






论文标题
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
论文地址
https://arxiv.org/pdf/2503.09516
代码地址
https://github.com/PeterGriffinJin/Search-R1
作者背景
UIUC伊利诺伊大学香槟分校,计算机科学系
马萨诸塞大学阿默斯特分校,智能信息检索中心
前言
幻觉、知识过时是当前大模型最大的缺陷,通过引入外部知识可以缓解这些问题。但实际中知识引入的手段,都是让大模型生成工具调用指令,然后由写好的执行程序去获取知识检索结果。本文希望让大模型真正学会这样的能力,自主地决定何时搜索、搜索什么;
提升大模型工具利用的能力,甚至是让大模型吸收这样的能力,似乎是当前的热门研究方向,并且大多是情况下也确实有效果。本文便是一篇典型的利用强化学习让大模型学会更好地使用搜索引擎的新工作,相关代码已开源
本文方法
一、整体流程
在标准的PPO和GRPO流程中,加入搜索引擎,如下图所示
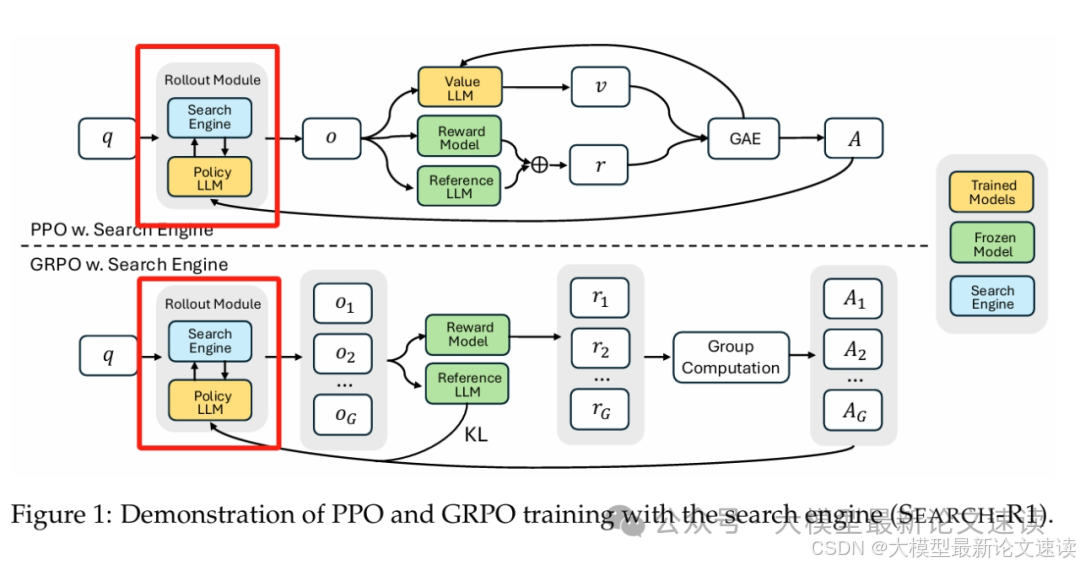
二、数据格式
首先准备了7个问答数据集,具体包括:

从NQ和HotpotQA两个数据集中采样训练集和测试集,其他数据集作为分布外的测试集验证泛化性
然后还要使用以下提示模板构造具体数据,question替换为具体问题。其中模型的推理过程被<think>标签标记,搜索查询语句被<search>标签标记,搜索结果被<information>标记,最终回答使用<answer>标记

三、推理过程
不断地让模型推理-搜索,如果推理出了答案,或者搜索次数达到上限,则退出

四、训练目标
可能受到计算资源的限制,作者只在:qwen2.5-3b/7b-base/instruct和llama3.2-3b-base/instruct这6个模型上进行了强化学习训练,训练目标仅仅是最终答案的匹配准确性(没有像思考长度、格式之类的任何其他目标);
此外考虑到检索文档一般都比较杂乱,为了保持模型训练的稳定性,search-R1 mask掉了被<information>标记的检索结果,不让其产生梯度
结果
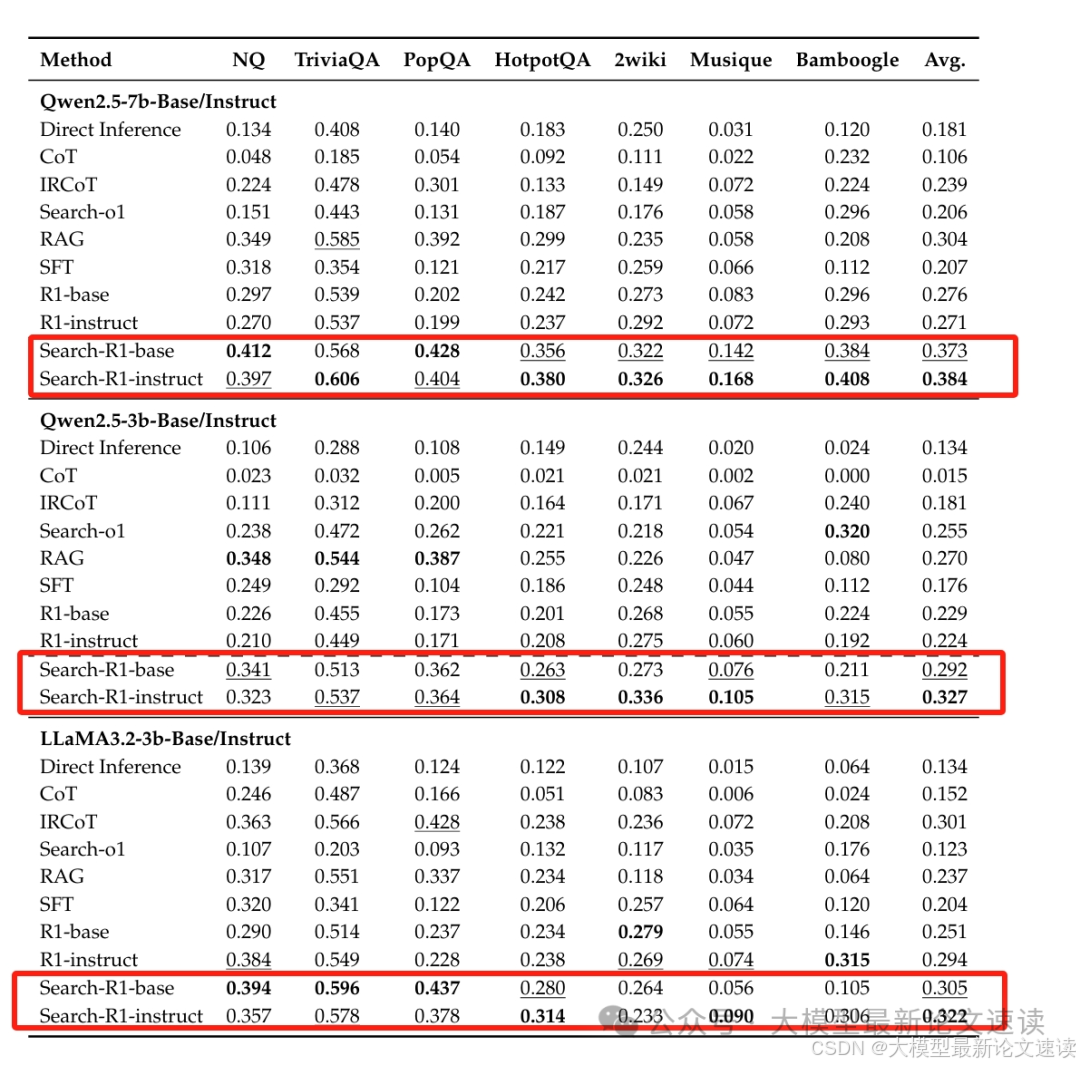
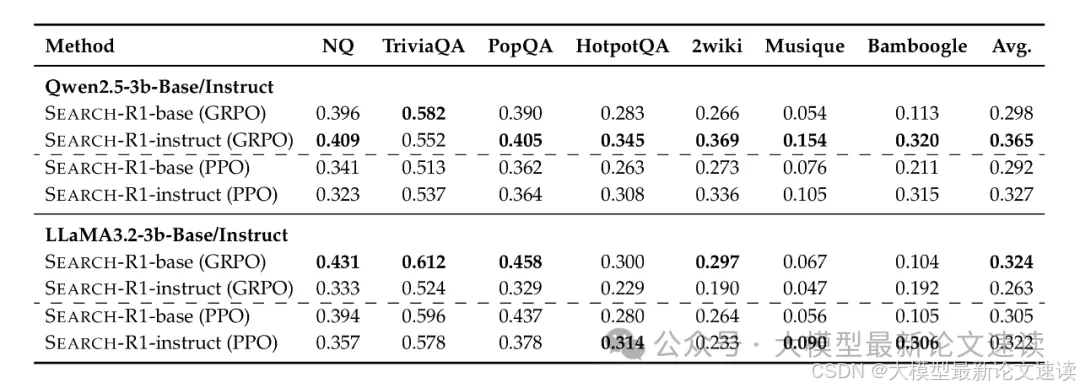
一、整体效果
与包括COT、SFT、RAG在内的许多方案做了对比,多数情况下Search-R1模型效果更好,好于RAG方案
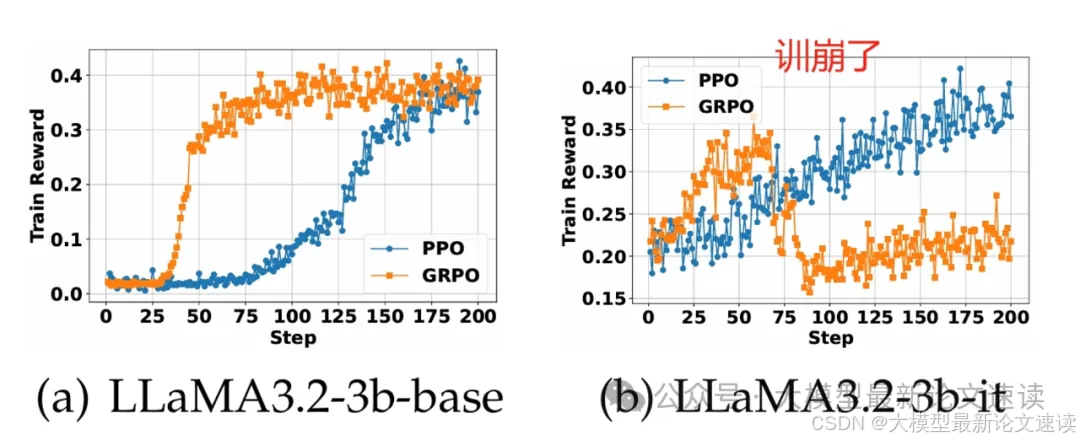
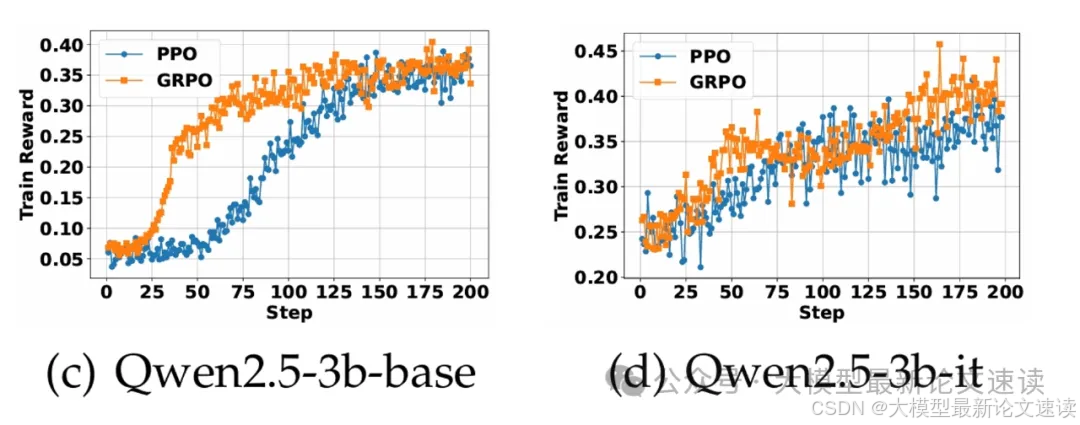
二、PPO与GRPO对比
在本文设置下,GRPO体现为快速收敛,但不如PPO稳定
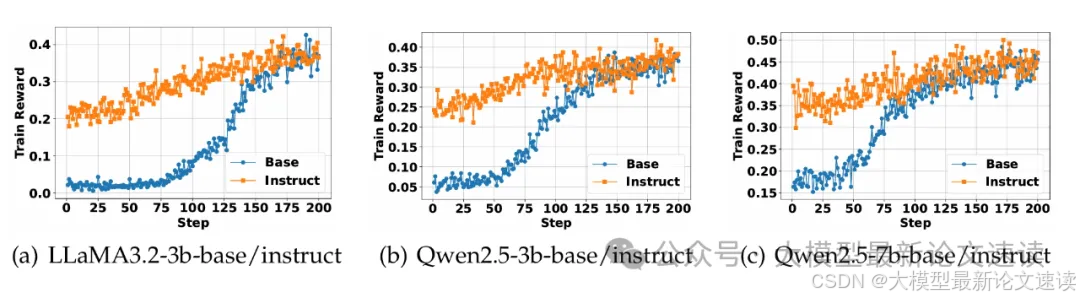
三、Base/Instruct对比
作者对比了分别基于base模型和基于instruct模型的效果,体现为instruct模型收敛更快,在初期效果更好,但最终效果差不多。这再次说明了纯强化学习方案的可用性
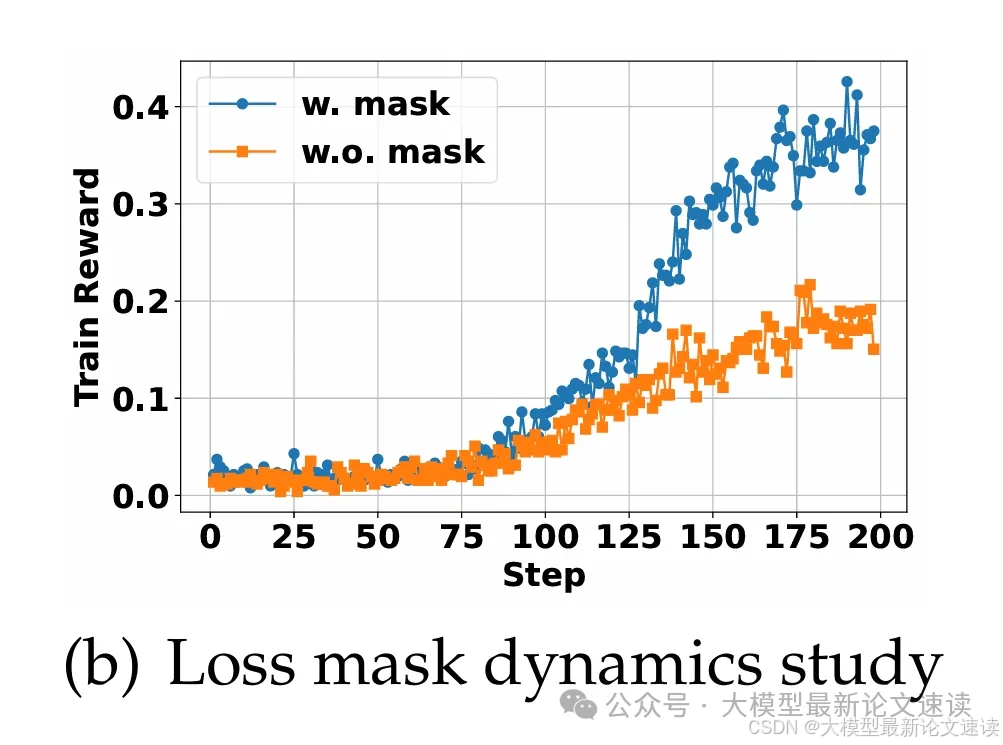
四、检索mask消融
作者分析了对检索结果进行mask这一操作的有用性,做了消融实验,证明了此操作的必要性
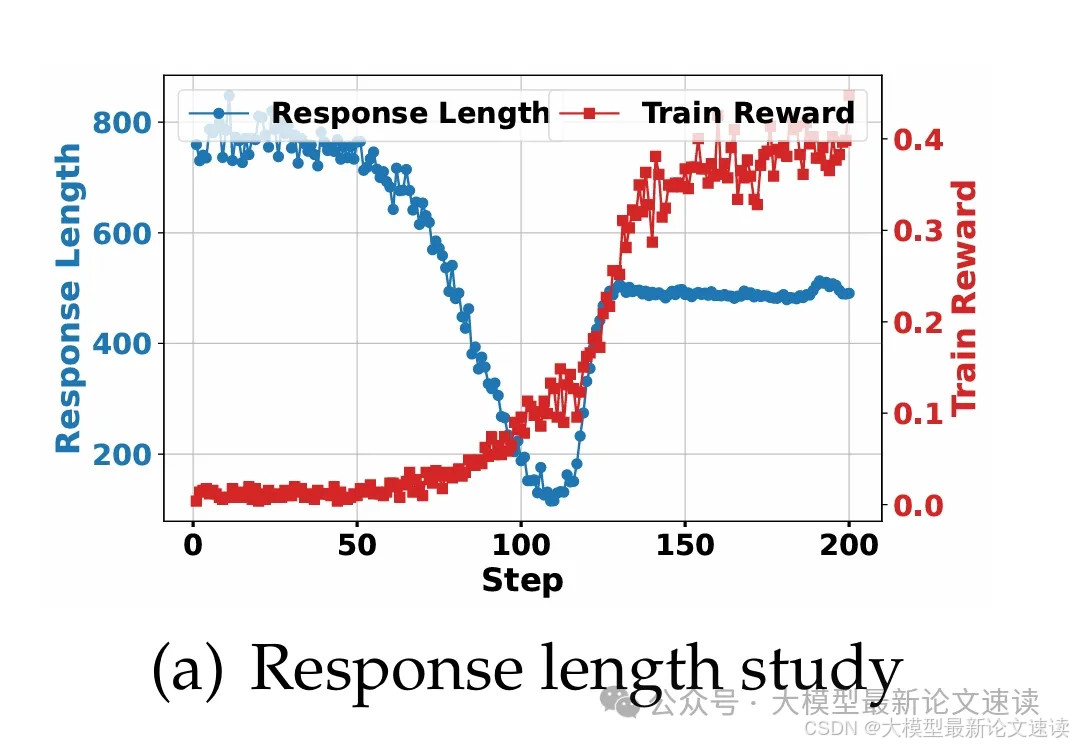
五、训练过程中模型输出的长度
作者发现search-R1在训练过程中,模型输出的长度会经历骤减-上升-趋于平缓3个阶段,其中长度开始上升时模型效果开始迅速提升
六、具体案例展示

总结
本文的启发
-
再次证明了通过强化学习赋予模型新能力的优越性,以及简单规则反馈信号的有效性
-
大模型+搜索引擎是目前实际中常用的方案,很多场景下都可以考虑让大模型去学习搜索(并且这次的git终于不是空仓库了)
本文的不足
-
仅仅在小尺寸上模型做了实验,有些结论可能不够solid
-
没有设计其他奖励函数,作者说留给未来探索

















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









