






前言
本文旨在微调大模型的同时确保模型的安全性不降低,对于任何一种类似于:“保证模型能力A不下降的情况下,尽可能提高能力B”的场景,都具有很好的启发意义
论文标题
SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
论文地址
https://arxiv.org/pdf/2503.17239
代码地址
https://github.com/aladinD/SafeMERGE
作者背景
慕尼黑工业大学,IBM研究院
动机
微调是让LLM适配定制化任务的重要手段,然而即便是针对无害数据的微调,也可能破坏模型的安全对齐,导致生成有害内容(暴力、歧视性言论等)。目前针对微调后安全性的恢复方法,存在不少问题:一些方法需要复杂的定制化算法,而另一些则牺牲了任务性能以保证安全性。因此,如何在不显著降低任务性能的前提下,恢复和保持模型的安全性,是当前亟待解决的挑战。
本文希望在对模型进行微调微调时,在保证安全指标基本不下降的同时,尽可能提高业务效果
本文方法
本文提出了SafeMERGE框架,主要思路是:在训练业务lora的同时,也构造一个安全lora,然后选择可能存在安全风险的layer去合并这两个lora,没有安全风险的只合并业务lora,整体流程如下图所示:
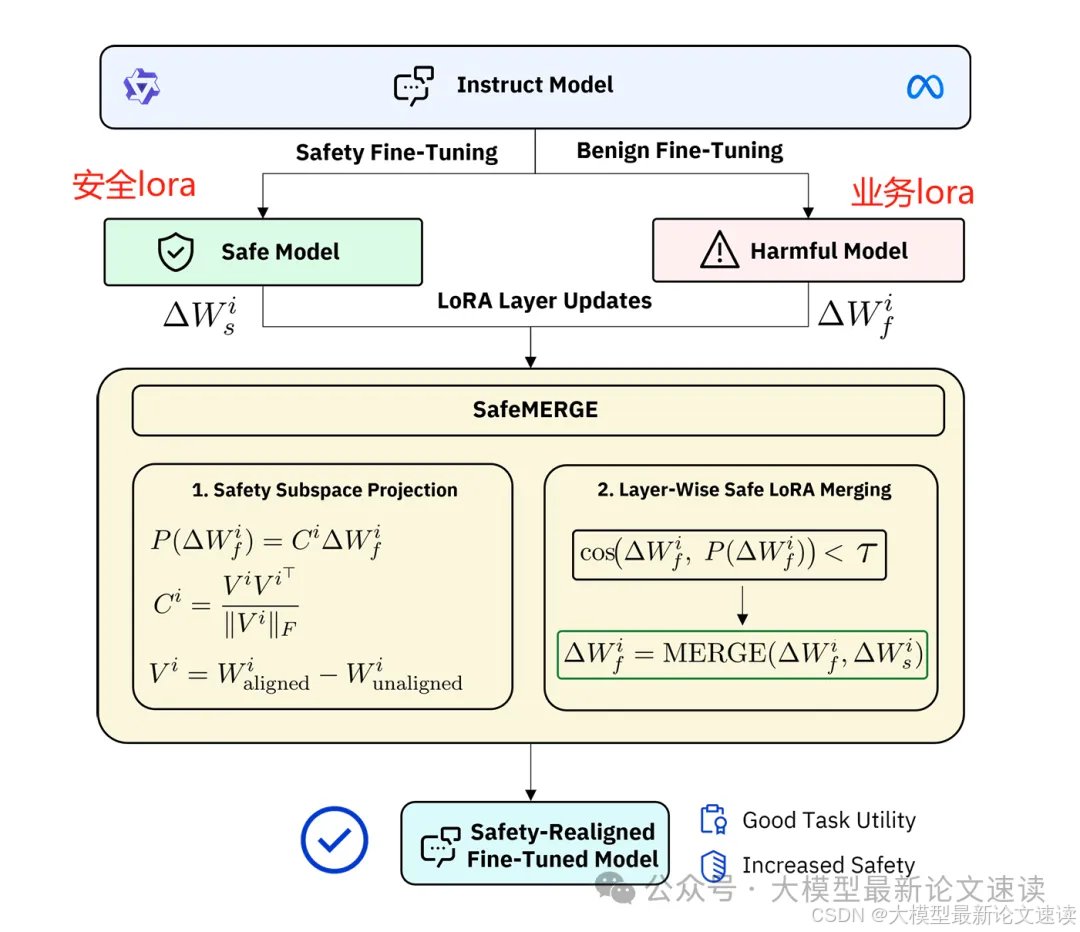
一、安全子空间投影
为了衡量模型在业务数据上做完微调后,安全性是变好还是变差,需要把参数的变化量投影到一个“安全子空间”。这个子空间通过使用安全数据进行lora微调模型得到,由于lora本身拟合的对象就是参数变化Δ,所以上图中的“安全lora”,代表的就是模型安全性提升的方向,即“安全子空间”。
现在考虑如何把业务lora投影到这个子空间。先说结论:让业务lora乘以下面这个投影矩阵,便可将其投影到安全lora上

下面简单推导一下,回顾初中数学的内容,可知点积计算公式与向量加减法:
a·b=|a||b|cosα
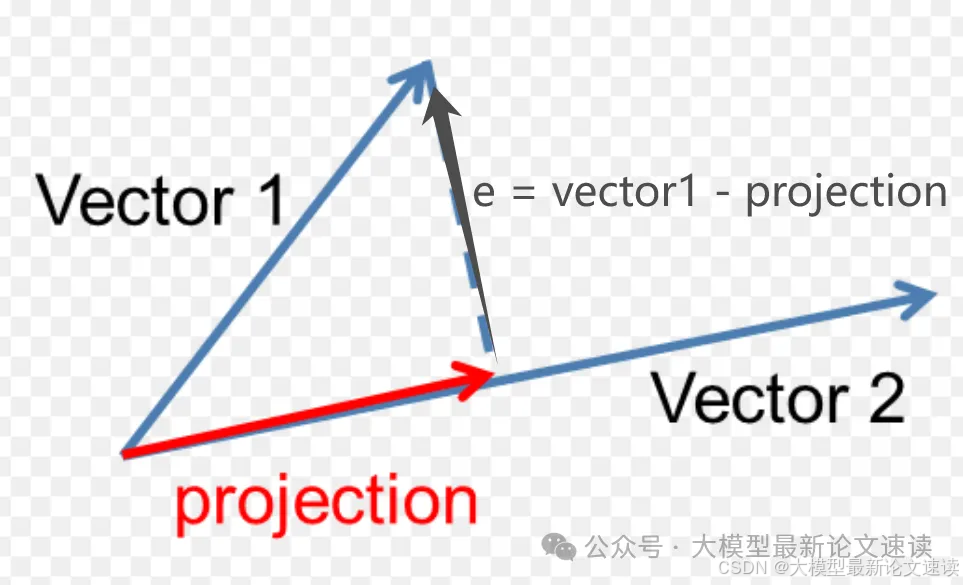
由于projection与e垂直,二者的点积为0;由于projection与vector2共线,有projection = X * vector2,于是:


所以,想要把vector2投影到vector1上,需要乘以上图的红框部分
二、识别并合并偏离安全对齐的层
按照以上分析,把业务lora投影到安全lora上可以获取到当前微调对于提高模型安全性上的改动,此时便可以对比整体变化与安全改良之间的差距,如果超过了某个超参数,则需要合并安全lora以扭转有害性提升的趋势

实验结果
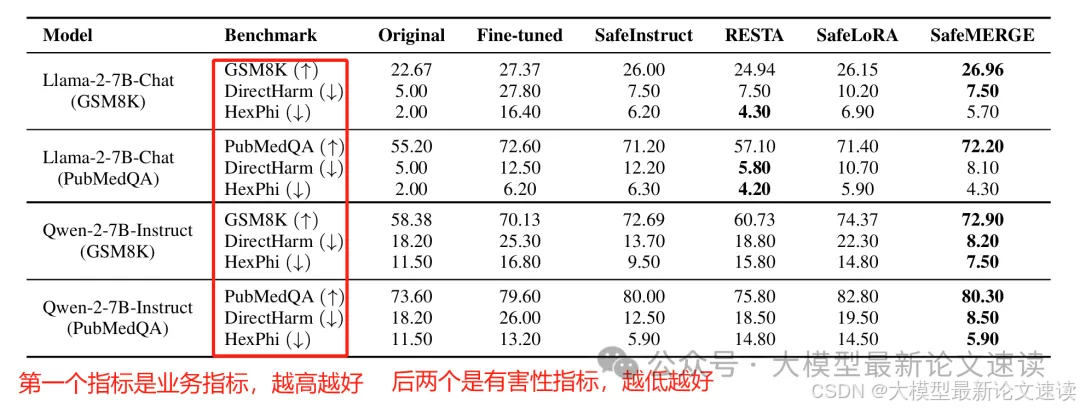
对照组说明:
- original:原始Model
- Fine-tuned:只进行业务微调
- SafeInstruct:安全数据混合到业务数据中
- RESTA:将有害任务向量负向合并到微调后的模型中,以期恢复安全性
- SafeLoRA:前序工作,和实验组很类似,不同点在于它直接计算每层权重与安全lora的相似度,低于阈值则使用上述投影矩阵强行投到安全子空间中
https://arxiv.org/pdf/2405.16833

















 3305
3305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









