






文章目录
0. 引言
前情提要:
《NLP深入学习(一):jieba 工具包介绍》
1. 什么是 NLTK
NLTK(Natural Language Toolkit)是一个强大的Python库,专为自然语言处理(NLP)任务而设计。它由Steven Bird 和 Edward Loper 在宾夕法尼亚大学开发,并且是开源的,允许研究者和开发者在 NLP 领域进行教学、学习和实践。
NLTK 官网:https://www.nltk.org/
1.1 主要特点
- 数据集与语料库:NLTK 提供了一系列预处理过的文本语料库,例如布朗语料库、Gutenberg 项目电子书、Treebank 等,以及用于训练和测试模型的数据资源,如词性标注数据集和命名实体识别数据集。
- 语言处理模块:涵盖了多种 NLP 任务的功能,如分词(tokenization)、词性标注(POS tagging)、命名实体识别(NER)、句法分析(parsing)、情感分析(sentiment analysis)、文本分类(text classification)、chunking、stemming/lemmatization等。
- 易用接口:NLTK 提供了简洁的API,使得用户能够方便地加载数据、应用预定义的算法或者创建自定义的 NLP组件。
- 教育与学习:NLTK 包含了丰富的教程和示例代码,是许多NLP课程的基础教材,适合初学者逐步学习并实践NLP的基本概念和技术。
- 多样的算法实现:集成了一些经典的自然语言处理算法,同时也支持用户导入其他第三方工具包(如Stanford NLP或spaCy)以获取更复杂和高效的处理能力。
下载nltk
pip install nltk
1.2 NLTK 使用示例
- 对一些文本进行 tokenize
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
- 识别命名实体
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
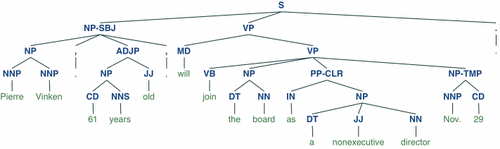
- 显示解析树
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> t.draw()
2. 句子和单词标记化(tokenization)
标记化是将文本分解为单词、短语、符号或其他称为标记的有意义元素的过程。分词器的输入是 unicode 文本,输出是句子或单词的列表。
在 NLTK 中,有两种类型的分词器——单词分词器和句子分词器。
from nltk.tokenize import sent_tokenize, word_tokenize
text = "Natural language processing is fascinating. It involves many tasks such as text classification, sentiment analysis, and more."
sentences = sent_tokenize(text)
print(sentences)
words = word_tokenize(text)
print(words)
输出:
['Natural language processing is fascinating.', 'It involves many tasks such as text classification, sentiment analysis, and more.']
['Natural', 'language', 'processing', 'is', 'fascinating', '.', 'It', 'involves', 'many', 'tasks', 'such', 'as', 'text', 'classification', ',', 'sentiment', 'analysis', ',', 'and', 'more', '.']
sent_tokenize 函数将文本拆分为句子,word_tokenize函数将文本拆分为单词,标点符号也被视为单独的标记。
3. 移除停用词(Stopwords)
在自然语言处理中,停用词是想要忽略的单词,在处理文本时将其过滤掉。这些通常是在任何文本中经常出现的单词,并且不传达太多含义。
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
text = "Natural language processing is fascinating. It involves many tasks such as text classification, sentiment analysis, and more."
stop_words = set(stopwords.words('english'))
words = word_tokenize(text)
filtered_words = [word for word in words if word.casefold() not in stop_words]
print(filtered_words)
输出:
['Natural', 'language', 'processing', 'fascinating', '.', 'involves', 'many', 'tasks', 'text', 'classification', ',', 'sentiment', 'analysis', ',', '.',]
在这段代码中,我们首先从 NLTK 导入停用词,对文本进行分词,然后过滤掉停用词。casefold()方法用于在将单词与停用词列表进行比较时忽略大小写。
4. 词干提取
词干提取是将单词的词形变化(例如 running、runs)减少为其词根形式(例如 run)的过程。在这种情况下,“词根”实际上可能不是真正的词根,而只是原始词的规范形式。NLTK 提供了几个著名的词干分析器接口,例如PorterStemmer。
以下是如何使用 NLTK 的 PorterStemmer:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
text = "He was running and eating at same time. He has bad habit of swimming after playing long hours in the Sun."
porter_stemmer = PorterStemmer()
words = word_tokenize(text)
stemmed_words = [porter_stemmer.stem(word) for word in words]
print(stemmed_words)
输出:
['he', 'wa', 'run', 'and', 'eat', 'at', 'same', 'time', '.', 'he', 'ha', 'bad', 'habit', 'of', 'swim', 'after', 'play', 'long', 'hour', 'in', 'the', 'sun', '.']
在这段代码中,我们首先对文本进行标记,然后将每个单词传递到stem词干分析器的函数中。
5. 词性标注
词性标记是根据单词的定义和上下文将文本中的单词标记为与特定词性(名词、动词、形容词等)相对应的过程。
NLTK 库有一个函数,可以pos_tag用词性描述符来标记单词。
from nltk.tokenize import word_tokenize
from nltk import pos_tag
text = "Natural language processing is fascinating. It involves many tasks such as text classification, sentiment analysis, and more."
words = word_tokenize(text)
tagged_words = pos_tag(words)
print(tagged_words)
输出:
[('Natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('is', 'VBZ'), ('fascinating', 'VBG'), ('.', '.'), ('It', 'PRP'), ('involves', 'VBZ'), ('many', 'JJ'), ('tasks', 'NNS'), ('such', 'JJ'), ('as', 'IN'), ('text', 'NN'), ('classification', 'NN'), (',', ','), ('sentiment', 'NN'), ('analysis', 'NN'), (',', ','), ('and', 'CC'), ('more', 'JJR'), ('.', '.')]
NLTK 中使用的一些常见词性标签及其含义的列表:
| Tag | Meaning | 含义 |
|---|---|---|
| CC | Coordinating conjunction | 并列连词 |
| CD | Cardinal number | 基数词(数字) |
| DT | Determiner | 限定词 |
| EX | Existential there | 存在句型 “there” |
| FW | Foreign word | 外来语 |
| IN | Preposition or subordinating conjunction | 介词或从属连词 |
| JJ | Adjective | 形容词 |
| JJR | Adjective, comparative | 形容词,比较级 |
| JJS | Adjective, superlative | 形容词,最高级 |
| LS | List item marker | 列表项标记 |
| MD | Modal | 情态动词 |
| NN | Noun, singular or mass | 名词,单数或质量 |
| NNS | Noun, plural | 名词,复数 |
| NNP | Proper noun, singular | 专有名词,单数 |
| NNPS | Proper noun, plural | 专有名词,复数 |
| PDT | Predeterminer | 前位限定词 |
| POS | Possessive ending | 所有格结束词 |
| PRP | Personal pronoun | 人称代词 |
| PRP$ | Possessive pronoun | 所有格代词 |
| RB | Adverb | 副词 |
| RBR | Adverb, comparative | 副词,比较级 |
| RBS | Adverb, superlative | 副词,最高级 |
| RP | Particle | 小品词 |
| SYM | Symbol | 符号 |
| TO | “to” | “to” 介词/不定式标记 |
| UH | Interjection | 感叹词 |
| VB | Verb, base form | 动词,基本形式 |
| VBD | Verb, past tense | 动词,过去式 |
| VBG | Verb, gerund or present participle | 动词,动名词或现在分词 |
| VBN | Verb, past participle | 动词,过去分词 |
| VBP | Verb, non-3rd person singular present | 动词,非第三人称单数现在时 |
| VBZ | Verb, 3rd person singular present | 动词,第三人称单数现在时 |
| WDT | Wh-determiner | Wh-限定词 |
| WP | Wh-pronoun | Wh-代词 |
| WP$ | Possessive wh-pronoun | Wh-所有格代词 |
| WRB | Wh-adverb | Wh-副词 |
6. 命名实体识别
命名实体识别 (NER) 是定位文本中存在的命名实体并将其分类为预定义类别的过程,例如人名、组织、位置、医疗代码、时间表达、数量、货币价值、百分比等。
from nltk.tokenize import word_tokenize
from nltk import pos_tag, ne_chunk
text = "John works at Google in Mountain View, California."
words = word_tokenize(text)
tagged_words = pos_tag(words)
named_entities = ne_chunk(tagged_words)
print(named_entities)
输出将是一棵树,其中命名实体作为子树。子树的标签将指示实体的类型(即人员、组织、位置等)。例如:
(S
(PERSON John/NNP)
works/VBZ
at/IN
(ORGANIZATION Google/NNP)
in/IN
(GPE Mountain/NNP View/NNP)
,/,
(GPE California/NNP)
./.)
在此代码中,我们首先对文本进行标记,然后用其词性标记每个单词。然后ne_chunk函数识别命名实体。结果,“John”被识别为一个人,“Google”被识别为一个组织,“Mountain”和“California”被识别为地理位置。
7. 理解同义词集
同义词集(或同义词集)是在某些上下文中可互换的同义词的集合。这些对于构建知识图、语义链接或在上下文中查找单词的含义来说是非常有用的资源。
NLTK 提供了 WordNet API 的接口,可用于查找单词及其同义词、定义和示例。
from nltk.corpus import wordnet
syn = wordnet.synsets("dog")[0]
print(f"Synset name: {syn.name()}")
print(f"Lemma names: {syn.lemma_names()}")
print(f"Definition: {syn.definition()}")
print(f"Examples: {syn.examples()}")
输出
Synset name: dog.n.01
Lemma names: ['dog', 'domestic_dog', 'Canis_familiaris']
Definition: a member of the genus Canis (probably descended from the common wolf) that has been domesticated by man since prehistoric times; occurs in many breeds
Examples: ['the dog barked all night']
在此代码中,wordnet.synsets("dog")[0]为我们提供了单词“dog”的第一个同义词。该name方法返回同义词集的名称,lemma_names给出所有同义词,definition提供简要定义,并examples提供用法示例。
8. 频率分布
频率分布用于统计文本中每个单词的频率。它是一个分布,因为它告诉我们文本中的单词标记总数如何在单词类型之间分布。
from nltk.probability import FreqDist
from nltk.tokenize import word_tokenize
text = "Python is an interpreted, high-level, general-purpose programming language."
# Tokenize the sentence
tokens = word_tokenize(text)
# Create frequency distribution
fdist = FreqDist(tokens)
# Print the frequency of each word
for word, freq in fdist.items():
print(f'{word}: {freq}')
输出:
Python: 1
is: 1
an: 1
interpreted: 1
,: 2
high-level: 1
general-purpose: 1
programming: 1
language: 1
.: 1
9. 情绪分析
对于情感分析,NLTK 有一个内置模块,nltk.sentiment.vader它结合使用词汇和语法启发法以及基于人工注释数据训练的统计模型。以下是如何使用 NLTK 执行情感分析的基本示例:
from nltk.sentiment import SentimentIntensityAnalyzer
from nltk.sentiment.util import *
sia = SentimentIntensityAnalyzer()
text = "Python is an awesome programming language."
print(sia.polarity_scores(text))
输出:
{'neg': 0.0, 'neu': 0.439, 'pos': 0.561, 'compound': 0.6249}
在上面的代码中,我们首先创建一个SentimentIntensityAnalyzer对象。然后,我们向分析器输入一段文本并打印结果情绪分数。
输出是一个包含四个键的字典:neg、neu、pos和compound。、和值分别表示文本中负面、中性和正面情绪neg的比例。分数compound是一个汇总指标,表示文本的整体情感,根据前三个指标计算得出。
10. 参考
https://likegeeks.com/nlp-tutorial-using-python-nltk/
《NLP深入学习(一):jieba 工具包介绍》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤
















 5224
5224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











