






1、MapReduce运行过程
MapReduce运行过程具体过程如下图所示:

1.1、对于MapTask的并行度
首先,我们将需要进行计算操作的数据从hdfs中取出,这个过程可能会进行文件切片,在我们编写MR任务的时候,会用到FileInputFormat这个类,对于该类中计算切片大小的方法如下
关键代码
Math.max(minSize, Math.min(maxSize, blockSize));
minSize默认值:1
maxSize为Long.MAX_VALUE可以理解为很大的数
而blockSize,默认情况下是与hdfs中的blockSize大小一致,我们也可以手动设置
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
故我们可以说,MapTask的并行度理论上是由逻辑切片决定的。
值得注意的是,在FileInputFormat类中的getSplits方法中存在以下代码
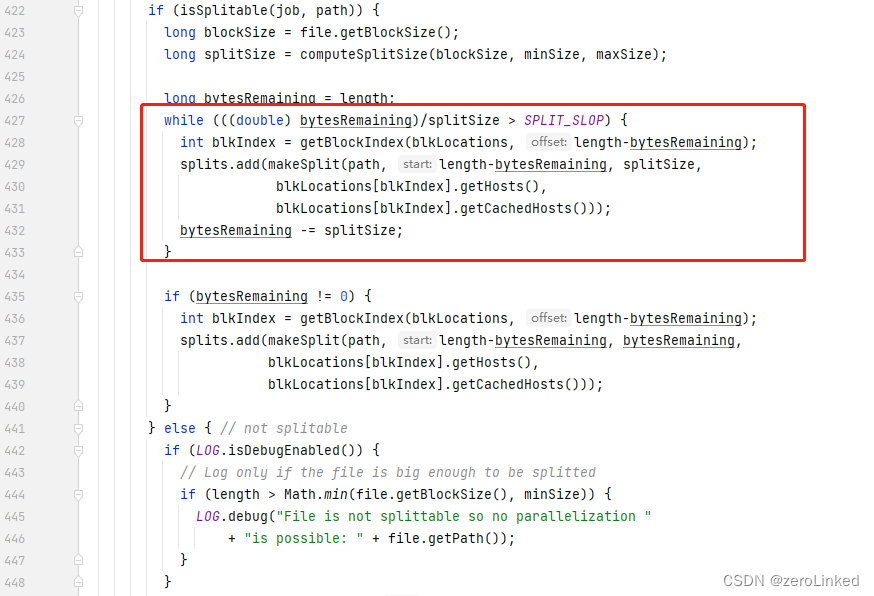
大致意思是,当如果不满足bytesRemaining/splitSize > 1.1这个条件的情况下,最后所剩余的会作为一个切片,即:最后剩下129M的文件的情况下,该文件不会被分为两个切片。
1.2、对于文件切分时候的细节处理
我们默认编写MR的程序的时候,程序是一行一行读的,这会造成一个问题,比如,我们现在有这样一个文件,并对其做词频统计
hello,world,java
spark,flink,hive,hbase
hadoop,spark,flink,java
hello,world
hello,world,java
spark,flink,hive,hbase
hadoop,spark,flink,java
hello,world
假设这个文件很大,切的时候可能其中一个128M只到某一行中间,假如切分成文件A和文件B
文件A
hello,world,java
spark,flink,hive,hbase
hadoop,spark,flink,java
hello,world
hello,world,ja
文件B
va
spark,flink,hive,hbase
hadoop,spark,flink,java
hello,world
这时候最终得到的结果肯定是不正确的,针对这个情况,MapReduce做了优化处理。在MR中,默认使用的InputFormat为TextInputFormat这个类,这个类读取文本时用到LineRecordReader类进行处理,我们可以在初始化方法initialize中看到这样操作

注释上写得很清楚,大概意思就是:
如果是第一个切片,会在第一个切片的最后一行再向下读一行
如果不是第一个切片,默认不读第一行,但依旧会往最后一行的位置再向下读一行
这一操作使得我们对文件数据的读取具有一定的完整性
1.3、环形缓冲区、Spill
在经过分区操作后,数据将会被写入内存的环形缓冲区,其作用是批量收集map结果,减少磁盘IO的影响。环形缓冲区本质是一个数组,存放着key、value的序列化数据和key、value的元数据信息,它是一个抽象概念。
环形缓冲区的默认大小是100MB,当缓冲区到达一定条件(如map task结束或缓冲区数据达到阈值),缓冲区回向磁盘写数据,这个过程被称为spill,也就是溢写。溢写是由单线程完成,每次溢写操作会在磁盘上生成临时文件,如输出结果很大时,会生成多个临时文件,在数据处理结束后对临时文件进行合并(merge)操作。
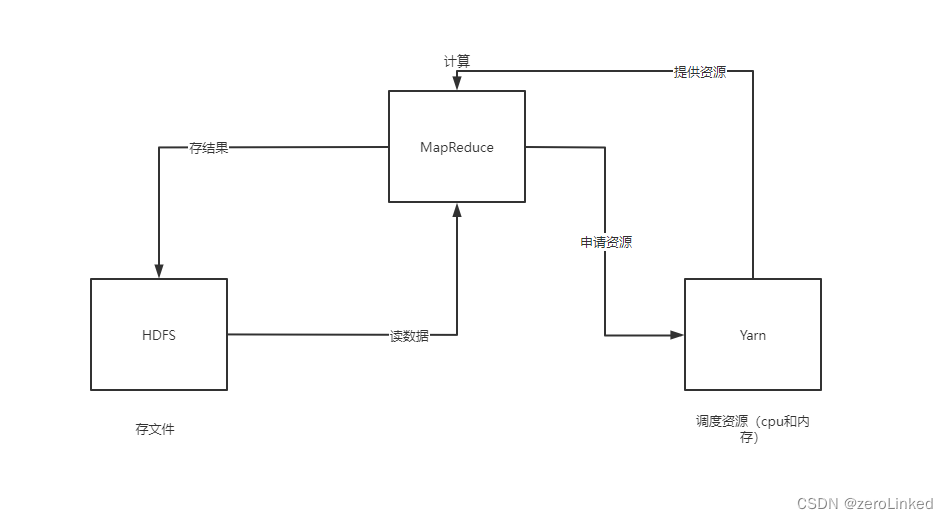
2、Yarn
Hadoop中有三大组件:HDFS、MapReduce、Yarn,三者的关系如下
2.1、yarn的架构
- Yarn是一个主从架构
- ResourceManager
- 接受客户端的任务,并将该任务交给NodeManager去执行
- 划分整个集群的计算资源
- NodeManager
- 执行计算任务
- 资源的提供者
- 定时向ResourceManager汇报资源使用情况,保持心跳
- AppMaster
- 每启动一个任务job,就会启动一个该任务的管理者AppMaster,有多少个任务就会有多少个AppMaster
- AppMaster负责整个任务从提交到结束整个的过程
- Container
- 一个抽象的资源容器,是资源分配的单位,本质上是Java类对象
2.2、yarn执行流程
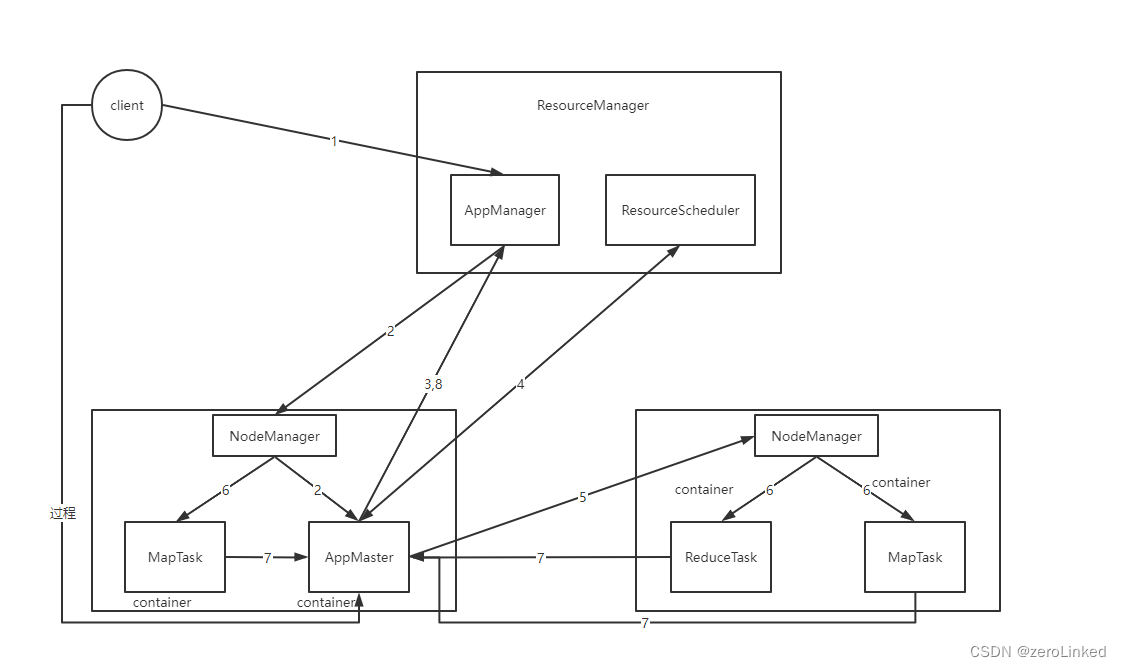
执行流程:
- 1:客户端向RM提交任务请求
- 2:RM在一台NM上分配一个container,然后启动一个appmaster,由appmaster管理任务的执行
- 3:appmaster向RM进行注册
- 4:appmaster向RM申请资源,RM以container列表形式返回资料列表,根据返回列表去对应NM拿资源
- 5:appmaster向对应NM申请资源
- 6:NM根据container开辟资源,appmaster会将maptask和reducetask放在这些资源中运行
- 7:maptask和reducetask运行过程需要将运行状态报告给appmaster
- 8:appmaster将最终执行结果汇报给RM
- 过程:执行信息反馈到客户端
2.3、yarn调度器
客户端向Yarn一次提交多个任务时,Yarn如何去给多个任务分配资源,此时就需要使用调度器,通俗的来讲,调度器就是来规定多个任务如何分配Yarn的资源。
调度器分类
- 队列调度器(FIFO Scheduler):将提交的Job放入一个队列中,先进入的Job会优先得到所有资源,可能会导致某个一个Job占用大部门资源,而且执行时间较长,会影响后期job的运行,所以该调取策略一般不用
- 容量调度器(Capacity Scheduler)
1、Apache Hadoop默认使用的就是该调度器
2、容量调度器是将整个资源划分成多个队列,每一个队列占用一部分资源
3、在提交任务时需要指定你要使用哪一个队列的资源,如果没有指定则使用默认队列
4、容量调度器默认只有一个队列:default队列,如果想要建立其他队列则需要手动来设置
5、执行任务的队列必须是叶子,也就是队列树中最末端队列
6、给队列设置的资源占比都是资源的下限比例,默认最多可以使用%100的全部资源
- 公平调度器(Fair Scheduler)
1、CDH(Cloudera Hadoop)默认就使用该调度器
2、不管来多少job任务,都会对总资源进行平均分配














 3678
3678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









