






公众号:大模型最新论文速读
太长不看版:如果希望通过微调注入知识,请先使用原模型对训练集进行数据增强
论文标题
On the generalization of language models from in-context learning and finetuning: a controlled study
论文地址
https://arxiv.org/pdf/2505.00661
作者背景
谷歌DeepMind,斯坦福大学
前言
此前谷歌的一项研究显示,通过监督式微调学习新知识,更容易让大模型产生幻觉,尤其是当训练集中未知、弱已知样本占比较高的时候
论文名称: Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
论文链接: https://arxiv.org/pdf/2405.05904
博客介绍:https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/138695341
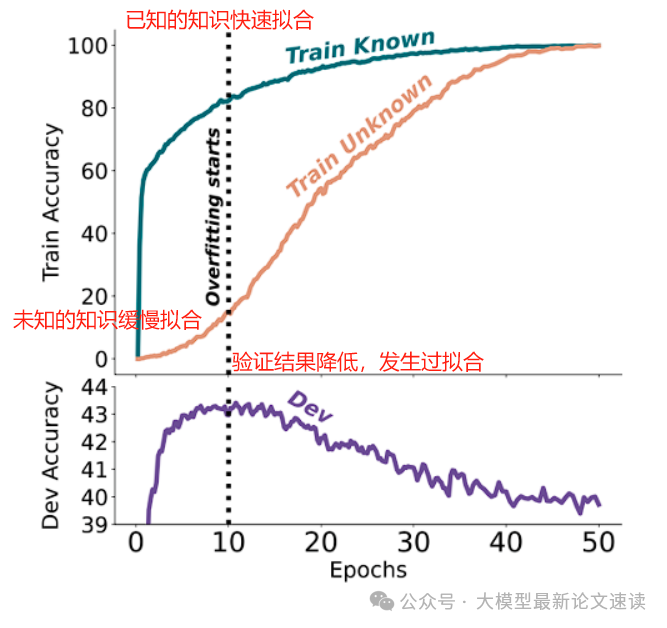
在合理的训练预算下,微调只能让大模型学会少量新知识,随后进入过拟合状态,局限于样本表面模式的拟合
动机
如上文所述,通过微调学习新知识时,大模型的泛化能力出人意料地狭窄,体现为反转诅咒、不会做逻辑推理等;然而微调前的LLM一般都具有很强的上下文学习能力,只需给出少量示例提示就能泛化到新任务(zero/few-shot)
这一割裂的现象让作者产生了对比研究两种知识注入范式的动机,并找到一些提高微调知识注入效果的方法
实验设置
实证研究首先需要严谨地证明推论是否真实存在,设置实验时考虑以下要点:
- 预训练知识干扰:必须确保测试的知识不在预训练语料中,否则无法辨别模型是在泛化微调知识还是在回忆预训练内容
- 公平对比设置:上下文提示和微调是两种截然不同的机制,为了公平比较其泛化表现,必须确保二者接触到的训练信息总量相当。例如,若微调模型训练时看到了N条知识事实,那么评估上下文学习时也应提供同等数量的事实上下文
- 评估泛化类型:泛化是多维度的,表述变化、关系反转、逻辑推演,以及在新类别上的泛化都需要分别设计实验来衡量
一、数据集构建
作者首先精心构建了一批隔离了预训练知识的数据集,确保模型完全依赖于新学到的信息作答:
- 简单关系反转: 若干独立的比较陈述,例如“femp 比 glon 更危险”(都是人造无意义词),模型需要学习“X 比 Y 更… ”的关系,测试时则要求判断反转后的关系是否成立
- 简单三段论: 若干独立的逻辑三段论,例如 “All glon are yomp. All troff are glon.”,它们逻辑上蕴含一个结论“All troff are yomp.”。测试时,模型需要在提供部分前提的情况下,选择正确的推论
- 复杂结构化问题: 一个大型合成基准。将无意义的单词组织成语义网络,然后仿照维基百科文章、QA对话生成与实体、属性、层级关系相关的语料,共包含2200篇长度不一的文档,并从表述重述、关系反转、三段论推理、类比泛化四个角度构建测试问题
- 表述重述: 对训练语句的改写提问(不改变关系方向),用于验证模型是否记住了知识点本身
- 关系反转: 如训练知道“X 属于 Y”,测试问“Y 是否包含 X”
- 三段论推理: 给出两个已学事实的组合推导新的结论
- 类比泛化: 某个类别的知识在训练中只给了一条,其余相关事实全在测试中提出
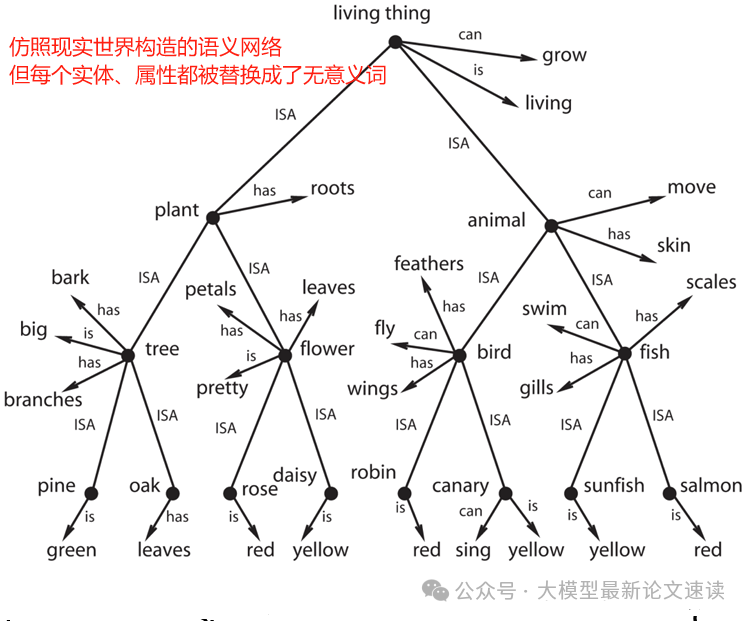
为了排除回答模式的干扰,只关注模型知识利用能力,作者在测试阶段,通过模型对各选项续写的概率来判断模型倾向,其中错误选项都是精心挑选干扰项(比如在训练集中存在,但与该问题无关)
二、测试对象
基于Gemini 1.5 Flash模型,构造4种测试对象:
- Pretrained: 未经任何调整的原始模型,评估zero-shot能力
- Finetuning: 使用上述合成数据集进行微调
- In-Context Learning: 对于小型数据集(简单反转/三段论),把全部训练数据写入上下文并要求模型作答;大型数据集(语义层次基准),通过随机抽样与分段提示来降低上下文长度
- Augmented Finetuning: 先利用ICL生成额外的训练示例,再将这些示例用于微调模型,具体包括两种粒度的数据增强:
- 局部增强: 逐句地让模型对每条训练数据进行推理,生成其等价重述或蕴含推论
- 整体增强: 让模型针对某个主题的全部训练数据,生成更深层次的推论,把这些复杂推理产物也并入训练数据
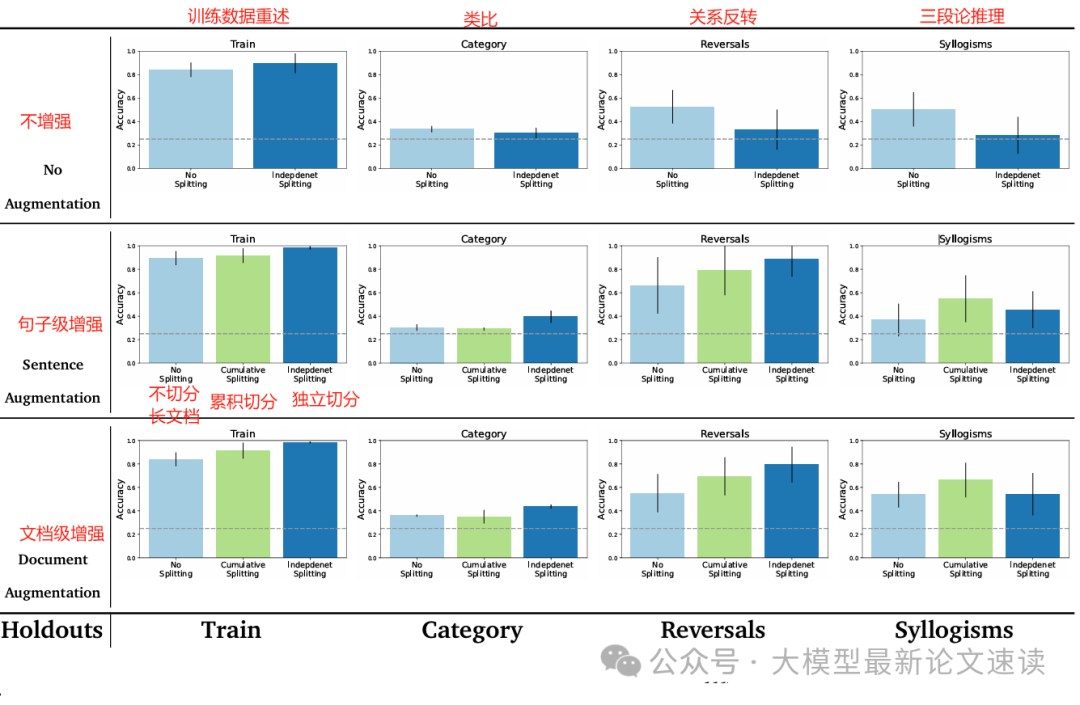
此外,Augmented Finetuning还将长文档按句拆成独立样本进行微调训练,从而打乱原有句子间的相关性
实验结果
一、简单关系反转与三段论
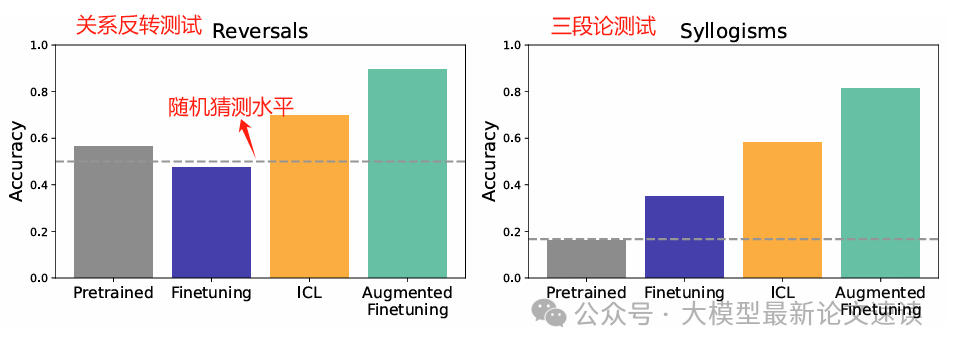
在关系反转任务中,微调模型的准确率接近随机猜测,也低于预训练模型,说明知识注入失败;上下文学习(ICL)表现优异,通过数据增强后的微调模型性能显著提升(注:在“反转诅咒”的原始论文中,微调模型的准确性几乎为0,而此处却有相对较高的得分,可能是因为无意义的人造词汇更“独立”,更不容易引起幻觉,所以微调时具备一定的泛化性)
在三段论推理任务中,微调后的模型效果更好,但也低于ICL的表现;而通过数据增强后的微调模型,性能显著提升
二、复杂结构化问题
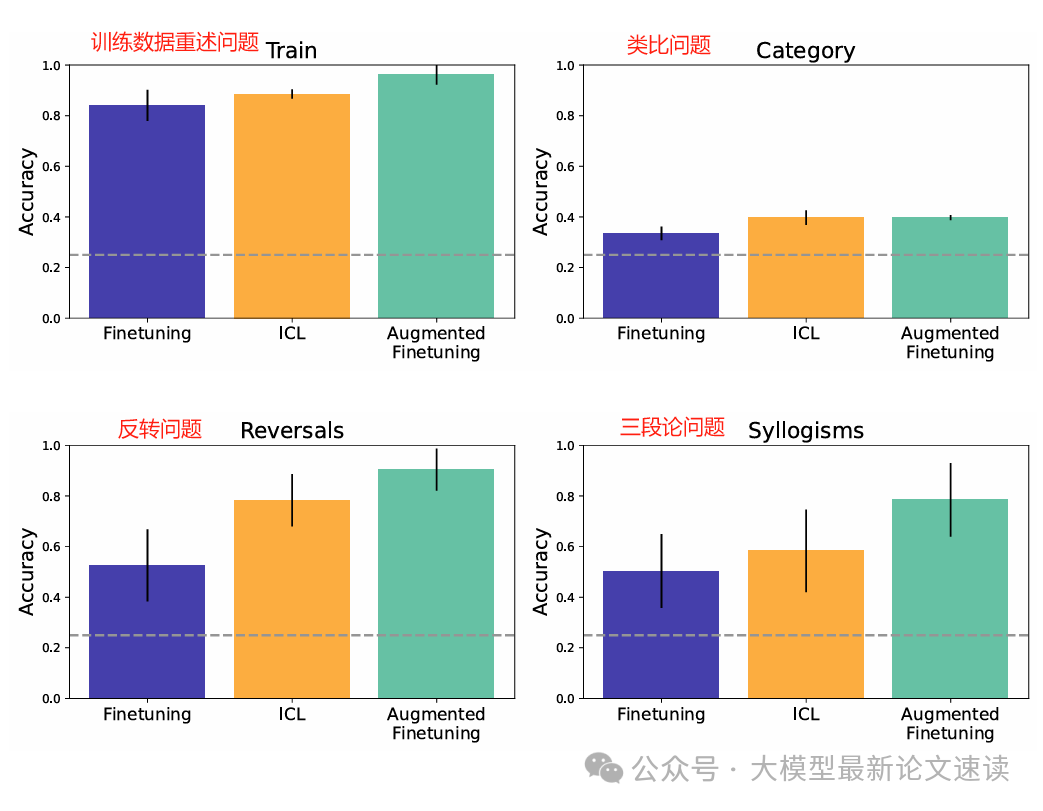
ICL在多种泛化任务中表现优越,尤其是在关系反转和三段论推理任务中;微调模型在表述重述任务中表现良好,但在关系反转和推论任务中表现有限;通过数据增强后,微调模型的性能明显提升
三、微调时长文档拆分的影响
作者在ICL时为了避免上下文过长对数据进行了拆分,具体包含:
- 累积切分: 每句话与其对应的上文作为样本的输入
- 独立切分: 每句话单独作为样本的输入
而后意外地发现,微调时对长上下文进行拆分也能提高最终性能:
总结
上下文学习在推理时调动了模型的内部知识和即时计算能力,展现出更强的灵活泛化;而直接微调往往局限于训练观察到的模式,泛化较僵硬。不过,通过让模型“自我思考”生成额外训练样本后,这种差距可以在很大程度上被弥补。
为什么微调很容易过拟合?我们可以回顾自回归大模型在各个训练阶段中的学习任务:
- 预训练/继续预训练: 续写任务,从海量的无监督语料中,学习语义共现关系
- 微调: 续写任务,从专门构造的有监督语料中,学习特定问题的答案,以及回答模式
- 强化学习: 偏好学习,在设定好的环境中探索出最高奖励分的结果(DPO作为特殊实现方式,忽略)
可见微调的学习信号最少,并且任务难度最大,因此在训练过程中很容易过拟合次要的训练目标(回答模式)
而本文对提高微调模型泛化能力的建议,一方面是通过蕴含推理减少“弱已知”的知识,另一方面便是通过数据增强,尽可能地让训练集中的各种模式更均匀,从而延迟过拟合的发生,让模型学会更多知识
值得注意的是,尽管本文的实验结果表明数据增强后的微调模型效果很好,但它仅仅是针对于“复述”、“反转”、“推论”、“类比”这几个过拟合特定表现做了专项优化,是一种“治标不治本”的行为,不能因此断定完全解决了微调的过拟合问题,实际上可能还有其他过拟合表象,甚至是隐式特性
不过考虑到真实业务场景下的资源限制、老板硬性要求,此项工作也很有现实价值:为微调知识注入提供了一个非常关键的建议


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









