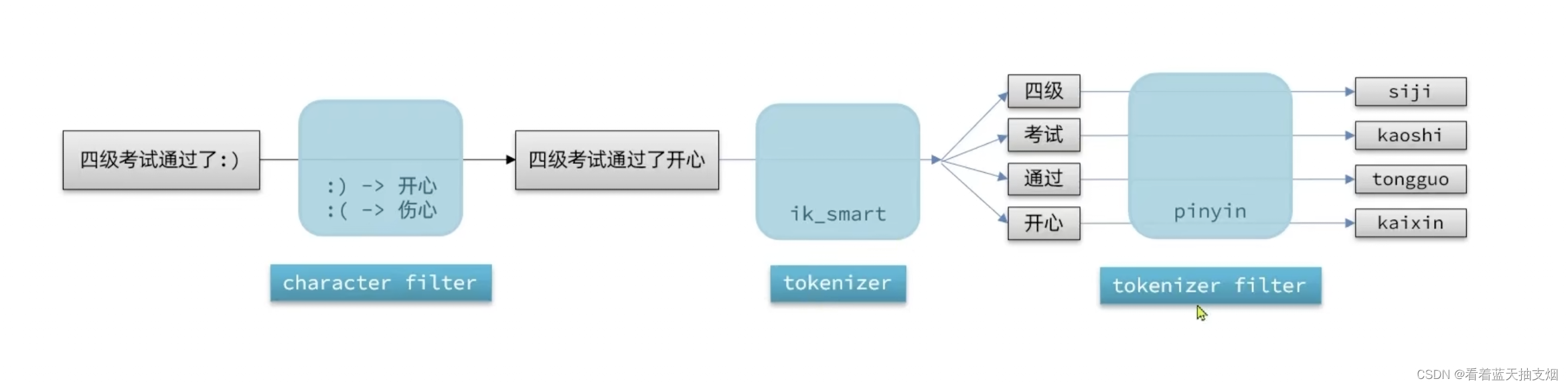
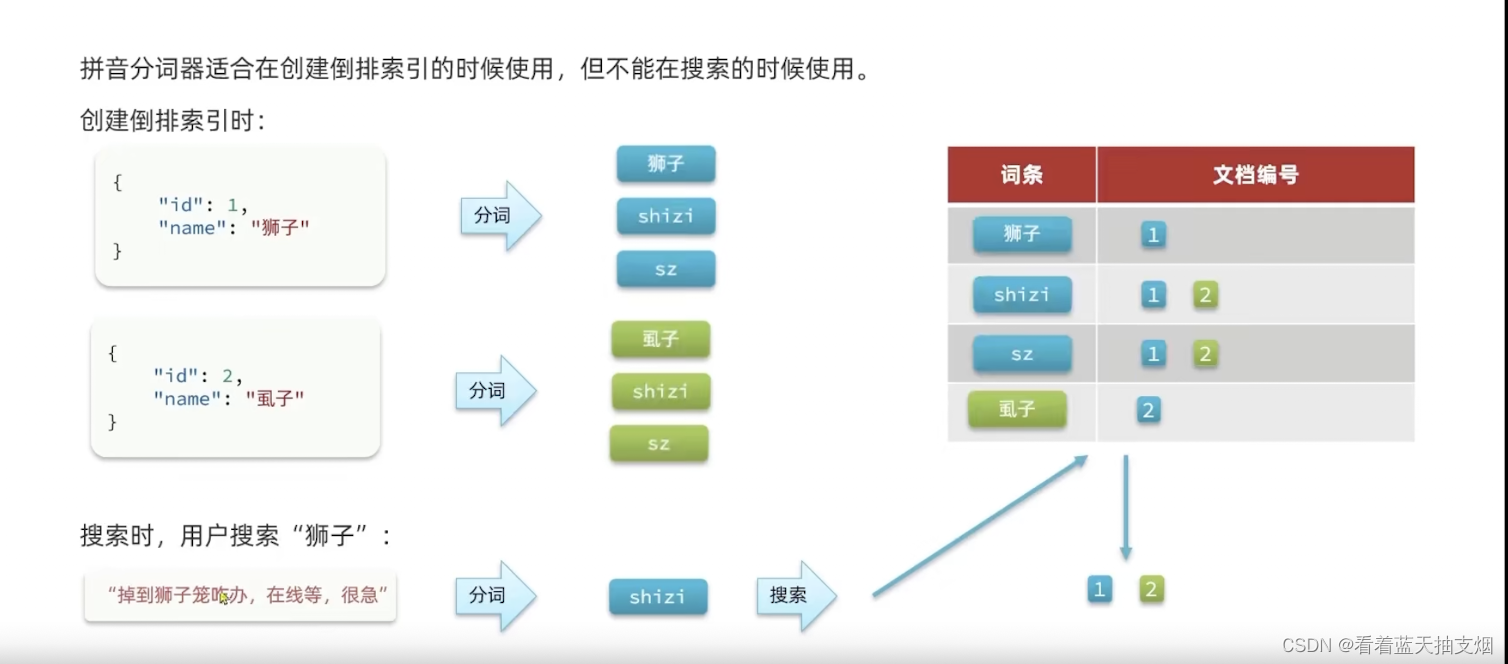
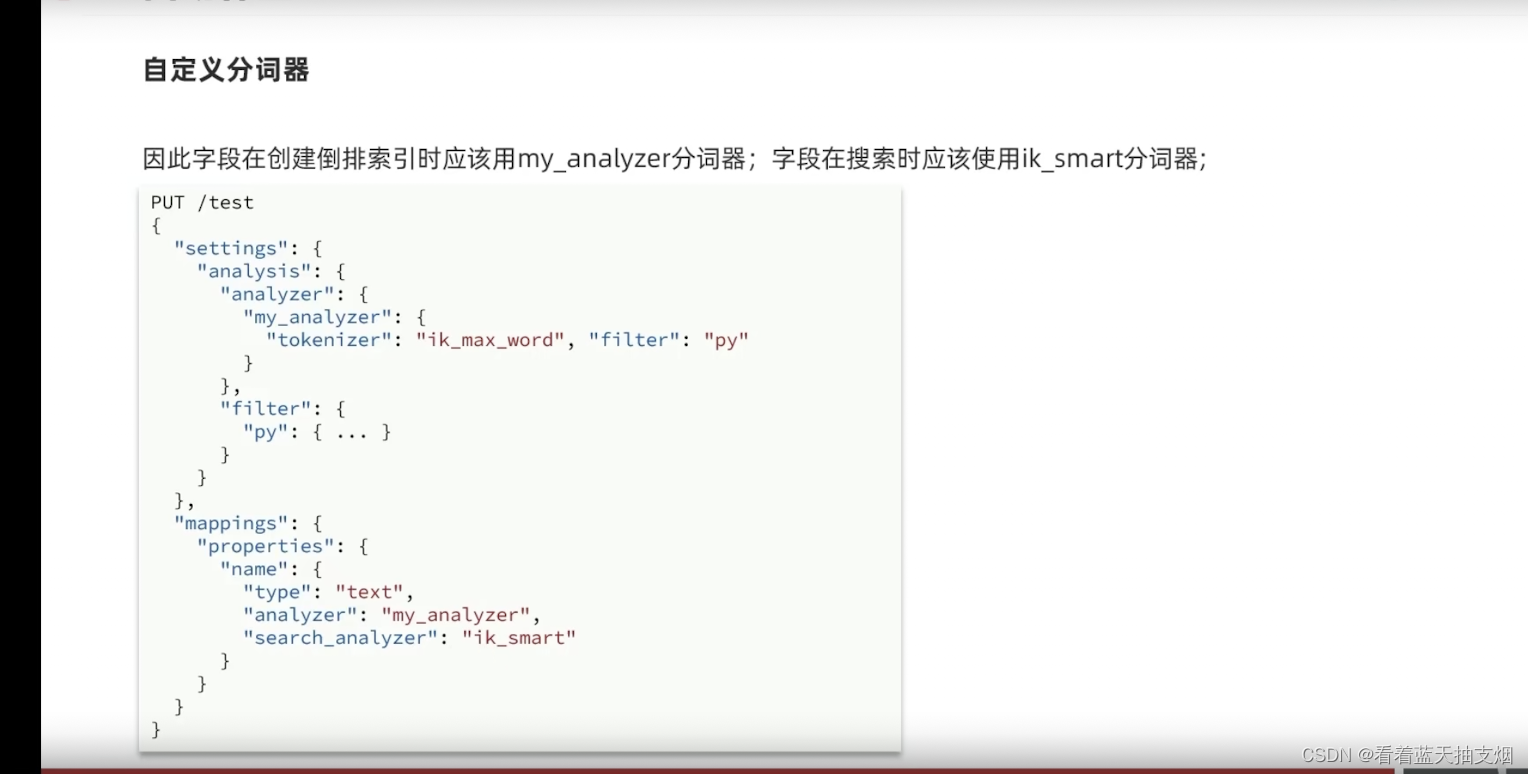
自定义分词词 elasticsearch中分词器(analyzer)的组成包含三部分: character filters : 在tokenizer 之前对文本进行处理,例如删除字符替换字符tokenizer: 将文本按照一定的规则切割成词条(term)。例如keyword就是不分词,还有ik_smarktokenizer-filters: 将tokenizer 输出的词条进一步处理。例如大小写转换,统一次处理,拼音处理等。 自定义分词器语法 自定义分词词的问题 处理自定义分词器的问题 创建索引时,使用拼音分词器 查询文档时,不使用拼音分词器,用ik_max_smart或 ik_smart

























 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






