







 本文通过Python爬虫分析某电商平台销量第一的车厘子,揭示2021年车厘子销量暴涨背后的原因。数据包括用户评分、评论内容等,通过数据清洗、词频和词云展示,以及情感分析,揭示消费者对车厘子的热爱。
本文通过Python爬虫分析某电商平台销量第一的车厘子,揭示2021年车厘子销量暴涨背后的原因。数据包括用户评分、评论内容等,通过数据清洗、词频和词云展示,以及情感分析,揭示消费者对车厘子的热爱。
又到了吃车厘子的季节。
冬季,中国市面上的车厘子主要来自南半球的智利、新西兰和澳大利亚等地,其中中国更是智利最大的车厘子出口国,出国占比达百分之90以上。。

远隔重洋、长途跋涉而来的车厘子的消费价格里包括了运输费用、冷藏费用等额外费用,自然冬季车厘子对于夏季的车厘子价格上要高出不少。另外,货以稀为贵,中国冬季水果相对于夏季稀缺,惹众人垂涎的车厘子价格自然水涨船高。
但是这些因素丝毫不能影响中国吃货对车厘子的钟爱。2021车厘子销量暴涨32倍,中国吃货凭实力养活50万智利人
今天我们那就来某东网看看销量第一10w+的车厘子到底有多受欢迎?

1 需求分析
我们本次获取的目标有用户昵称、产品评分、产品类型、评论时间、评论点赞数和回复数还有具体评论内容等七项内容
2 网页分析

从图中我们要获取的内容都在当前页面中,我们使用浏览器打开格式如下:
这是一个json格式的数据集。

3 发送请求
分析完了我们上代码,使用requests发送请求获取网页响应
url = f'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page={page}&pageSize=10&isShadowSku=0&rid=0&fold=1'
headers = {
'Cookie': xxxxxx',
'Referer': 'https://item.jd.com/',
'User-Agent': 'xxxxxx'
}
# 获取响应
resp = requests.get(url, headers=headers)
结果如下,我们可以看到打印出来的结果不是一个标准的json格式数据集
所以我们先要构造标准的json格式
便于我们后续对数据内容进行提取。

构造方法如下:
json_data = json.loads(resp.text[20:-2])
然后我们获取我们所要的内容,成功打印如下:
for cmts in json_data['comments']:
# 昵称
nickname = cmts['nickname']
# 评分
score = cmts['score']
# 评论
comments = cmts['content']
# 产品类型
product = cmts['productColor']
# 评论时间
time = cmts['referenceTime']
# 评论点赞数
starVote = cmts['usefulVoteCount']
# 评论回复数
cmtsReply = cmts['replyCount']
print(nickname, score, comments, product, time, starVote, cmtsReply)
'''
滨***啡 5 非常新鲜,过年菜市场车厘子价格太高,直奔8-90一斤,用京东省了不少钱! 2019-01-23 23:08:02 1 1
****j 5 收到货真是大吃一惊,个个顶呱呱……物流特别给力隔天就收到了。和我在实体店买的98一斤的不分上下。口感特别美味,肉肉特别多水分也很充足……总之非常非常满意。下次需要还会继续回购!愿卖家生意红红火火…………… 2019-02-23 15:28:54 1 1
d***l 5 质量很不错,好吃!棒棒的!!! 2019-01-31 17:21:45 1 1
G***j 5 发货快,非常甜,简直是惊喜呀!太喜欢了? 2019-01-31 11:13:34 1 1
小***5 5 味道很甜,水分很足,超级棒,值得购买,推荐推荐,顺丰两天就收到了,真是好吃,还要买? 2019-01-23 22:39:34 1 1
****j 5 收到了车厘子,非常新鲜,我所以不厌其烦地拍了那么多照片,就是让大家知道,这箱车厘子包装的非常好。检查了一下,没有坏果,和我期待的是一样的。从物流踪迹来看,,顺丰快递一环一环衔接的很紧密,我很满意。这一款车厘子买的很值:价格实惠,送货速度快,水果质量好,这一切让我对这一家印象深刻。 2019-01-23 09:05:14 1 1
****h 5 果实肥硕,甜美,包装保护到位,很好吃,怎么感觉没吃几颗没有了,没有了,伤心 2019-01-05 21:05:33 1 1
****d 5 包装很到位,贴心。果子也非常均匀,口感新鲜,酸酸甜甜,挺好! 2018-07-20 16:44:19 1 1
u***v 5 很喜欢已经推荐给单位的同事啦,同事也品尝了很爽口。感谢有诚意的店,给我们提供这么好的农户产品,让夏天过的也十分的清甜,等这次吃完了,我们就集体团购。一定五星好评,也非常谢谢客服热情的服务也谢谢售后的工作人员。非常的诚恳,有坏果果,都是按照等价兑换的。 2018-07-05 21:51:37 1 1
****4 5 是隔了一天收到的 从烟台过来算快的了 烟台又大又甜 没有坏的 3斤对的 非常满意 2018-06-01 20:27:03 1 2
'''
4 多页爬取
我们有多页爬取的需求就要观察多页来链接的规律从而构造出多页请求的
真实链接。
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&rid=0&fold=1
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page=1&pageSize=10&isShadowSku=0&rid=0&fold=1
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page=2&pageSize=10&isShadowSku=0&rid=0&fold=1
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page=3&pageSize=10&isShadowSku=0&rid=0&fold=1
从以上连接我们可以观察得出控制翻页的就是page参数。
所以我们据此构造出以下链接从而获取多页数据。
url = f'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=20180186520&score=0&sortType=5&page={page}&pageSize=10&isShadowSku=0&rid=0&fold=1'
我们先来获取前100页数据作为测试如下:

5 数据存储
存储数据我们使用openpyxl将其存于Excel,便于我们后续的数据清洗、处理和可视化
具体可以参考以下教程:
ws = op.Workbook()
wb = ws.create_sheet(index=0)
wb.cell(row=1, column=1, value='昵称')
wb.cell(row=1, column=2, value='评分')
wb.cell(row=1, column=3, value='产品类型')
wb.cell(row=1, column=4, value='评论时间')
wb.cell(row=1, column=5, value='评论点赞数')
wb.cell(row=1, column=6, value='评论回复数')
wb.cell(row=1, column=7, value='评论内容')
wb.cell(row=count, column=1, value=nickname)
wb.cell(row=count, column=2, value=score)
wb.cell(row=count, column=3, value=product)
wb.cell(row=count, column=4, value=time)
wb.cell(row=count, column=5, value=starVote)
wb.cell(row=count, column=6, value=cmtsReply)
wb.cell(row=count, column=7, value=comments)
ws.save('车厘子.xlsx')
结果如下:

6 数据清洗
我们在此使用pandas对数据进行读取然后去重复和去除空值处理。
随机抽取五条数据展示如下:
# 读取文件
rcv_data = pd.read_excel('./车厘子.xlsx')
# 删除重复记录和缺失值
rcv_data = rcv_data.drop_duplicates()
rcv_data = rcv_data.dropna()
# 抽样展示
print(rcv_data.sample(5))
'''
昵称 评分 产品类型 评论时间 评论点赞数 评论回复数 评论内容
535 小***太 5 NaN 2021-01-20 11:21:13 0 0 发货速度还挺快,味道很棒,很新鲜
10 y***0 5 NaN 2021-03-18 21:18:48 1 1 宝贝已经收到非常喜欢这款真的是好舒服
529 w***4 5 NaN 2021-01-20 14:30:50 0 1 送货快包装完好无损,货到时冰冰凉凉非常新鲜,樱桃个大均匀,饱满多汁,甜中微微带点儿酸,非常好...
278 u***s 5 NaN 2021-07-03 12:40:27 0 0 送货很快,包装完好,新鲜。酸甜可口。
82 小***_ 5 NaN 2020-05-13 12:39:49 2 0 品质特好,味道不错,很好的东西,快递也很给力,东西包装很好,卖家也给力,值得购买5 21:51:37 1 1
****4 5 是隔了一天收到的 从烟台过来算快的了 烟台又大又甜 没有坏的 3斤对的 非常满意 2018-06-01 20:27:03 1 2
'''
7 词频展示
数据可视化之前我们先要对数据进行预处理,这里我们使用的是熊猫来处理数据,具体可以参考:
让人无法拒绝的pandas技巧,简单却好用到爆!
我们获取前十个高频词汇以及出现频率动图如下:
# 词频设置
all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words]
wordcount = Counter(all_words).most_common(100)
x1_data, y1_data = list(zip(*wordcount))
print(x1_data)
print(y1_data)


7 词云展示
我们使用stylecloud来绘图,部分代码如下:
有兴趣的笑傲伙伴可以参考:
def visual_ciyun():
mask = imread('1.jpg')
wordcloud = WordCloud(font_path='msyh.ttc', mask = mask, stopwords=stop_words, background_color='white').generate(result)
wordcloud.to_file('pic.jpg')
print('词云图绘制成功!')


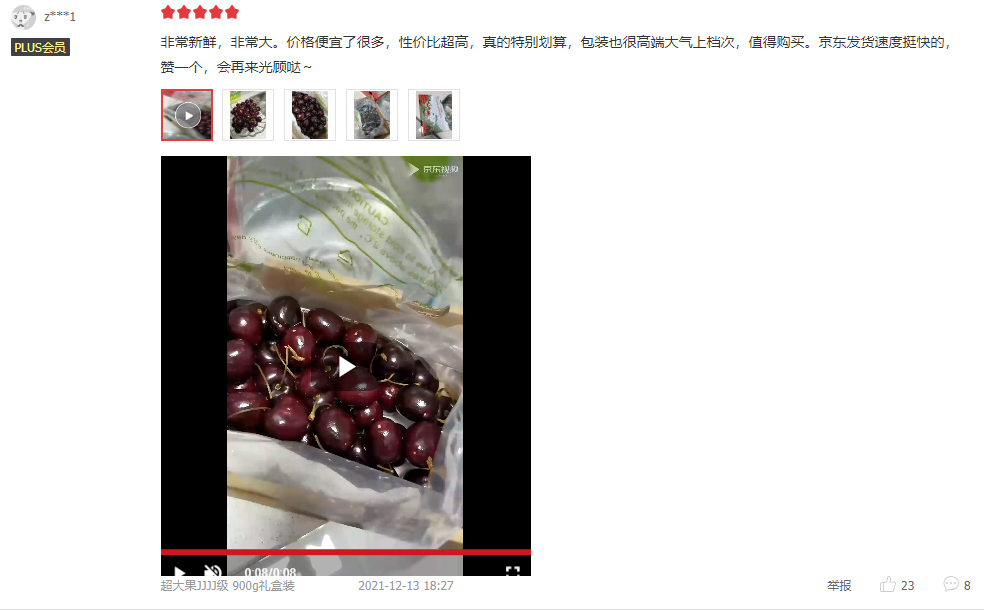
评论点赞最多
我们使用pandas找出点赞最多的一条评论
max_stars = rcv_data[rcv_data['评论点赞数'] == rcv_data['评论点赞数'].max()]
'''
昵称 评分 产品类型 评论时间 评论点赞数 评论回复数 评论内容
z***1 5 NaN 2021-12-13 18:27 169 21 非常新鲜,非常大。价格便宜了很多,性价比超高,真的特别划算,包装也很高端大气上档次,值得购买。京东发货速度挺快的,赞一个,会再来光顾哒~
'''
评论内容如下:
情感分析
如果有人问,有没有比较快速简单的方法,快速进行情感分析,那么 SnowNLP 库就是答案。
SnowNLP 主要可以进行中文分词、词性标注、情感分析、文本分类、转换拼音、繁体转简体、提取文本关键词、提取摘要、分割句子、文本相似等。
需要注意的是,用 SnowNLP 进行情感分析,官网指出电商评论的准确率较高,其实是因为它的语料库主要是电商评论数据,但是可以自己构建相关领域语料库,替换单一的电商评论语料,准确率也挺不错的。
安装
pip install snownlp
使用
from snownlp import SnowNLP
情感分析
我们通过用户的评论数据来对车厘子做一些简单的分析和占比
# 情感分析
def anay_data():
all_words = [word for word in result.split(' ') if len(word) > 1 and word not in stop_words]
positibe = negtive = middle = 0
for i in all_words:
pingfen = SnowNLP(i)
if pingfen.sentiments > 0.7:
positibe += 1
elif pingfen.sentiments < 0.3:
negtive += 1
else:
middle += 1
print(positibe, negtive, middle)
'''
6125 500 2567
'''

SnowNLP 对情感的测试值为 0 到 1,值越大,说明情感倾向越积极。
得到的情感值很高,说明买家对商品比较认可


















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











