






写在前面:没有套一层sql解决不了的问题,如果有,那就两层。
1.如图所示
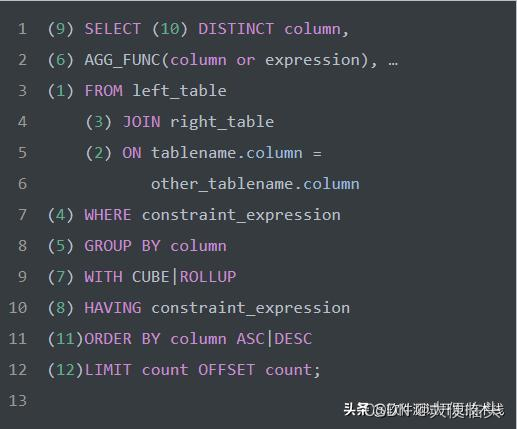
2.解释 它们的执行顺序如下:
1.FROM和JOIN子句:FROM或JOIN会第一个执行,确定一个整体的数据范围。
2.ON子句:用于指定连接条件。
3.WHERE子句:在确定了数据来源后,WHERE语句将在这个数据源中按要求进行数据筛选,并丢弃不符合要求的数据行。
4.GROUP BY子句:如果你用了GROUP BY分组,那GROUP BY将对之前的数据进行分组,统计等,并将结果集缩小为分组数。
5.WITH CUBE或ROLLUP子句:用于生成超级组。
6.HAVING子句:如果你用了GROUP BY分组,HAVING会在分组完成后对结果集再次筛选。
7.SELECT子句:在确定结果之后,SELECT用来对结果列简单筛选或计算,决定输出什么数据。
8.DISTINCT子句:如果数据行有重复,DISTINCT将负责排重。
9.ORDER BY子句:在结果集确定的情况下,ORDER BY对结果做排序。
10.LIMIT子句:最后执行LIMIT子句以限制SELECT语句返回的行数。
这些子句可以帮助您构建复杂的查询来获取所需的信息。您可以根据需要选择使用哪些子句。
3.关于WITH CUBE或ROLLUP子句。这些子句用于生成超级组,它们可以帮助您更深入地分析数据。
WITH CUBE子句用于生成所有可能的组合。例如,如果您按国家/地区和城市对数据进行分组,那么WITH CUBE子句将生成所有国家/地区和城市的组合,以及每个国家/地区的总计和整个结果集的总计。
下面是一个简单的例子,它使用WITH CUBE子句对employees表中的员工按国家/地区和城市进行分组,并计算每个组的员工数量。
SELECT country, city, COUNT(*) FROM employees GROUP BY country, city WITH CUBE;
在这个例子中,我们首先选择了country和city列,然后使用COUNT函数计算每个组的员工数量。然后,我们使用GROUP BY子句按country和city列对结果集进行分组,并使用WITH CUBE子句生成所有可能的组合。
与此类似,ROLLUP子句用于生成分层汇总。例如,如果您按国家/地区和城市对数据进行分组,那么ROLLUP子句将生成每个国家/地区的总计和整个结果集的总计。
下面是一个简单的例子,它使用ROLLUP子句对employees表中的员工按国家/地区和城市进行分组,并计算每个组的员工数量:
SELECT country, city, COUNT(*) FROM employees GROUP BY country, city WITH ROLLUP;
在这个例子中,我们首先选择了country和city列,然后使用COUNT函数计算每个组的员工数量。然后,我们使用GROUP BY子句按country和city列对结果集进行分组,并使用WITH ROLLUP子句生成分层汇总。
WITH CUBE和ROLLUP子句可以帮助您更好地组织查询结果,并对数据进行更深入的分析。
4.起来和不带 with cube差不多是吧,看下面。
WITH CUBE和ROLLUP子句与不带它们的GROUP BY子句有一些不同。当您使用GROUP BY子句时,它只会生成查询中指定的分组。但是,当您使用WITH CUBE或ROLLUP子句时,它们会生成额外的分组,以帮助您更深入地分析数据。
例如,如果您按国家/地区和城市对数据进行分组,那么GROUP BY子句只会生成每个国家/地区和城市的组合。但是,如果您使用WITH CUBE子句,它还会生成每个国家/地区的总计和整个结果集的总计。类似地,如果您使用ROLLUP子句,它还会生成每个国家/地区的总计和整个结果集的总计。
因此,虽然WITH CUBE和ROLLUP子句与不带它们的GROUP BY子句在某些方面类似,但它们提供了额外的功能,可以帮助您更深入地分析数据。















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









