






论文标题
ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models
论文地址
https://arxiv.org/pdf/2503.22048
代码地址
https://github.com/Trustworthy-ML-Lab/ThinkEdit
作者背景
加州大学圣迭戈分校
动机
链式推理能显著提升大模型求解复杂问题的能力,尤其是对于数学、代码等逻辑推理任务。然而,即便经过专门的强化训练的推理模型,在简单基准(如小学数学问题数据集 GSM8K)上仍未达到完美水平。
研究者发现,一个重要原因是模型有时会产生过短推理的链条——即推理步骤异常简短、抽象,草草几步就直接给出结论。这种不充分的“短路”思考往往伴随着性能下降:在较困难的数学基准(如 MATH-Level5)上,过短推理的答案准确率比正常情况降低了约 20%。可见,推理链的长度对问题求解效果起着至关重要的作用,如何避免模型过早停止思考成为值得关注的问题。
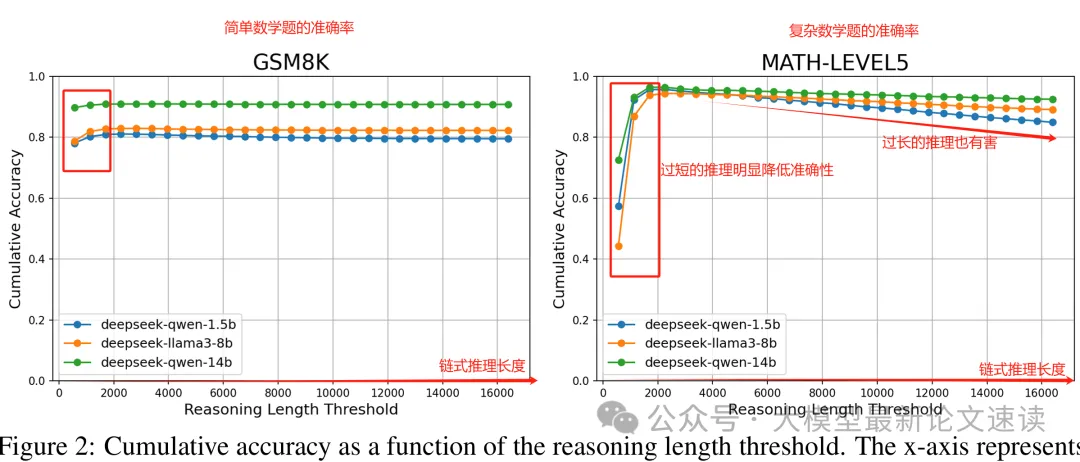
尽管已有很多工作通过强化学习鼓励模型进行长推理,但依然存在机理不明和干预困难的问题,作者对此进行了深入探究,以解决这两项挑战
相反地,之前也介绍过一篇解决大模型“过度推理”的文章:
Uncert-CoT: 计算不确定性判断是否启用CoT
本文方法
本文提出ThinkEdit,通过可解释的权重编辑来减少过短推理
一、提取推理长度方向
作者首先探究模型隐藏层中是否存在与推理长短对应的特征。一个很自然的思路是:准备一批测试集让LLM进行链式推理,将出现极长(超过1000token)和极短(低于100token)思维链的结果分为两组,然后对比分析二者的隐藏层差异。
具体地,作者考察了两类输出在Attention模块输出,以及MLP模块输出上的差异,直接将极长组的平均向量,减去极短组的平均向量作为“推理长度方向”
接下来需要验证这个“推理长度方向”是否能直接决定大模型的推理长度。验证方法很简单:直接把对应的隐藏层向量上添加此方向上的扰动,然后观察模型输出的准确率(左)和长度(右)变化,结果如下:
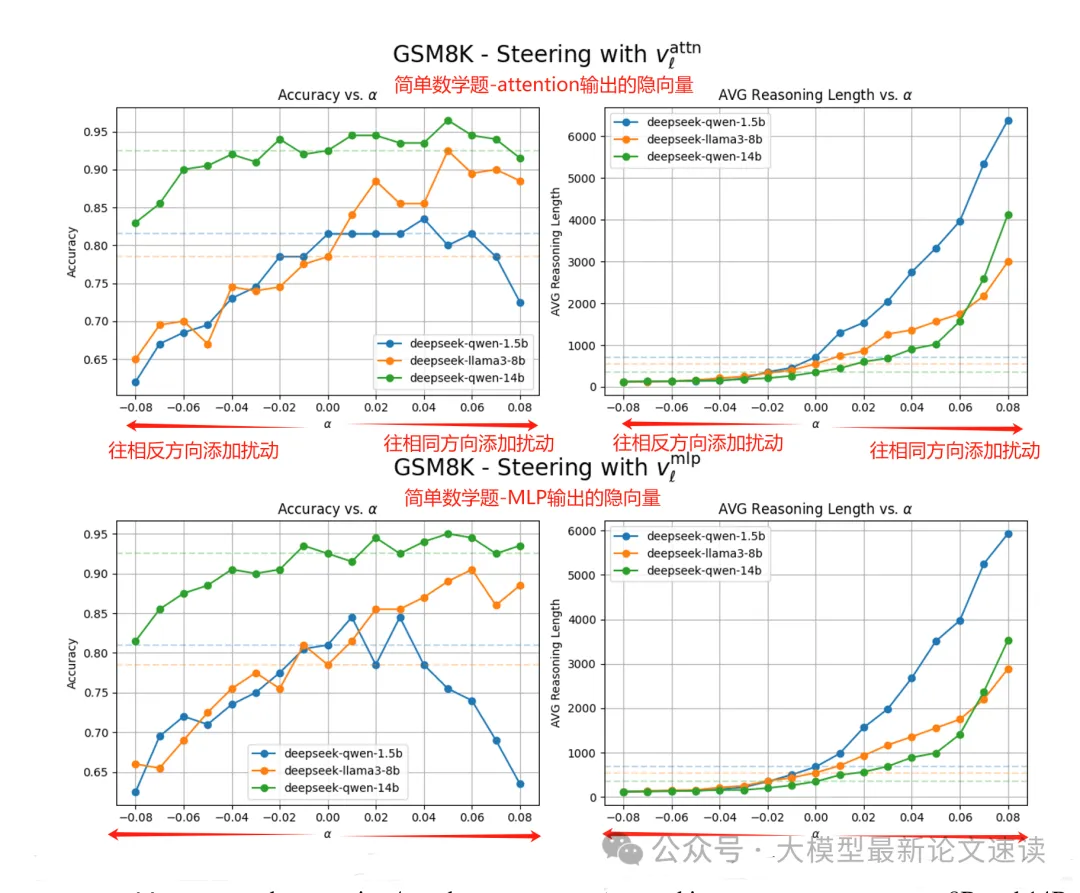
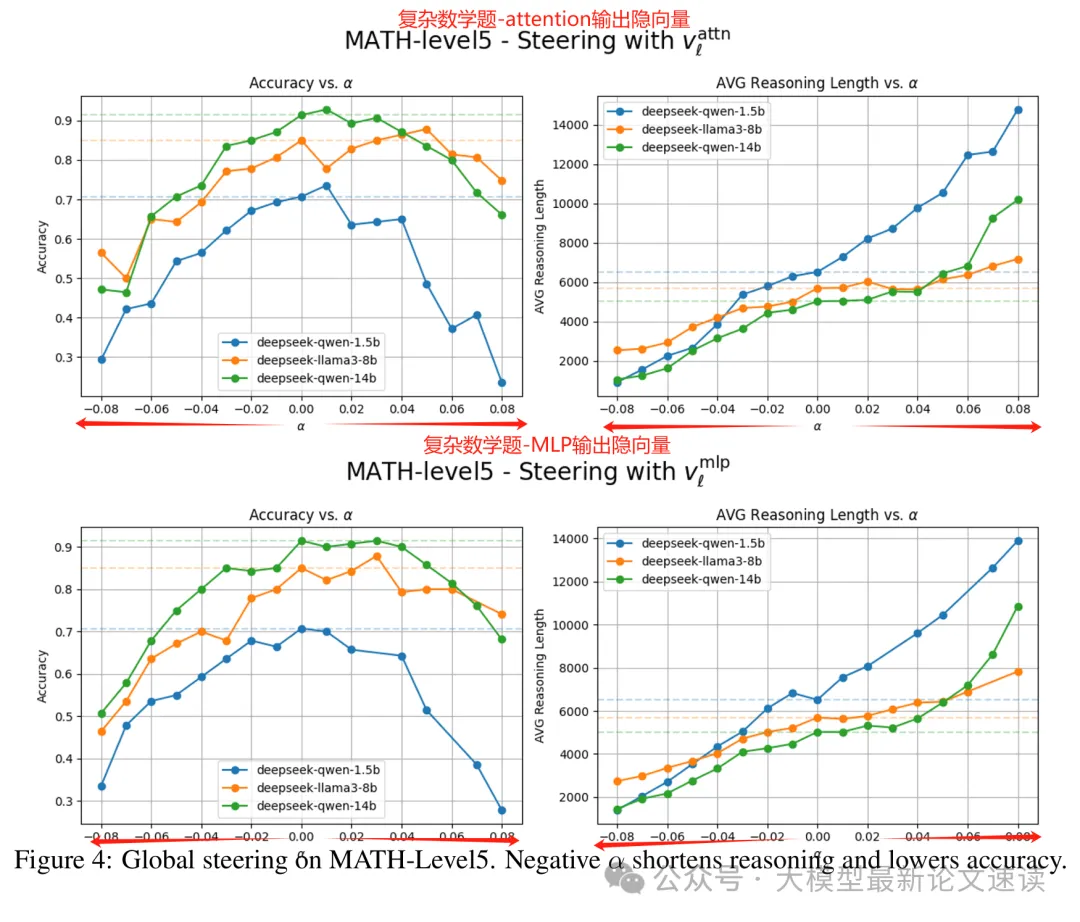
可见上述“推理长度方向”与模型输出长度强相关,并且具有良好的可控性,这让我们手动控制大模型思考链长度带来了希望。
二、识别关键注意力头
找到了决定推理长度的向量后,接下来需要寻找哪些模块对过短的推理“负主要责任”,方法也很直观:依次在每一层、每个注意力头上施加减少推理长度方向的扰动,输出长度变化越显著,则当前模块对短推理的贡献越大:
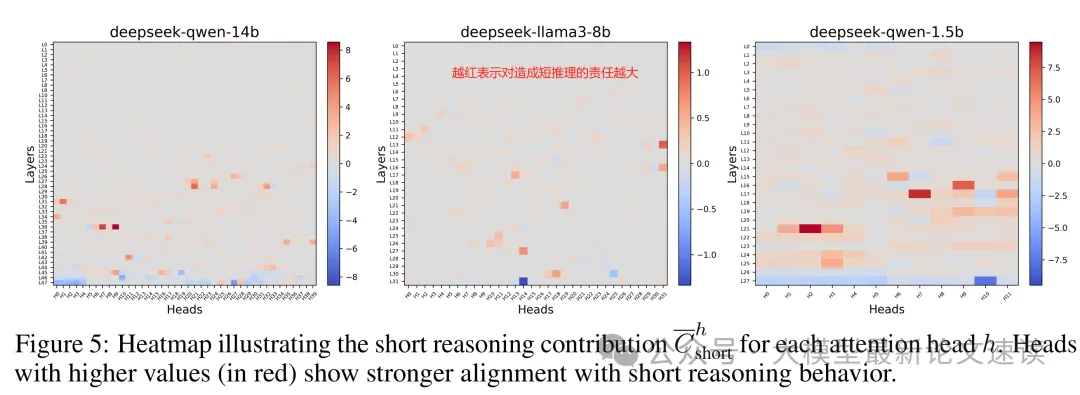
可视化的热力图显示,不到约2%的注意力头具有显著的短推理贡献值(这些头在图中呈现红色高值),并且它们主要集中在 Transformer 的中间层。这带来了一个好消息:我们或许只需对模型很小一部分参数进行干预,就能有效减少过短推理。作者也进行了验证试验:如果临时禁用这些“短推理头”,模型在产生短推理的情况下准确率会有非凡提升,同时整体性能也略有改善
三、编辑注意力头权重
在锁定了主要的短推理注意力头后,研究者提出了 ThinkEdit 方法,即直接修改这些头的权重参数,消除它们推动短推理的倾向。具体地,作者使用了一个投影矩阵,将需要修改的隐向量投影到与上述“推理长度方向”无关的空间中:

上述操作比直接往W中补充方向向量更有效:由于投影空间与V正交,今后无论输入是什么,这个注意力头都不会再产生影响推理长度的分量,而只能贡献其他与此不相关的变化。
实验结果
一、性能测试
在各类数学问题测试集上,应用ThinkEdit后的模型的准确率都有明显提升:
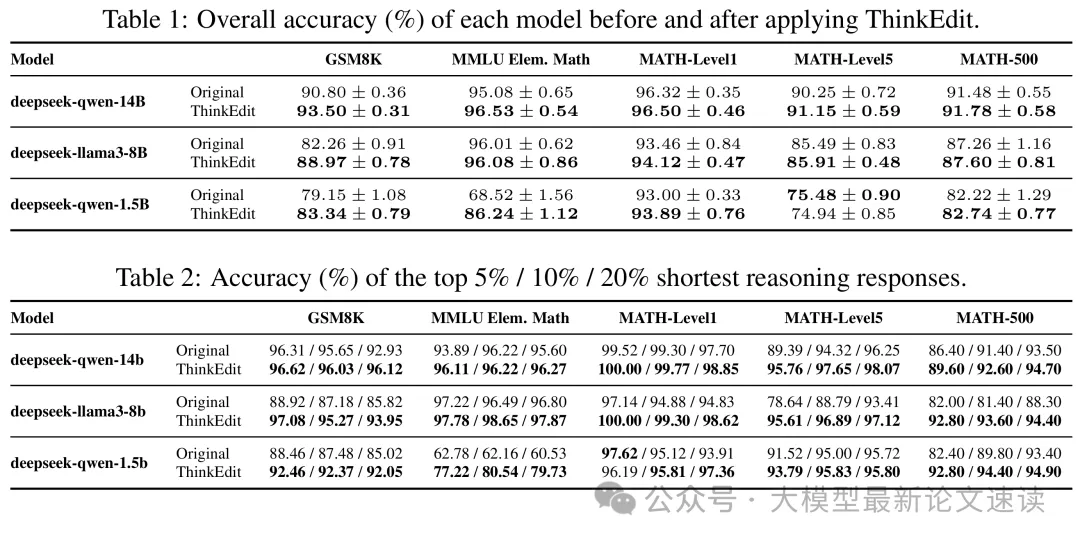
二、推理长度变化
推理长度的下限也如预期明显增加
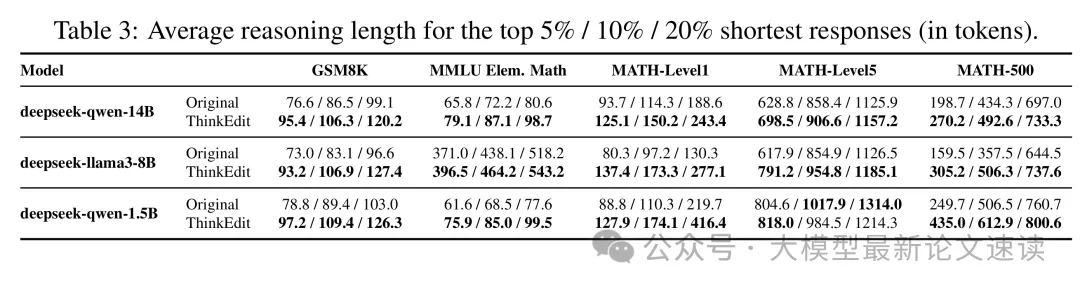


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









