







东北民间流传着关于“皇围猎人”的神秘传说
他们世代生存于深山,为帝王守护兴安岭这片龙兴之地的气脉运转。传闻猎人除了精通狩猎之法,更知晓驱鬼通神之术。
在东北一处偏僻的山村里,悄然发生一起灭门惨案,在村民们的恳求下,最后一代皇围猎人刘二爷决定出山调查真相,不想过程中怪事屡现,
老林子里的秘密也被渐渐揭开.....

咱打小就喜欢看这种片子,大兴安岭、东北马氏、神农架、盗墓笔记、鬼吹灯这种片子看得我是不亦乐乎。
前一个月在抖音上看到这部片子预告的时候就已经迫不及待了,今天为了看片还专门开了个腾讯会员。看完一个字:过瘾!
了解一下其他小伙伴看此片的有什么感受,今天就用python爬虫来获取一下16978条弹幕都说了啥?
老规矩,搞爬虫就上三部曲:
1--获取目标网址;
2--发送请求;
3--获取响应
我们的目标是腾讯视频,所以首先打开软件搜索我们的电影猎人传说,可以看到弹幕在不断的刷新,后台数据也是在不断刷新的。

针对这种情况我们该如何快速锁定这些弹幕呢?
打开之后搜索F12打开开发者模式,然后搜索其中一条弹幕信息,然后找到它所对应的链接如下:
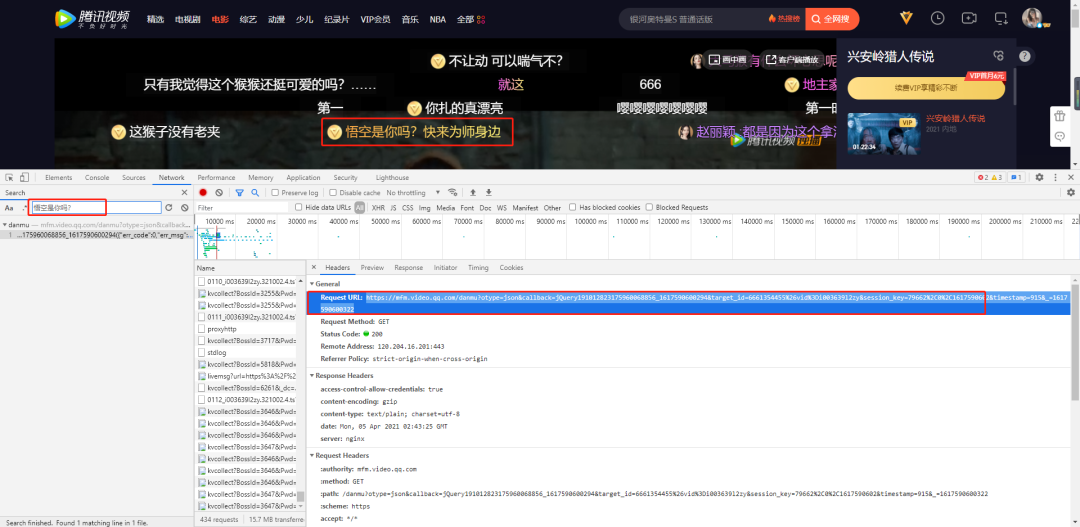
复制链接到网页发现包含210条弹幕信息,而我们所要的信息都在这个'content'的字段里
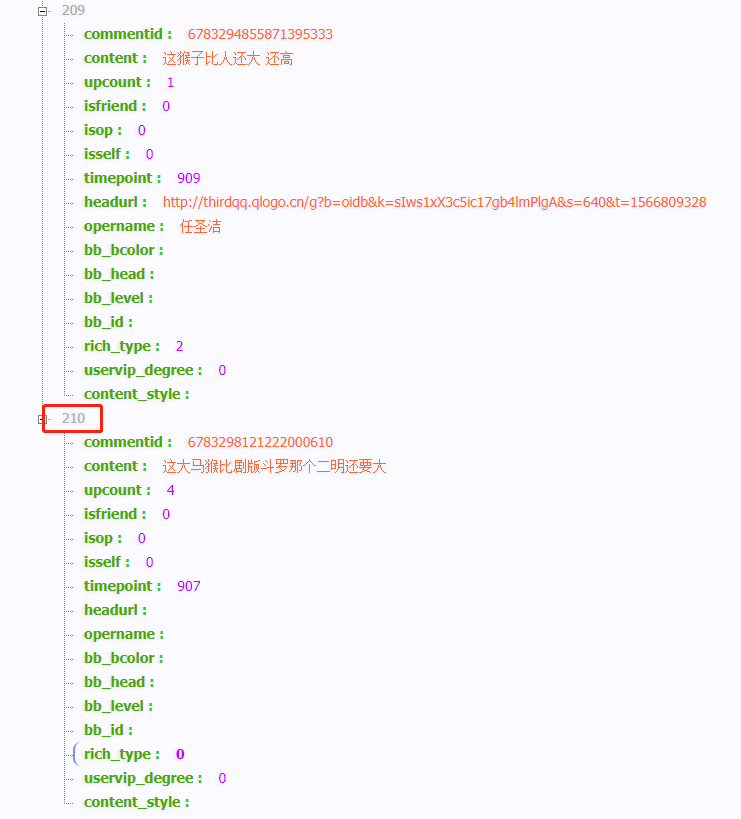
返回浏览器的Preview也可以看到同类信息。这些弹幕信息也是在content中。
我们先来试试获取这些弹幕信息。
#获取浏览器响应信息
resp = requests.get(url, headers = headers)
#转为json对象
json_data = json.loads(resp.text)['comments']
#打印浏览器响应数据
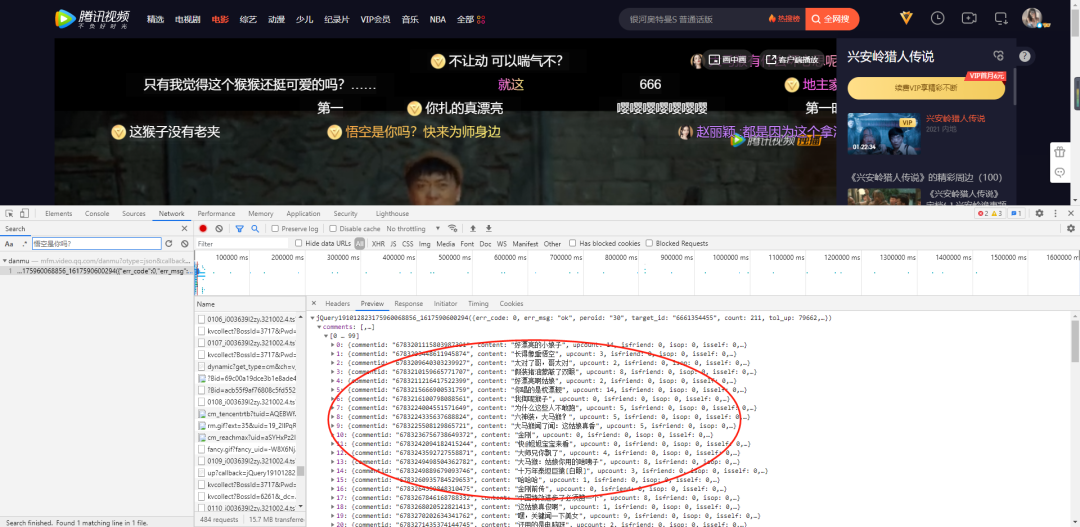
print(json_data)结果如下,可以看到我们已经成功获取到了浏览器相应的信息。姑且可以从中获取我们想要的弹幕信息。
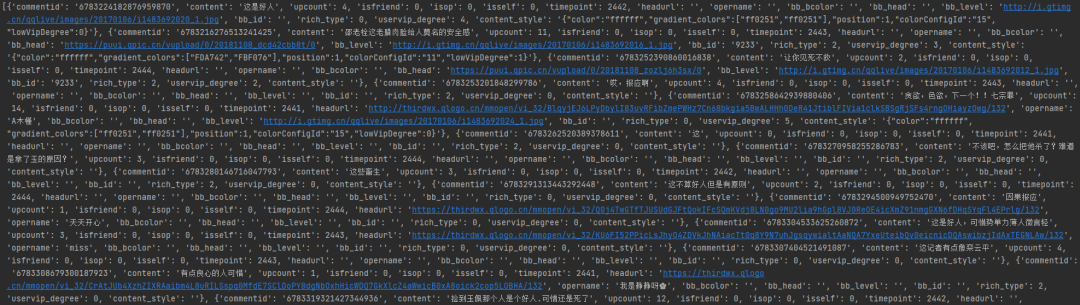
从上图可以看出我们想要获取的content信息都包含在我们已经获取到的jason数据中,我们接下来要做的只是遍历出其中信息即可。
#遍历comments中的弹幕信息
for comment in json_data:
print(comment['content'])结果如下:

可以看出,获取一个请求的弹幕信息已经成功抓取到我们本地。但是我们要获取的是整部片子的弹幕。这只是其中一条请求的210条弹幕而已。
所以接下来的重点是如何获取全部的请求。这里有一个取巧办法,搜索第一条弹幕链接和最后一条弹幕链接。找出来做对比。
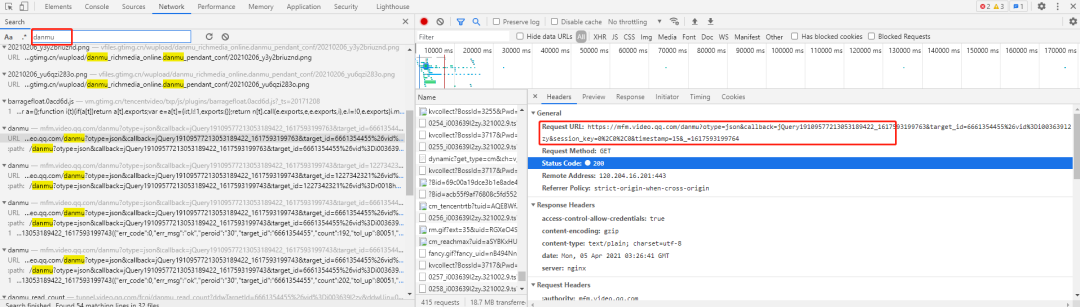
找出规律:
https://mfm.video.qq.com/danmu?target_id=6661354455%26vid%3Di003639l2zy×tamp=15
https://mfm.video.qq.com/danmu?target_id=6661354455%26vid%3Di003639l2zy×tamp=2445发现它的参数timestamp是从15开始到2445结束的。
所以我们可以使用一个函数来获取这些弹幕请求信息:
def get_danmu():
url = 'https://mfm.video.qq.com/danmu?target_id=6661354455%26vid%3Di003639l2zy×tamp=15'
for i in range(15, 2445, 30):
data = {'timestamp':i}
res = requests.get(url, params = data, headers = headers)
# 转为json对象
json_data = json.loads(res.text)['comments']
# 遍历comments中的弹幕信息
for comment in json_data:
print(comment['content'])到此位置整部片子的所有弹幕已经保存于本地了,接下来我们要词云做更加直观的显示,所以我们先将这些数据保存到本地txt文档中。
comments_file_path = 'lrcs_comments.txt'
# 获取comments中的弹幕信息并且写入指定路径
for comment in json_data:
with open(comments_file_path, 'a+', encoding = 'utf-8')as fin:
fin.write(comment['content']+'\n')
文本保存好之后第一步我们需要切割分词,这里我们采用精确模式来切割最适合用于数据分析。
#切割单词
#定义切割单词函数
def cut_words():
#读取文本
with open(comments_file_path, encoding = 'utf-8') as file:
comment_text = file.read()
#使用jieba精确模式,句子最精确地切开,适合文本分析
word_list = jieba.lcut_for_search(comment_text)
new_word_list = ' '.join(word_list)
return new_word_list结果如下:

分词切割好之后我们就可以用它来做词云图了
#制作词云图函数
def create_word_cloud():
#自定义图片
mask = imread('img.png')
wordcloud = WordCloud(font_path='msyh.ttc', mask=mask).generate(cut_words())
wordcloud.to_file('picture.png')我在此选的图片是一张大马猴的图片。

最终词云图如下:

感觉一部惊悚片愣是被小伙伴们看出了喜感。这审美差距十万八千里啊!
有空你也看一下,完了写一下你的观后感~~~~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











