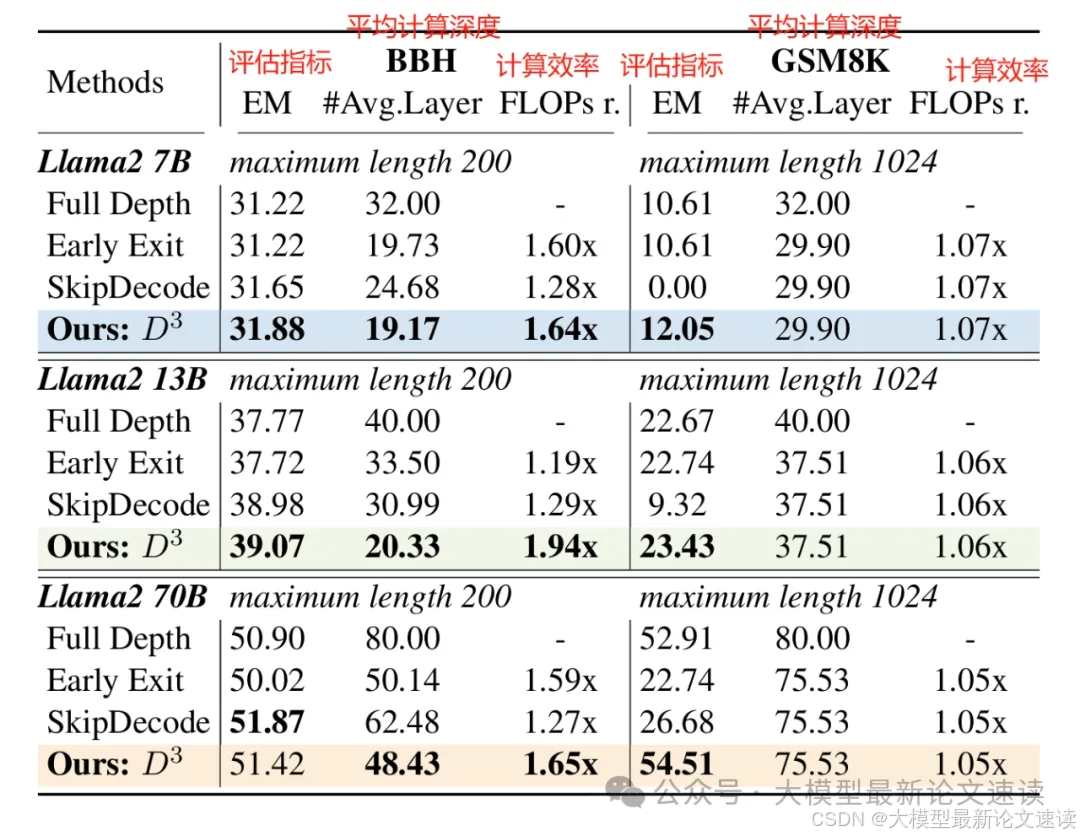
由图可见,D3推理优化训练,可以在不更改大模型自身参数,通过提高过某些层次的计算,实现更高效的推理速度,并且推理准确性保持不下降,甚至会提高


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









