






1、数据的爬取用到Python的Scrapy框架、Selenium、Xpath解析库等相关技术。
2、数据的存储用到Hadoop集群的HDFS,该数据库免费开源易于使用、且性能出色、方便后期存储大量数据和进行数据的提取处理。
3、数据的清洗用到了Hadoop集群中的MapReduce编程模型,利用MapReduce进行数据清洗可以大大提高数据的质量和准确性,为后续的数据分析和应用提供可靠的基础。
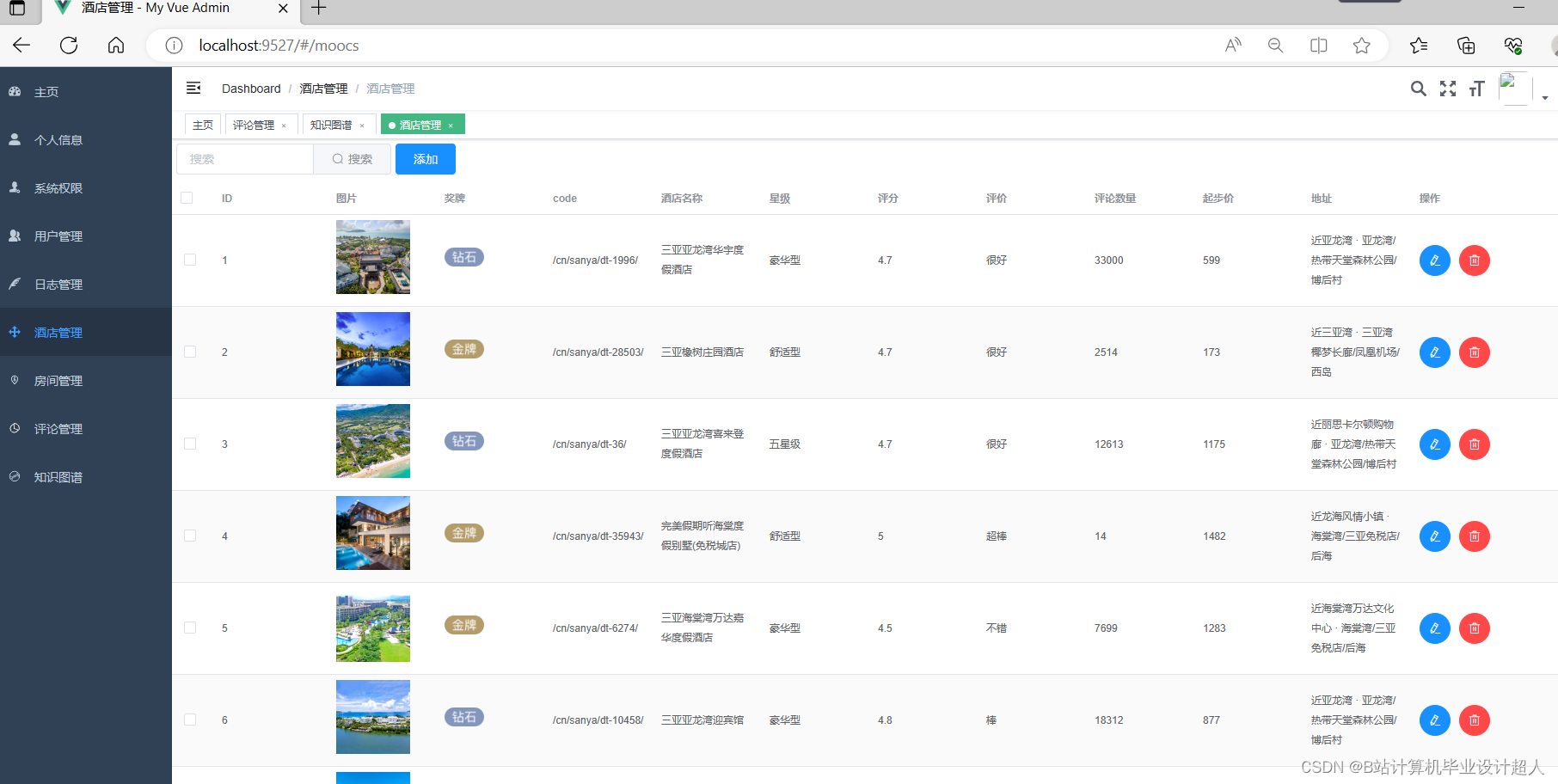
4、数据分析用到Hadoop集群的Hive数据仓库,操作接口采用类SQL语法,提供快速开发的能力。
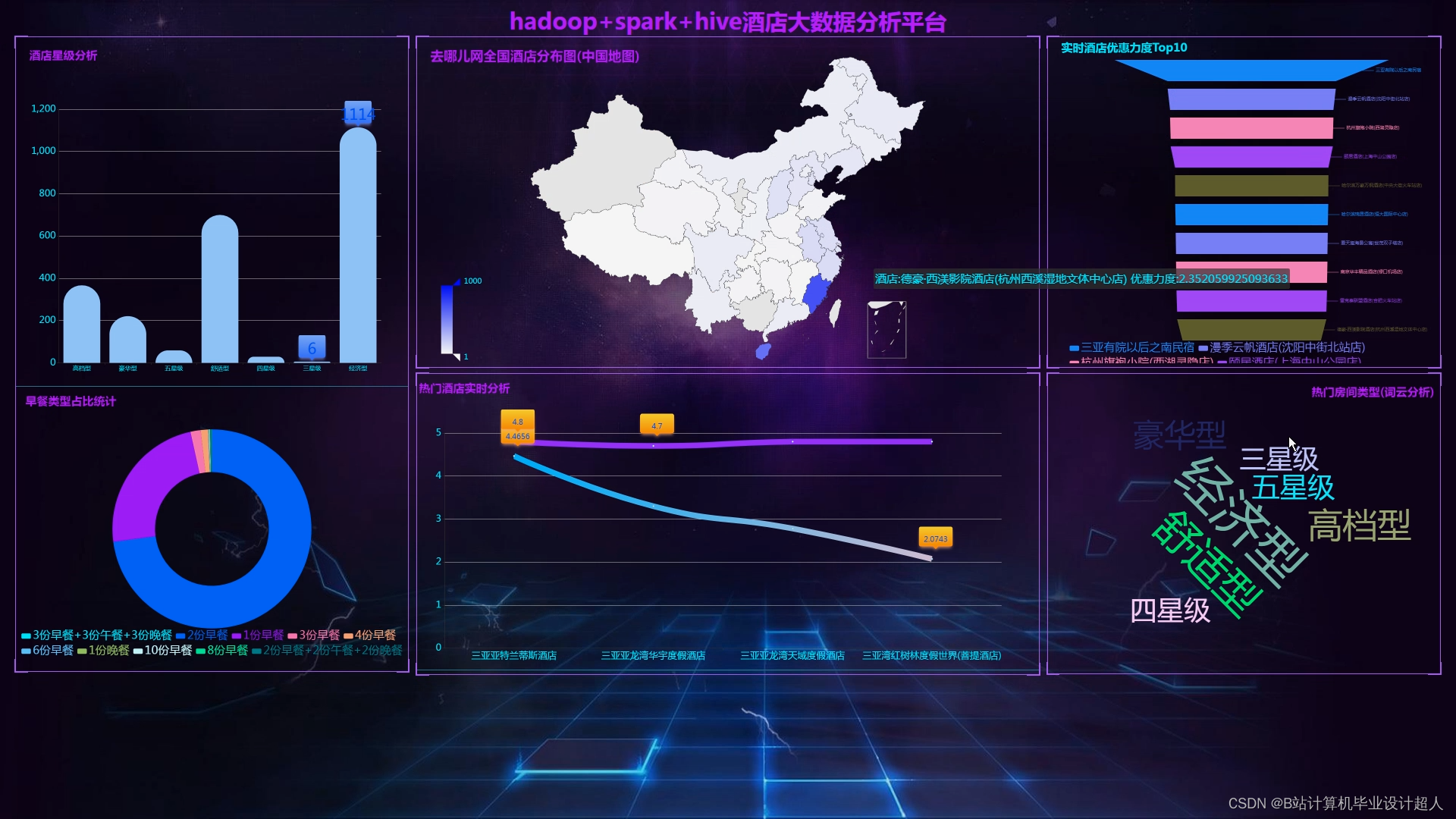
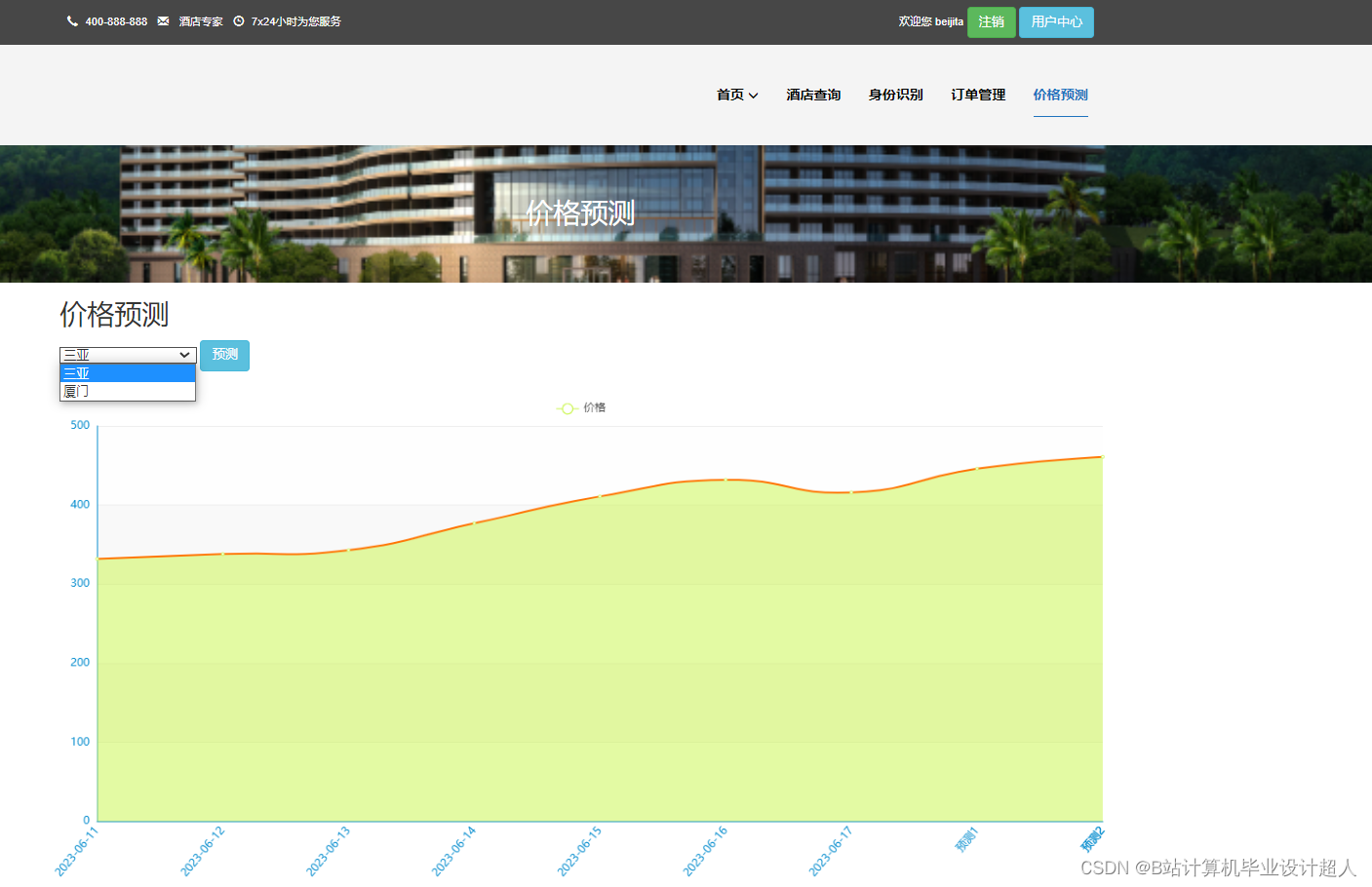
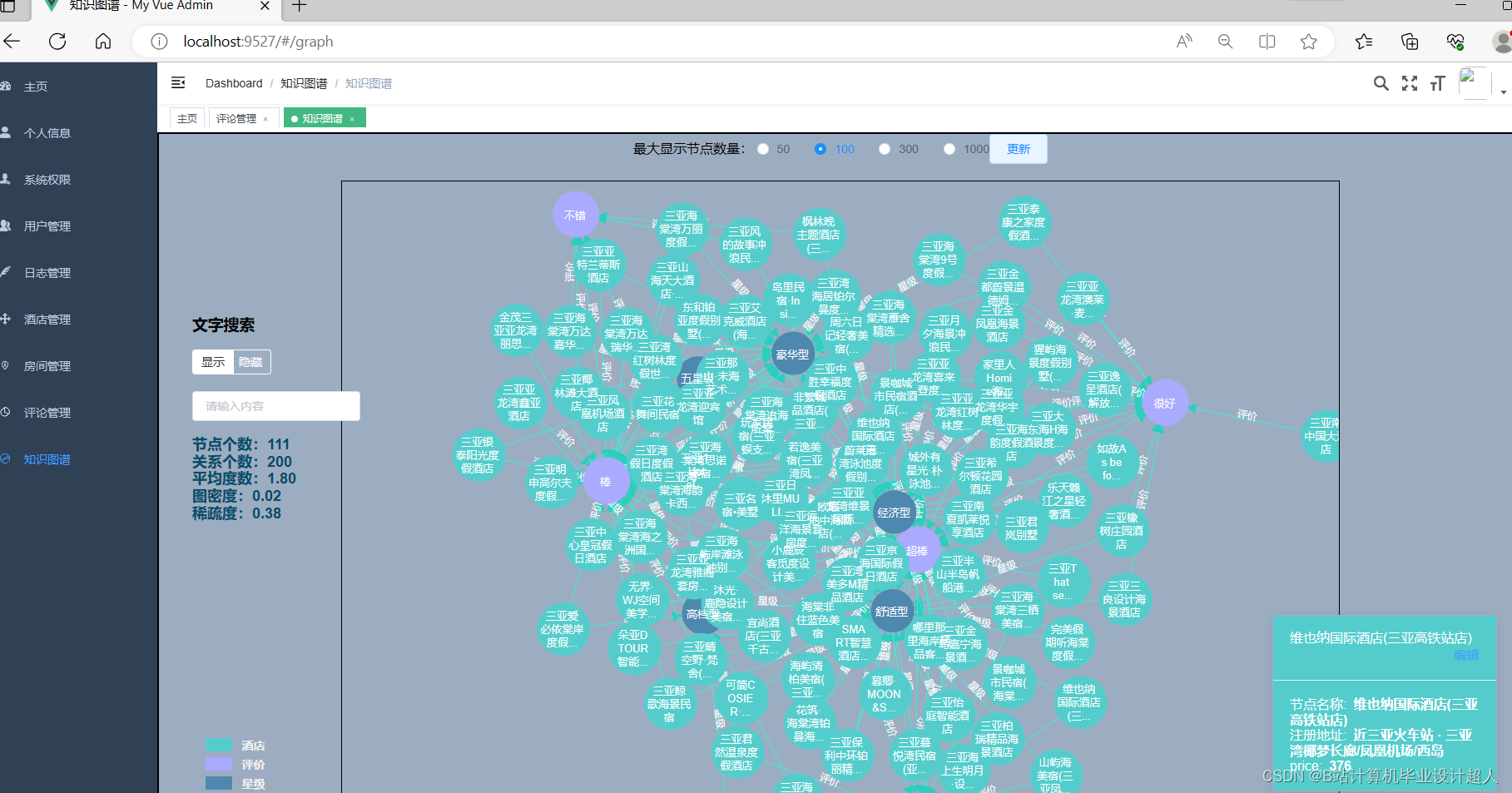
5、数据的可视化利用HTML、CSS和JavaScript等前端技术,引入ECharts图表库设计各类图表。
————————————————


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









