







1.哈希函数与哈希表
1.1哈希函数
①哈希函数的输入域是无穷的(in->∞),输出域是相对有限的(MD5(0~2^64-1),SHal(0~2^128-1))。
②哈希函数如果是相同的输入函数,那么输出函数一定也是相同的。-> 哈希函数没有随机的成分。
③对于不同的输入,可能会有相同的输出(哈希碰撞)。
④具有足够的离散性,保证数据分散基本是均匀的。
1.2哈希表
①“abc”--f--> a1--%xx-->13 这样放在13号位,用一个单向链表存储,如果后面13号位又有,继续用单向链表向后存储。
如果存储的单向链表长度过长,那么每次遍历的时候花费太大,因此需要保存单向链表的长度,当长度到达一定值时,就触发哈希表的扩容逻辑。(n个str最多会触发logN次扩容)扩容哈表表中的数据需要重新计算哈希值,总代价O(N*logN),平均单次代价O(logN)。
②离线扩容技术
问题:设计RandomPool结构
设计一种结构,在该结构中有如下三种功能:insert(key):将某个key加入到该结构,做到不能重复添加。delete(key):将原本在结构中的某个key移除。getRandom():等概率返回结构中的任何一个key。要求这些方法的时间复杂度都是O(1)
public class RandomPool {
public static class Pool<K>{
//建立两个map,分别存放key-index和index-key
HashMap<K,Integer> keyIndexMap;
HashMap<Integer,K> indexKeyMap;
int size; //记录当前pool中key的个数 不管时添加还是删除要保证0~size是连续的
public Pool(){
this.keyIndexMap = new HashMap<K,Integer>();
this.indexKeyMap = new HashMap<Integer,K>();
this.size = 0;
}
public void insert(K key){
//先判断map中有没有这个key,没有则添加,有则不添加
if(!this.keyIndexMap.containsKey(key)){
this.keyIndexMap.put(key,this.size);
this.indexKeyMap.put(this.size,key);
this.size++;
}
}
public void delete(K key){ //不能直接删除,数据在一段范围上会出现不连续(有洞),用最后一个数去填要删除的数据
if(this.keyIndexMap.containsKey(key)){
//获得删除key的索引以及最后索引位置的key
Integer deleteKeyIndex = this.keyIndexMap.get(key);
K lastindexKey = this.indexKeyMap.get(--this.size);
//移除key,并在原本key的位置用最后一个key代替
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(deleteKeyIndex);
this.keyIndexMap.put(lastindexKey,deleteKeyIndex);
this.indexKeyMap.put(deleteKeyIndex,lastindexKey);
}
}
public K getRandomKey(){
if (size == 0){
return null;
}
//获取0~size上的随机整数,不包括size(size的位置是下一个key要添加的位置)
Integer randomNum = (int)(Math.random() * size);
return this.indexKeyMap.get(randomNum);
}
}
}
2详解布隆过滤器
布隆过滤器数据结构
BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。
在初始状态时,对于长度为 m 的位(bit)数组,它的所有位都被置为0,如下图所示:
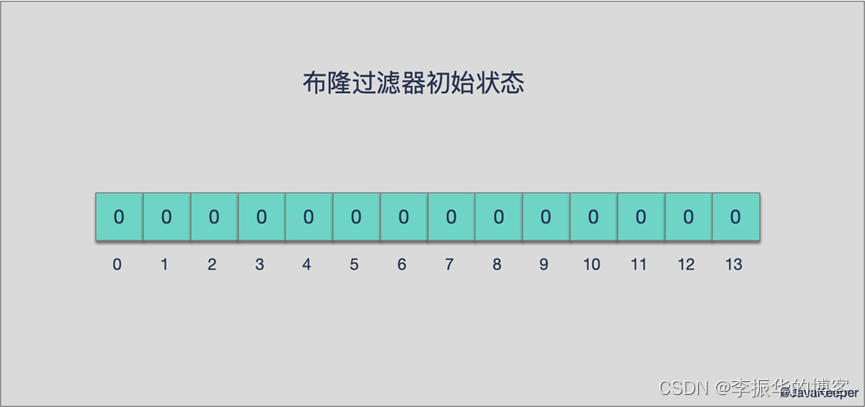
当有变量被加入集合时,通过 K 个映射函数将这个变量映射成位图中的 K 个点,把它们置为 1(假定有两个变量都通过 3 个映射函数)。
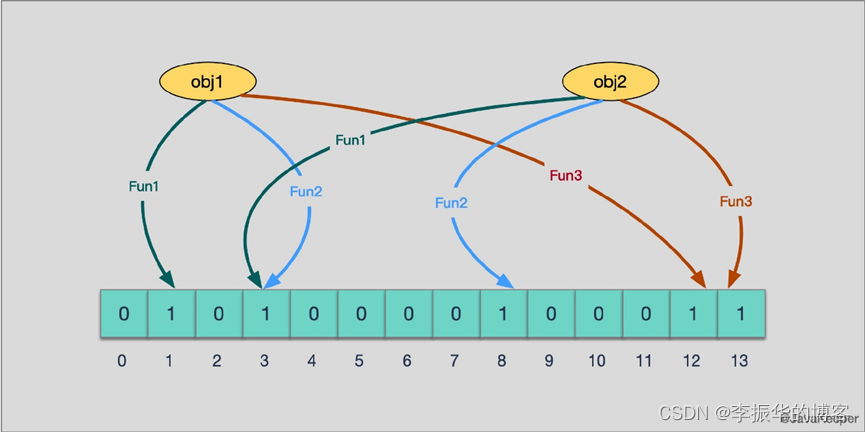
查询某个变量的时候我们只要看看这些点是不是都是 1 就可以大概率知道集合中有没有它了
如果这些点有任何一个 0,则被查询变量一定不在;
如果都是 1,则被查询变量很可能存在
为什么说是可能存在,而不是一定存在呢?那是因为映射函数本身就是散列函数,散列函数是会有碰撞的。
误判率
布隆过滤器的误判是指多个输入经过哈希之后在相同的bit位置1了,这样就无法判断究竟是哪个输入产生的,因此误判的根源在于相同的 bit 位被多次映射且置 1。
这种情况也造成了布隆过滤器的删除问题,因为布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。(比如上图中的第 3 位)
特性
一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
添加与查询元素步骤
添加元素
①将要添加的元素给 k 个哈希函数
②得到对应于位数组上的 k 个位置
③将这k个位置设为 1
查询元素
①将要查询的元素给k个哈希函数
②得到对应于位数组上的k个位置
③如果k个位置有一个为 0,则肯定不在集合中
④如果k个位置全部为 1,则可能在集合中
自定义BloomFilter(网上实现BloomFilter的代码)
public class MyBloomFilter {
/**
* 一个长度为10 亿的比特位
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组
*/
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* 相当于构建 8 个不同的hash算法
*/
private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* 初始化布隆过滤器的 bitmap
*/
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
*
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//计算 hash 值并修改 bitmap 中相应位置为 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
* @param value 需要判断的元素
* @return 结果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一个 hash 函数返回 false 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
/**
* 模拟用户是不是会员,或用户在不在线。。。
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// 添加1亿数据
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" + contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}
已有的条件:n=样本量,p=失误率 (没有删除条件)
布隆过滤器的设计:
所需要的bit长度 (向上取整) m/8才是所需要的内存空间
根据理论的m值和n值计算需要的hash函数个数 (向上取整)
实际的失误率 
//如何获取bit位,通过常规的数据类型拼
public static void main(String[] args) {
int a = 0; //int类型4字节,一共32bit位
int[] arr = new int[10]; //32bit * 10 -> 320bits
//arr[0] int 0~31
//arr[1] int 32~63
//arr[2] int 64~127
int i = 178; //获取第178bit的状态
int numIndex = 178 / 32;
int bitIndex = 178 % 32;
//拿到178位的状态
//这个数右移bitIndex位,想要的位就来到了最右侧
int s = ( (arr[numIndex]) >> (bitIndex) & 1 );
//把178位的状态改成1
// 1 先左移bitIndex位,即该bit位变为1,再与该数字或
arr[numIndex] = arr[numIndex] | (1 << (bitIndex));
//把178位的状态改为0
//先使该为变为1,其他位为0 取反,再与上该数字
arr[numIndex] = arr[numIndex] & (~ (1 << (bitIndex)));
}
3 一致性哈希原理(分布式、虚拟节点)
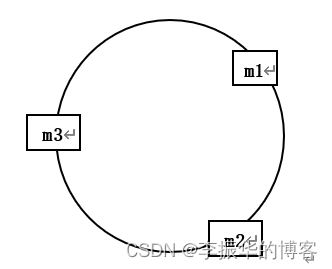
假设有服务器m1,m2,m3,来存储数据。我们根据以下原则进行存储
步骤一:一致性哈希算法将整个哈希值空间(例如MD5)按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环;
步骤二:接着将服务器m1,m2,m3通过Hash函数进行哈希,得到哈希值确定每台服务器在哈希环上的位置。
步骤三:最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器
通过具体例子解析:(MD5 2^64-1)
(1)步骤一:哈希环的组织:
我们将2^64-1想象成一个圆,像钟表一样,钟表的圆可以理解成由2^64个点组成的圆,而此处我们把这个圆想象成由2^64个点组成的圆,示意图如下:

圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^64-1,也就是说0点左侧的第一个点代表2^64-1,我们把这个由2^64个点组成的圆环称为hash环。
(2)步骤二:确定服务器在哈希环的位置:
哈希算法:服务器m1,m2,m3通过MD5哈希函数计算得到哈希值,确定再哈希环上的位置
上述公式的计算结果一定是 0 到 2^64-1之间的整数,那么上图中的 hash 环上必定有一个点与这个整数对应,所以我们可以使用这个整数代表服务器,也就是服务器就可以映射到这个环上,假设我们有m1,m2,m3三台服务器,那么它们在哈希环上的示意图如下:
(3)步骤三:将数据映射到哈希环上:
通过将要存储的数据,经过Hash函数计算得到其哈希值,即可以得到在哈希环上的位置,并在该位置保存数据。
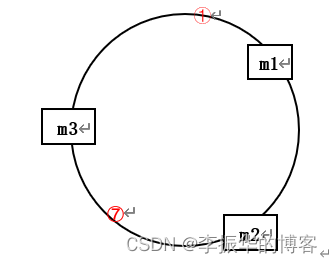
那么,怎么算出数据被保存到那个服务器?我们只要从对应数据的位置开始,沿顺时针方向遇到的第一个服务器就是存放该数据的服务器了。
存在的问题
①在服务器数量较少的时候,哈希域 (也就是上图中的那个环),不一定会被服务器均分
②就算你解决了第一个问题,服务器均分了哈希域,当你再增加服务器的时候,哈希域又注定不会被均分。
上面两个问题是由哈希函数的性质引起的,那么又该如何解决上面的问题呢?
一个方法,虚拟结点技术:也可以根据服务器负载的强弱分配(强的多些虚拟节点,弱的少些)
假设环还是那个环,服务器还是那三台服务器M1,M2, M3,给M1在哈希域环上虚拟出10000个结点,M2也是,M3也是,此时将有30000个结点遍布在环上,归属于M1的10000个结点中应该存放的数据,都存放在M1上。此时哈希域上的结点数量起来了,哈希域也就自然被均分了。
第一个问题解决,当增加服务器数量的时候也是类似的方法,将服务器虚拟出大量的结点,这样就达到了均分的目的。第二个问题也被解决了
关于服务器虚拟出来的节点类似于路由器中的路由表,可以根据路由表找到结点,也可以根据节结点知道,这个结点属于哪一个路由器。
4并查集
问题引出:岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上、下、左、右四个位置相连,如果有一片1连在一起,这个部分叫做一个岛,求矩阵中有多少个岛?
eg:
001010
111010
100100
000000
这个矩阵有三个岛
进阶:如何设计一个并行算法解决这个问题
//获得岛的个数
public static int countIslands(int[][] arr){
if(arr == null || arr[0] == null){
return 0;
}
int N = arr.length; //行
int M = arr[0].length; //列
int res = 0;
for(int i = 0;i < N;i++){
for(int j = 0;j < M;j++){
if(arr[i][j] == 1){ //如果遇到1,就进行传染,岛的个数加一,使遇到的1都变为2
res++;
infect(arr,i,j,N,M);
}
}
}
return res;
}
//时间复杂度O(N*M)
public static void infect(int[][] arr,int i,int j,int N,int M){
if(i < 0 || i >= N || j < 0 || j >= M || arr[i][j] != 1){ //如果越界,或者遇到不是1就返回
return;
}
//使岛元素变为2
arr[i][j] = 2;
//上下左右递归进行
infect(arr, i + 1, j, N, M);
infect(arr, i - 1, j, N, M);
infect(arr, i, j + 1, N, M);
infect(arr, i, j - 1, N, M);
}
并查集集合结构
/**
* 并查集结构
*/
public class UnionFind {
//样本进来,会包一层,叫做元素
public static class Element<V>{
public V value;
public Element(V value){
this.value = value;
}
}
//并查集 里面有必有两个方法 -- 两个集合合成一个 和 判断是否是一个集合
public static class UnionFindSet<V>{
public HashMap<V,Element<V>> elementMap; //样本对应自己的元素表
//key:某个元素 value:该元素的父元素
public HashMap<Element<V>,Element<V>> fatherMap;
//key:某个集合的代表元素 value:该集合的大小
public HashMap<Element<V>,Integer> sizeMap;
public UnionFindSet(List<V> list){
elementMap = new HashMap<>();
fatherMap = new HashMap<>();
sizeMap = new HashMap<>();
//初始化每个map,
for(V value : list){
Element<V> vElement = new Element<>(value);
elementMap.put(value,vElement);
fatherMap.put(vElement,vElement);
sizeMap.put(vElement,1);
}
}
//找 某一个元素 的 头元素
private Element<V> findHead(Element<V> element){
Stack<Element<V>> path = new Stack<>();
while(element != fatherMap.get(element)){
path.push(element);
element = fatherMap.get(element);
}
while (!path.isEmpty()){ //把整个链变成扁平的,即把路径上的元素的父元素直接指向
fatherMap.put(path.pop(),element);
}
return element;
}
//判断a样本和b样本是否是同一个集合
public boolean isSameSet(V a,V b){
if(elementMap.containsKey(a) && elementMap.containsKey(b)){
return findHead(elementMap.get(a)) == findHead(elementMap.get(b));
}
return false;
}
//把样本a和样本b所在的集合合并
public void union(V a,V b){
if(elementMap.containsKey(a) && elementMap.containsKey(b)){
//先找到各自元素对应的头元素
Element<V> ahead = findHead(elementMap.get(a));
Element<V> bhead = findHead(elementMap.get(b));
//然后根据头元素集合的大小,小集合加入大集合,即小的头元素指向大的头元素,大集合头元素的集合大小等于其加小集合的大小
if(ahead != bhead){
Element<V> bigSizeElement = sizeMap.get(ahead) >= sizeMap.get(bhead) ? ahead : bhead;
Element<V> smallSizeElement = bigSizeElement == ahead ? bhead : ahead;
fatherMap.put(smallSizeElement,bigSizeElement);
sizeMap.put(bigSizeElement, sizeMap.get(ahead) + sizeMap.get(bhead));
sizeMap.remove(smallSizeElement);
}
}
}
}
}















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









