







数据结构Java实现
java和c++最大的不同就在于java没有指针,对于一个c++程序员来说,没有指针,程序怎么运行?
其实,java只是摆脱了显式表露的指针,指针依旧以存储地址的形式埋藏在程序的深处,有时甚至可以说,在java中,所有东西都是指针面、,这句话虽然不是百分之百的正确,但是也差不多.
一、数据结构涵盖的内容:

程序包含的四个要素:
数据结构
算法
程序设计方法
编程语言
(1)树的基础知识:
树的递归定义:
一棵树由称作根(root)的结点r以及0个或多个非空的(子)树T1,T2,T3......组成,这些子树中每一颗的根都来自根r的一条有向边(Edge)所连接。
树是一种“一对多”的数据结构,是n(n≥0)个结点的有限集,其中n=0时称为空树

树满足的一些性质和概念
1:n>0时,根结点唯一
2:n>1时,除去根结点的其他结点构成若干个互不相交的有限集T1,T2...,其中每一个集合又是一棵树,称为根的子树
3:结点拥有的子树数称为结点的度(Degree),度为0的结点称为叶子结点
4:树的度是树内各结点的度的最大值
5:结点的层数是从根开始定义起,根为第一层,根的孩子是第二层,以此类推。树中结点的最大层次称为树的深度(Depth)或高度
6:如果各子树看成从左至右不可互换的,则称为有序树,否则为无序树
7:森林是互不相交的树的集合,某个结点的子树可以看做是森林
二叉树的定义:每个结点最多有两个子树的树结构。通常子树被称作“左子树”和“右子树”
<1> 二叉树满足的一些性质和概念
1:二叉树不存在度大于2的结点
2:左右子树是有顺序的,即使某结点只有一棵子树,也要区分它是左子树还是右子树
3:根据(2)所说,二叉树具有五种基本形态:空二叉树、只有一个根节点、只有左子树、只有右子树、左右子树都有
4:二叉树第i层上至多有2^(i-1)个结点(i≥1)
5:深度为k的二叉树至多有2^k - 1个结点(k≥1),此时为满二叉树
6:对任何一棵二叉树T,如果其叶子结点数为n0,度为2的结点数为n2,则n0 = n2 + 1。这个的推导:设结点数为n,可以知道结点间连接线数为n-1。于是有两个式子:n-1 = n1 + 2*n2 和 n = n0 + n1 +n2,联合解出n0 = n2 + 1
7:具有n个结点的完全二叉树的深度为log2 n向下取整然后加1 => 通过满二叉树2^n - 1可以推出
8:对于完全二叉树,在有左右子结点的情况下,设根结点的编号是n(这个编号从1开始),则左孩子的编号是2n,右孩子的编号是2n+1
特殊的二叉树

1: 斜树:所有的结点都只有左子树或右子树,特点是结点的个数与二叉树的深度相同
2: 满二叉树:所有的分支结点(非叶子)都存在左子树和右子树,并且所有的叶子都在同一层(完全对称,非叶子结点的度一定是2,结点数是2^n - 1)
3: 完全二叉树:对一棵具有n个结点的二叉树按层序编号,如果编号为i(1≤i≤n)的结点与同样深度的满二叉树中的编号为i的结点在二叉树中的位置完全相同,则这棵二叉树称为完全二叉树。(允许在满二叉树中去掉若干个最后的结点,但是存在的结点序号一定与满二叉树位置一致(比满二叉树要求低一点,所以满二叉树一定是完全二叉树,反之则不成立。如果某结点的度为1,则该结点只有左孩子))

二叉树的性质
性质1:在二叉树的第i层上至多有2^(i-1)个结点(i≥1)。(数学归纳法可证)
性质2:深度为k的二叉树最多有2^k-1个结点(k≥1)。(由性质1,通过等比数列求和可证
通项公式:an=a1×q^(n-1); 推广式:an=am×q^(n-m); )
性质3:一棵二叉树的叶子结点数为n0,度为2的结点数为n2,则n0 = n2 + 1。
证:结点总数n = n0 + n1 + n2。设B为分支总数,因为除根节点外,其余结点都有一个分支进入,所以n = B + 1。又因为分支是由度为1或2的结点射出,所以B = n1 + 2n2。综上:n = n0 + n1 + n2 = B + 1 = n1 + 2n2 + 1,得出:n0 = n2 + 1。
性质4:具有n个结点的完全二叉树的深度为floor(log2n) + 1 。eg:左图:n=8 ,log 2 8=3 floor(log2n) + 1 =4,深度为4。(log函数中的2为底)
<2> 堆的概念
严格来讲,堆有不同的种类,但是我们在算法学习中,主要用的还是二叉堆,而二叉堆有最大堆和最小堆之分。
最大(最小)堆是一棵每一个节点的键值都不小于(大于)其孩子(如果存在)的键值的树。大顶堆是一棵完全二叉树,同时也是一棵最大树。小顶堆是一棵完全完全二叉树,同时也是一棵最小树。
需要注意的问题是:堆中的任一子树也还是堆,即大顶堆的子树也都是大顶堆,小顶堆同样。
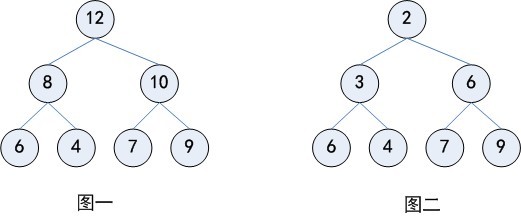
如图一为大顶堆,图二为小顶堆
首先我们从上图中可以看出,由于堆是一棵完全二叉树,那么我们可以得出堆的如下性质:
(1). 堆的插入和删除操作,运行时间为 O(logn),n 为树上结点的个数
简单证明:
假设该二叉树总共有x层,那么很明显当该二叉树为满二叉树的时候,插入和删除耗费的时间是最长的,那么则有:
2^x - 1 = n;
在最坏的情况下,我们插入一个元素的时候,是从第一层遍历到第n层(反之也一样),那么我们最多要进行的操作次数即为树的深度,而树的深度x = log(2)(n+1)(表示以2为底,以n+1为真数的对数),忽略常数,那么我们就求得插入时的最坏时间复杂度则为O(logn)级别。
删除与插入同理,删除时需要注意的问题就是,删除一个元素之后,需要重新调整堆的结构,使其成为新的堆。
(2).堆可以看成是一棵完全二叉树,除最后一层其余每层结点都是满的。
堆的插入和删除操作实现:
(1).首先我们看堆的插入操作:
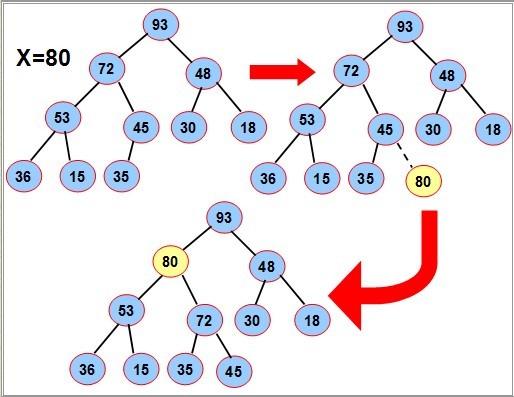
图转自http://blog.csdn.net/cdnight/article/details/11650983/
如上图所示,是一个大根堆的插入演示,插入的数据元素为80,一开始的时候,我们将待插入的数据元素接至堆的末尾,然后再不断向上提升直至没有大小颠倒为止。
我们以上图为例简述堆插入元素的过程:
一开始的时候,元素80和其父亲节点比较,发现其大于父亲节点,因此要上溢,将元素80与其父亲节点进行交换,交换后再重复上述过程,发现元素80仍然比其父亲节点大,继续上溢,将元素80与其父亲节点进行交换,然后再将其与父亲节点比较,发现此时小于其父亲节点的值,说明此时堆中不再存在大小颠倒了,那么此时元素80找到了它在堆中的位置,插入操作结束。
在实现以上算法分析过程时,我们需要明确的问题是,我们不使用指针来表示二叉树,而是用数组存储(因为在这里的堆是完全二叉树的原因,因此用数组实现更简单,而且不存在大量的空间浪费),所以呢,对于每个节点,如果其有左孩子和右孩子的话,那么:
(1).左孩子节点的编号是其自身节点编号 * 2 + 1;
(1).右孩子节点的编号是其自身节点编号 * 2 + 2;(编号是指其用数组中存储时的下标)
二叉排序树和堆的区别
在二叉排序树中,每个结点的值均大于其左子树上所有结点的值,小于其右子树上所有结点的值,对二叉排序树进行中序遍历得到一个有序序列。所以,二叉排序树是结点之间满足一定次序关系的二叉树;
堆是一个完全二叉树,并且每个结点的值都大于或等于其左右孩子结点的值(这里的讨论以大根堆为例),所以,堆是结点之间满足一定次序关系的完全二叉树。
具有n个结点的二叉排序树,其深度取决于给定集合的初始排列顺序,最好情况下其深度为log n(表示以2为底的对数),最坏情况下其深度为n;
具有n个结点的堆,其深度即为堆所对应的完全二叉树的深度log n 。
在二叉排序树中,某结点的右孩子结点的值一定大于该结点的左孩子结点的值;在堆中却不一定,堆只是限定了某结点的值大于(或小于)其左右孩子结点的值,但没有限定左右孩子结点之间的大小关系。
在二叉排序树中,最小值结点是最左下结点,其左指针为空;最大值结点是最右下结点,其右指针为空。在大根堆中,最小值结点位于某个叶子结点,而最大值结点是大根堆的堆顶(即根结点)。
二叉排序树是为了实现动态查找而设计的数据结构,它是面向查找操作的,在二叉排序树中查找一个结点的平均时间复杂度是O(log n);
堆是为了实现排序而设计的一种数据结构,它不是面向查找操作的,因而在堆中查找一个结点需要进行遍历,其平均时间复杂度是O(n)。
<3> 冒泡排序
冒泡排序算法運行起來非常慢,但在概念上它是排序算法中最简单的,因此冒泡排序算法在刚开始研究排序技术时是一个非常好的算法.
使用冒泡排序对棒球运动员进行排序
如果又N个队员,并且根据所站的位置从左到右分别给每一个队员进行编号,从0导N-1,
冒泡排序执行如下:
从对呀u你的最左边开始,比较0号位置和1号位置的队员,如果左边的队员(0号)高,就让两个队员交换,如果右边的队员高,就什么也不做,然后右移一个位置,比较1号和2号位置的队员,和刚才一样,如果右边的队员高,则两个队员交换位置,这个排序如下图所示:
以下是要遵循的规则:
1:比较两个队员。
2:如果左边的队员高,则两个队员交换位置,
3:向右移动一个位置,比较下面两个队员。
沿着这个队列照刚才那样走下去,一直比较到队列的最右端,虽然还没有完全把所有队员都排好序,但是最高的队员已经被排在最右端了,这是可以确定的,因为在每次比较两个队员的时候,只要遇到最高的球员就会交换导他的位置,知道最后他到达队列的最右边,这也是这个算法被称为冒泡排序的原因,因为在算法执行的时候,最大的数据项总是“冒泡”导数组的顶端,下图为一趟排序后球员排列情况。

在对所有的队员进行第一堂排序之后,进行了N-1次比较,并且按照队员们的初始位置,进行了最少0次,最多N-1次交换,数组最末端的哪个数据项就此排定,不需要再移动了。
现在重新回到队列的最左端开始第二趟排序,再依次的从左到右,两两比较,并且在适合的时候交换队员的位置,这一次只需要比较到右边第二个队员,因为最高的队员已经占据了最后位置,即N-1号位置,这个规则可以这样描述:
当碰到第一个排定的队员后,就返回到队列的左端开始下一趟排序。
不断执行这个过程,直到所有的队员都已经排定。
冒泡排序的效率
一次次比较,总结起来就是:
9+8+7+6+5=3+3+2+1
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针。
3.对于随机新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
4.对于顺序操作add和remove,linkedList速度未必优于arrayList,因为还有查询的时间。
一.时间复杂度
首先一点关键的是,ArrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random access),它的速度要比LinkedList快。LinkedList中的get方法是按照顺序从列表的一端开始检查,直到另外一端。对LinkedList而言,访问列表中的某个指定元素没有更快的方法了。
假设我们有一个很大的列表,它里面的元素已经排好序了,这个列表可能是ArrayList类型的也可能是LinkedList类型的,现在我们对这个列表来进行二分查找(binary search),比较列表是ArrayList和LinkedList时的查询速度,看下面的程序:
Java代码
import java.util.ArrayList;
import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
/**
* Created by xxx on 2017/9/24.
* Description
*/
public class ArrayOrLinked {
static List<Integer> array=new ArrayList<Integer>();
static List<Integer> linked=new LinkedList<Integer>();
public static void main(String[] args) {
for(int i=0;i<10000;i++){
array.add(i);
linked.add(i);
}
System.out.println("array time:"+getTime(array));
System.out.println("linked time:"+getTime(linked));
System.out.println("-----------------------------------");
System.out.println("array insert time:"+insertTime(array));
System.out.println("linked insert time:"+insertTime(linked));
System.out.println("-----------------------------------");
System.out.println("ArrayList耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList耗时:"+timeList(new LinkedList()));
}
public static long getTime(List list){
long time=System.currentTimeMillis();
for(int i=0;i<10000;i++){
int index=Collections.binarySearch(list, list.get(i));
if(index!=i){
System.out.println("ERROR!");
}
}
return System.currentTimeMillis()-time;
}
public static long insertTime(List list){
long time=System.currentTimeMillis();
for(int i=100;i<10000;i++){
list.add(5000,i);
}
return System.currentTimeMillis()-time;
}
static final int N=10000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return System.currentTimeMillis()-start;
}
}
得到结果:
array time:5
linked time:301
array insert time:17
linked insert time:151
ArrayList耗时:6
LinkedList耗时:4
这个结果不是固定的,但是基本上ArrayList的时间要明显小于LinkedList的时间。因此在这种情况下不宜用LinkedList。二分查找法使用的随机访问(random access)策略,而LinkedList是不支持快速的随机访问的。对一个LinkedList做随机访问所消耗的时间与这个list的大小是成比例的。而相应的,在ArrayList中进行随机访问所消耗的时间是固定的。
这是否表明ArrayList总是比LinkedList性能要好呢?这并不一定,在某些情况下LinkedList的表现要优于ArrayList,有些算法在LinkedList中实现时效率更高。比方说,利用Collections.reverse方法对列表进行反转时,其性能就要好些。
看这样一个例子,加入我们有一个列表,要对其进行大量的插入和删除操作,在这种情况下LinkedList就是一个较好的选择。请看如下一个极端的例子,我们重复的在一个列表的开端插入一个元素: 当然,也有可能arraylist比linkedlist性能好。
static final int N=10000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++) {
list.add(0, o);
}
return System.currentTimeMillis()-start;
}结果如下:
ArrayList耗时:6
LinkedList耗时:4
参考文章来源:http://pengcqu.iteye.com/blog/502676
树的概念参考文章来源:http://www.cnblogs.com/zhuyf87/archive/2012/11/01/2750105.html
二叉排列数和堆的区别参考来源:http://blog.csdn.net/gisredevelopment/article/details/49945785
堆内存和栈内存的比较:http://www.cnblogs.com/whgw/archive/2011/09/29/2194997.html
堆的概念:http://blog.csdn.net/liujian20150808/article/details/50982765
数据结构参考来源:http://www.jianshu.com/p/75425f405c25















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









