






0. 引言
前情提要:
《NLP深入学习(一):jieba 工具包介绍》
《NLP深入学习(二):nltk 工具包介绍》
《NLP深入学习(三):TF-IDF 详解以及文本分类/聚类用法》
《NLP深入学习(四):贝叶斯算法详解及分类/拼写检查用法》
《NLP深入学习(五):HMM 详解及字母识别/天气预测用法》
《NLP深入学习(六):n-gram 语言模型》
《NLP深入学习(七):词向量》
《NLP深入学习(八):感知机学习》
《NLP深入学习(九):KNN 算法及分类用法》
《NLP深入学习(十):决策树(ID3、C4.5以及CART)》
《NLP深入学习(十一):逻辑回归(logistic regression)》
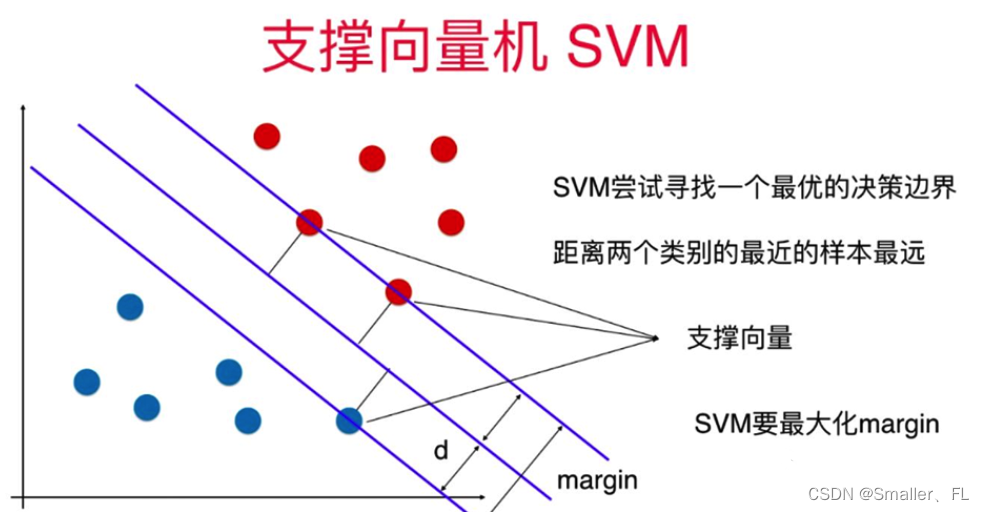
1. 什么是支持向量机
支持向量机(Support Vector Machine, SVM)是一种监督学习模型,主要用于分类和回归分析任务,但最常用于二分类问题。其核心思想是通过构建一个能够最大化类别间隔(margin)的超平面来划分不同类别的数据点。
在二维或三维空间中,超平面是一个线性决策边界,而在高维特征空间中,则是一个多维的分割面。SVM的目标是最小化误分类点到这个超平面的距离(即找到最大间隔超平面),这样不仅可以使得模型具有很好的泛化能力,而且对未知样本的预测更加稳定。
对于非线性可分的数据集,SVM使用核函数(Kernel Trick)将原始输入数据映射到高维特征空间,在这个新的空间中寻找最优的超平面。常用的核函数包括线性核、多项式核、高斯核(径向基函数,RBF)等。
2. 线性 SVM
线性可分支持向量机(Linearly Separable Support Vector Machine)是 SVM 的一个特例,它假设训练数据是线性可分的,即存在一个超平面能够将正类别和负类别的样本完全分开。
以下是线性可分支持向量机的推导过程:
-
假设我们有训练数据集: { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)},其中 x i x_i xi 是输入样本, y i y_i yi 是对应的类别标签(+1 或 -1)。
-
我们的目标是找到一个超平面,表示为 w ⋅ x + b = 0 w \cdot x + b = 0 w⋅x+b=0,其中 w w w 是法向量(weights), b b b 是偏置(bias)。
-
超平面将空间分成两个区域:正类别和负类别。我们希望对于所有的 i i i,如果 y i = 1 y_i = 1 yi=1,则 w ⋅ x i + b > 0 w \cdot x_i + b > 0 w⋅xi+b>0,如果 y i = − 1 y_i = -1 yi=−1,则 w ⋅ x i + b < 0 w \cdot x_i + b < 0 w⋅xi+b<0。
-
SVM 的优化目标是最大化超平面到最近的正类别和负类别样本之间的间隔。这个间隔由超平面到最近的支持向量(支持向量是离超平面最近的训练样本)的距离决定。
-
支持向量到超平面的距离公式是: distance = ∣ w ⋅ x + b ∣ ∥ w ∥ \text{distance} = \frac{|w \cdot x + b|}{\|w\|} distance=∥w∥∣w⋅x+b∣。
-
为了最大化间隔,我们需要最小化 ∥ w ∥ \|w\| ∥w∥,即最小化 1 2 ∥ w ∥ 2 \frac{1}{2} \|w\|^2 21∥w∥2(这个因子出现是为了方便后续求导)。
-
SVM 的目标函数为:
min 1 2 ∥ w ∥ 2 \text{min} \quad \frac{1}{2} \|w\|^2 min21∥w∥2
约束条件为:
y i ( w ⋅ x i + b ) ≥ 1 , for all i = 1 , 2 , . . . , n y_i(w \cdot x_i + b) \geq 1, \quad \text{for all} \ i = 1, 2, ..., n yi(w⋅xi+b)≥1,for all i=1,2,...,n -
利用拉格朗日乘子法,我们将目标函数和约束条件转化为拉格朗日函数:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i [ y i ( w ⋅ x i + b ) − 1 ] \mathcal{L}(w, b, \alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^{n} \alpha_i \left[ y_i(w \cdot x_i + b) - 1 \right] L(w,b,α)=21∥w∥2−i=1∑nαi[yi(w⋅xi+b)−1]
其中, α i \alpha_i αi 是拉格朗日乘子。 -
对 L \mathcal{L} L 分别对 w w w 和 b b b 求偏导数并令其等于零,得到:
w = ∑ i = 1 n α i y i x i w = \sum_{i=1}^{n} \alpha_i y_i x_i w=i=1∑nαiyixi
∑ i = 1 n α i y i = 0 \sum_{i=1}^{n} \alpha_i y_i = 0 i=1∑nαiyi=0 -
将以上结果代入拉格朗日函数,得到拉格朗日对偶问题:
max ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j ( x i ⋅ x j ) \text{max} \quad \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) maxi=1∑nαi−21i=1∑nj=1∑nαiαjyiyj(xi⋅xj)
约束条件为:
α i ≥ 0 , ∑ i = 1 n α i y i = 0 \alpha_i \geq 0, \quad \sum_{i=1}^{n} \alpha_i y_i = 0 αi≥0,i=1∑nαiyi=0 -
最优解 α ∗ \alpha^* α∗ 被找到后,可以通过 w ∗ = ∑ i = 1 n α i ∗ y i x i w^* = \sum_{i=1}^{n} \alpha_i^* y_i x_i w∗=∑i=1nαi∗yixi 计算得到超平面的法向量, b ∗ b^* b∗ 由支持向量计算得到。
3. 非线性 SVM
3.1 推导过程
非线性支持向量机(Nonlinear Support Vector Machine)通过引入核函数来处理非线性可分的情况。核函数允许我们将数据映射到高维空间,使得在高维空间中数据变得线性可分。以下是非线性支持向量机的推导过程:
假设我们有训练数据集: { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)},其中 x i x_i xi 是输入样本, y i y_i yi 是对应的类别标签(+1 或 -1)。
-
我们引入一个映射函数 ϕ : R d → R D \phi: \mathbb{R}^d \rightarrow \mathbb{R}^D ϕ:Rd→RD,将原始输入空间映射到更高维的特征空间,其中 D D D 是高维空间的维数。
-
我们的目标是在特征空间中找到一个线性可分的超平面。超平面表示为 w ⋅ ϕ ( x ) + b = 0 w \cdot \phi(x) + b = 0 w⋅ϕ(x)+b=0,其中 w w w 是法向量(weights), b b b 是偏置(bias)。
-
SVM 的优化目标是最大化间隔,即最小化 ∥ w ∥ \|w\| ∥w∥。目标函数为:
min 1 2 ∥ w ∥ 2 \text{min} \quad \frac{1}{2} \|w\|^2 min21∥w∥2
约束条件为:
y i ( w ⋅ ϕ ( x i ) + b ) ≥ 1 , for all i = 1 , 2 , . . . , n y_i(w \cdot \phi(x_i) + b) \geq 1, \quad \text{for all} \ i = 1, 2, ..., n yi(w⋅ϕ(xi)+b)≥1,for all i=1,2,...,n -
利用拉格朗日乘子法,我们将目标函数和约束条件转化为拉格朗日函数:
L ( w , b , α ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i [ y i ( w ⋅ ϕ ( x i ) + b ) − 1 ] \mathcal{L}(w, b, \alpha) = \frac{1}{2} \|w\|^2 - \sum_{i=1}^{n} \alpha_i \left[ y_i(w \cdot \phi(x_i) + b) - 1 \right] L(w,b,α)=21∥w∥2−i=1∑nαi[yi(w⋅ϕ(xi)+b)−1]
其中, α i \alpha_i αi 是拉格朗日乘子。 -
对 L \mathcal{L} L 分别对 w w w 和 b b b 求偏导数并令其等于零,得到:
w = ∑ i = 1 n α i y i ϕ ( x i ) w = \sum_{i=1}^{n} \alpha_i y_i \phi(x_i) w=i=1∑nαiyiϕ(xi)
∑ i = 1 n α i y i = 0 \sum_{i=1}^{n} \alpha_i y_i = 0 i=1∑nαiyi=0 -
将以上结果代入拉格朗日函数,得到拉格朗日对偶问题:
max ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j K ( x i , x j ) \text{max} \quad \sum_{i=1}^{n} \alpha_i - \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j K(x_i, x_j) maxi=1∑nαi−21i=1∑nj=1∑nαiαjyiyjK(xi,xj)
约束条件为:
α i ≥ 0 , ∑ i = 1 n α i y i = 0 \alpha_i \geq 0, \quad \sum_{i=1}^{n} \alpha_i y_i = 0 αi≥0,i=1∑nαiyi=0这里, K ( x i , x j ) K(x_i, x_j) K(xi,xj) 是核函数,它表示在特征空间中点 x i x_i xi 和 x j x_j xj 的内积。
-
选择适当的核函数,如线性核、多项式核、高斯核等,根据问题的性质来进行非线性映射。
-
最优解 α ∗ \alpha^* α∗ 被找到后,可以通过 w ∗ = ∑ i = 1 n α i ∗ y i ϕ ( x i ) w^* = \sum_{i=1}^{n} \alpha_i^* y_i \phi(x_i) w∗=∑i=1nαi∗yiϕ(xi) 计算得到超平面的法向量, b ∗ b^* b∗ 由支持向量计算得到。
这样,通过引入核函数,我们可以处理非线性可分的情况,将数据映射到高维空间中,然后在高维空间中寻找线性可分的超平面。
3.2 常用核函数
核函数在非线性支持向量机中扮演着关键的角色,它用于将输入数据映射到高维空间,从而使得在高维空间中的数据更容易被线性分割。以下是一些常用的核函数:
-
线性核函数(Linear Kernel):
K ( x i , x j ) = x i ⋅ x j K(x_i, x_j) = x_i \cdot x_j K(xi,xj)=xi⋅xj
简单的内积操作,适用于线性可分的情况。 -
多项式核函数(Polynomial Kernel):
K ( x i , x j ) = ( x i ⋅ x j + c ) d K(x_i, x_j) = (x_i \cdot x_j + c)^d K(xi,xj)=(xi⋅xj+c)d
其中, c c c 是常数, d d d 是多项式的次数。通过调整 c c c 和 d d d 可以实现不同程度的非线性映射。 -
高斯径向基核函数(Gaussian Radial Basis Function, RBF):
K ( x i , x j ) = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) K(x_i, x_j) = \exp\left(-\frac{\|x_i - x_j\|^2}{2\sigma^2}\right) K(xi,xj)=exp(−2σ2∥xi−xj∥2)
其中, σ \sigma σ 是控制函数宽度的参数。常用于处理复杂的非线性关系,对于很多问题表现良好。 -
Sigmoid核函数:
K ( x i , x j ) = tanh ( α x i ⋅ x j + c ) K(x_i, x_j) = \tanh(\alpha x_i \cdot x_j + c) K(xi,xj)=tanh(αxi⋅xj+c)
其中, α \alpha α 和 c c c 是调节参数。它类似于神经网络中的激活函数。 -
拉普拉斯核函数(Laplacian Kernel):
K ( x i , x j ) = exp ( − ∥ x i − x j ∥ σ ) K(x_i, x_j) = \exp\left(-\frac{\|x_i - x_j\|}{\sigma}\right) K(xi,xj)=exp(−σ∥xi−xj∥)
类似于高斯核函数,但它对离中心点较远的数据点的惩罚更加明显。 -
多项式Spline核函数:
K ( x i , x j ) = ( 1 + x i ⋅ x j + ( x i ⋅ x j ) 2 2 ) d K(x_i, x_j) = \left(1 + x_i \cdot x_j + \frac{(x_i \cdot x_j)^2}{2}\right)^d K(xi,xj)=(1+xi⋅xj+2(xi⋅xj)2)d
这是一种非线性的核函数,可以通过调整参数 d d d 来实现不同程度的非线性映射。
4. 参考
《NLP深入学习(一):jieba 工具包介绍》
《NLP深入学习(二):nltk 工具包介绍》
《NLP深入学习(三):TF-IDF 详解以及文本分类/聚类用法》
《NLP深入学习(四):贝叶斯算法详解及分类/拼写检查用法》
《NLP深入学习(五):HMM 详解及字母识别/天气预测用法》
《NLP深入学习(六):n-gram 语言模型》
《NLP深入学习(七):词向量》
《NLP深入学习(八):感知机学习》
《NLP深入学习(九):KNN 算法及分类用法》
《NLP深入学习(十):决策树(ID3、C4.5以及CART)》
《NLP深入学习(十一):逻辑回归(logistic regression)》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤
















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











