









dlib下载和编译
- 从官网下载最新版的压缩包,解压到指定目录
- 安装cmake,我使用的是cmake-3.10.0-rc1-win64-x64版本
- 在cmake的bin目录下找到"cmake-gui.exe"运行,如图进行设置
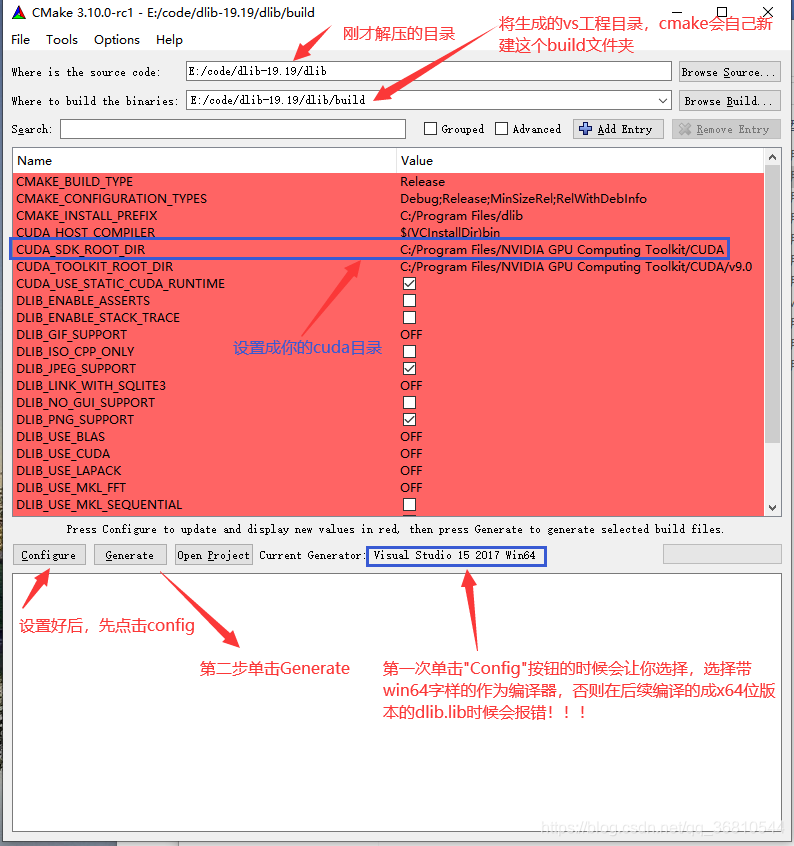
- 如果一切顺利的话,在你的build目录下会生成vs的工程文件,目录结构如下:
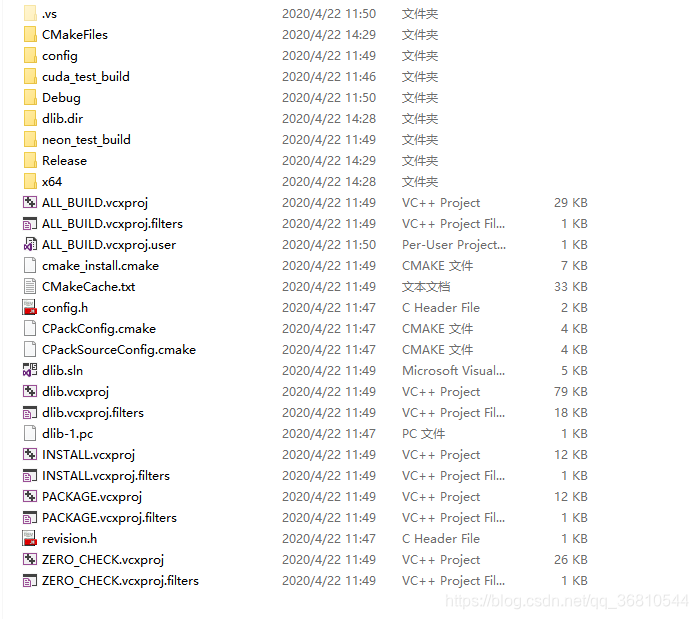
- 使用vs2017打开刚才生成的工程文件,选择Release版本进行编译。(Debug模式也行,但是在后续的使用过程中会慢的怀疑人生,而且Debug版本有88M,Release版本只有21M)
人脸识别工程配置
-
vs2017中新建一个基于控制台的c++工程,默认你已经安装opencv
-
选择"项目"->“属性”,配置项目依赖的头文件和库文件
- 设置包含的目录,需要设置"包含目录"和"库目录",确认"平台"是x64(因为上一步编译的dlib是x64版本的,同理如果建立的是x86版本的,则上一步cmake的时候需要选择x86的编译器)
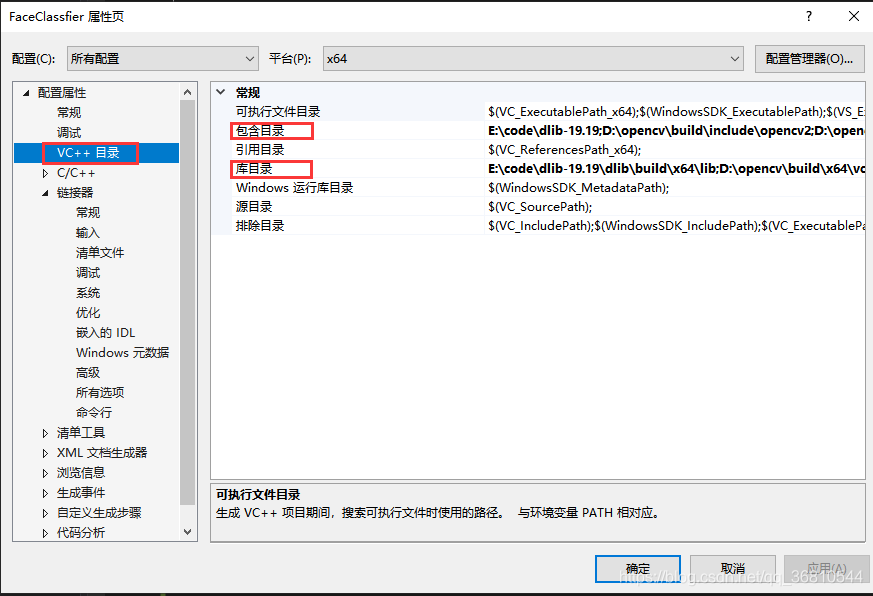 包含目录中输入你的dlib和opencv头文件的目录路径。注意:dlib的包含路径只需要包含到dlib-19.19这个目录,不需要将dlib这个文件夹包含进去
包含目录中输入你的dlib和opencv头文件的目录路径。注意:dlib的包含路径只需要包含到dlib-19.19这个目录,不需要将dlib这个文件夹包含进去
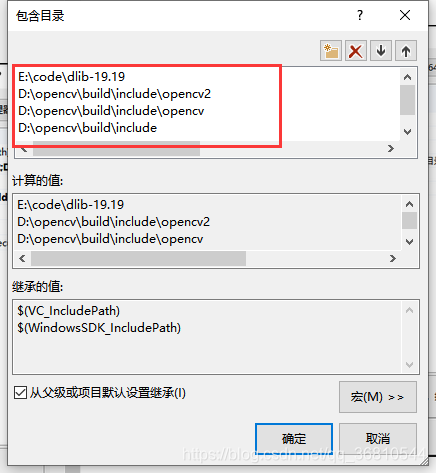
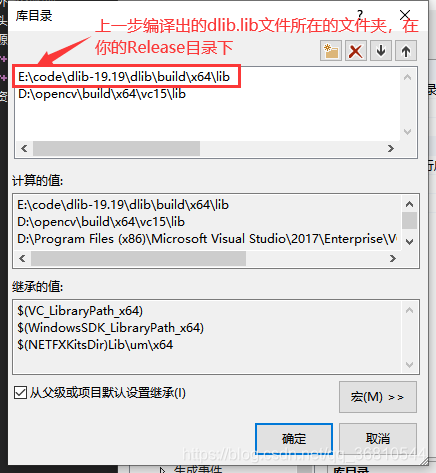
库目录设置:
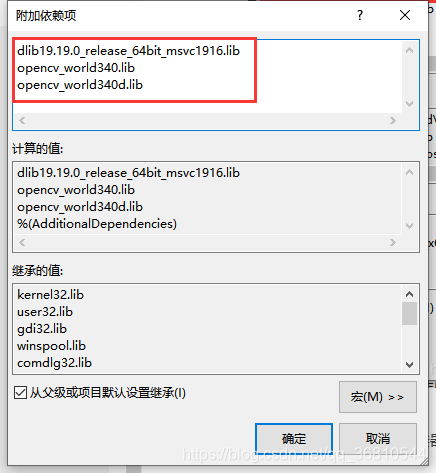
- 在工程属性页中选择"连接器"->“输入”,打开"附加依赖项",输入依赖的*.lib文件名
- 设置包含的目录,需要设置"包含目录"和"库目录",确认"平台"是x64(因为上一步编译的dlib是x64版本的,同理如果建立的是x86版本的,则上一步cmake的时候需要选择x86的编译器)
准备识别所需的模型文件和准备数据
- dlib已经提供了训练好的模型文件,需要下载两个文件分别用于检测和识别,可以在这里下载:https://github.com/davisking/dlib-models,下载shape_predictor_68_face_landmarks.dat和dlib_face_recognition_resnet_model_v1.dat
- 下载好后放到自定义的文件夹中,比如我放在了工程目录下的model文件夹中
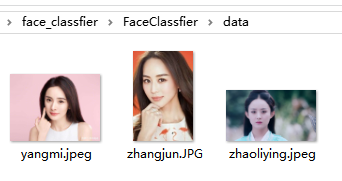
- 准备几张人脸图片,我找了大幂幂、颖宝和张钧甯的图片各一张,当数据集。我放在了data文件夹中(随便找个文件夹放)
人脸识别原理简述
- 检测出图片中的人脸
- 将人脸送入特征提取器得到人脸特征,这里得到的是一个128维的特征
- 分别提取数据集中的人脸特征,得到特征数据集
- 摄像头得到一张新图片,经过检测器->特征提取器得到新图片的人脸特征
- 计算新特征到特征数据集中各个向量的距离,取最小值
- 预定义一个阈值,如果最小值大于阈值则新图片不在数据集中,否则找到该特征对应的标签输出
代码实现
说明:只做为演示demo使用,没有做任何异常处理和输入/输出处理,路径已经全部写死请更改为自己的路径,或者使用cin>>输入。代码参考了https://blog.csdn.net/sinat_35907936/article/details/88765314这篇博文,我做了重构,对作者表示感谢!
#include "pch.h"
#include <iostream>
#include <cstdio>
#include <vector>
#include <algorithm>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/core/core.hpp>
#include <dlib/dnn.h>
#include <dlib/gui_widgets.h>
#include <dlib/clustering.h>
#include <dlib/string.h>
#include <dlib/image_io.h>
#include <dlib/image_processing/frontal_face_detector.h>
#include <dlib/opencv.h>
using namespace cv;
using namespace dlib;
using namespace std;
// 声明resnet
template <template <int, template<typename>class, int, typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual = add_prev1<block<N, BN, 1, tag1<SUBNET>>>;
template <template <int, template<typename>class, int, typename> class block, int N, template<typename>class BN, typename SUBNET>
using residual_down = add_prev2<avg_pool<2, 2, 2, 2, skip1<tag2<block<N, BN, 2, tag1<SUBNET>>>>>>;
template <int N, template <typename> class BN, int stride, typename SUBNET>
using block = BN<con<N, 3, 3, 1, 1, relu<BN<con<N, 3, 3, stride, stride, SUBNET>>>>>;
template <int N, typename SUBNET> using ares = relu<residual<block, N, affine, SUBNET>>;
template <int N, typename SUBNET> using ares_down = relu<residual_down<block, N, affine, SUBNET>>;
template <typename SUBNET> using alevel0 = ares_down<256, SUBNET>;
template <typename SUBNET> using alevel1 = ares<256, ares<256, ares_down<256, SUBNET>>>;
template <typename SUBNET> using alevel2 = ares<128, ares<128, ares_down<128, SUBNET>>>;
template <typename SUBNET> using alevel3 = ares<64, ares<64, ares<64, ares_down<64, SUBNET>>>>;
template <typename SUBNET> using alevel4 = ares<32, ares<32, ares<32, SUBNET>>>;
using anet_type = loss_metric<fc_no_bias<128, avg_pool_everything<
alevel0<
alevel1<
alevel2<
alevel3<
alevel4<
max_pool<3, 3, 2, 2, relu<affine<con<32, 7, 7, 2, 2,
input_rgb_image_sized<150>
>>>>>>>>>>>>;
// 定义dlib人脸识别相关变量
frontal_face_detector detector = get_frontal_face_detector();
shape_predictor predictor;
anet_type net;
std::vector<matrix<float, 0, 1>> GetFaceFeature(matrix<rgb_pixel> img)
{
std::vector<matrix<float, 0, 1>> features;
std::vector<dlib::rectangle> dets = detector(img); //用dlib自带的人脸检测器检测人脸,然后将人脸位置大小信息存放到dets中
std::vector<matrix<rgb_pixel>> faces;//定义存放截取人脸数据组
for (auto const& det : dets)
{
auto shape = predictor(img, det);
matrix<rgb_pixel> face_chip;
extract_image_chip(img, get_face_chip_details(shape, 150, 0.25), face_chip);//截取人脸部分,并将大小调为150*150
faces.push_back(move(face_chip));
}
std::vector<matrix<float, 0, 1>> face_descriptors = net(faces);//将150*150人脸图像载入Resnet残差网络,返回128D人脸特征存于face_descriptors
for (auto const& feature : face_descriptors)
{
features.push_back(feature);
}
return features;
}
std::vector<matrix<float, 0, 1>> CreateDataset()
{
std::vector<matrix<float, 0, 1>> vec;
std::vector<string> fileNames = { "data//yangmi.jpeg", "data//zhangjun.JPG", "data//zhaoliying.jpeg", "data//dabai.JPG" };
for (int k = 0; k < fileNames.size(); k++) //依次加载完图片库里的文件
{
matrix<rgb_pixel> img;
cv::Mat image = cv::imread(fileNames[k]);
dlib::assign_image(img, cv_image<rgb_pixel>(image));
std::vector<matrix<float, 0, 1>> features = GetFaceFeature(img);
if (features.size() < 1)
cout << "There is no face" << endl;
else if (features.size() > 1)
cout << "There is to many face" << endl;
else
vec.push_back(features[0]);
}
return vec;
}
std::vector<int> GetLabelIndex(std::vector<matrix<float, 0, 1>> features, std::vector<matrix<float, 0, 1>> predict_value)
{
std::vector<int> id_array;
for (int i = 0; i < predict_value.size(); i++)
{
float min_dis = 10000;
int face_id = -1;
for (int j = 0; j < features.size(); j++)
{
float dis = (float)length(predict_value[i] - features[j]);
if (min_dis > dis)
{
min_dis = dis;
face_id = j;
}
}
if (min_dis > 0.5)
face_id = -1;
id_array.push_back(face_id);
}
return id_array;
}
int CreameraTest()
{
// 创建数据集
std::vector<string> label = { "yangmi", "zhangjun", "yinbao", "dabai" };
std::vector<matrix<float, 0, 1>> vec = CreateDataset();
// 打开摄像头
VideoCapture cap(0);
if (!cap.isOpened())
{
return -1;
}
cv::Mat frame;
bool stop = false;
while (!stop)
{
cap >> frame;
// cv::mat -> dlib::matrix
matrix<rgb_pixel> img;
array2d< bgr_pixel> arrimg(frame.rows, frame.cols);
dlib::assign_image(img, cv_image<rgb_pixel>(frame));
std::vector<dlib::rectangle> dets_test = detector(img);
std::vector<matrix<float, 0, 1>> features;
std::vector<matrix<rgb_pixel>> faces;//定义存放截取人脸数据组
for (auto const& det : dets_test)
{
auto shape = predictor(img, det);
matrix<rgb_pixel> face_chip;
extract_image_chip(img, get_face_chip_details(shape, 150, 0.25), face_chip);//截取人脸部分,并将大小调为150*150
faces.push_back(move(face_chip));
}
std::vector<matrix<float, 0, 1>> face_descriptors = net(faces);//将150*150人脸图像载入Resnet残差网络,返回128D人脸特征存于face_descriptors
for (auto const& feature : face_descriptors)
{
features.push_back(feature);
}
std::vector<int> face_id = GetLabelIndex(vec, features);
string name = "";
for (int const& index : face_id)
{
if (index == -1)
name = "other";
else
name = label[index];
}
// 绘制结果
int font_face = cv::FONT_HERSHEY_COMPLEX;
double font_scale = 1;
int thickness = 2;
int baseline;
//获取文本框的长宽
cv::Size text_size = cv::getTextSize(name, font_face, font_scale, thickness, &baseline);
for (int i = 0; i < dets_test.size(); i++)
{
//将文本框居中绘制
cv::Point origin;
cv::rectangle(frame, cv::Rect(dets_test[i].left(), dets_test[i].top(), dets_test[i].width(), dets_test[i].width()), cv::Scalar(0, 0, 255), 1, 1, 0);//画矩形框
origin.x = dets_test[i].left();
origin.y = dets_test[i].top();
cv::putText(frame, name, origin, font_face, font_scale, cv::Scalar(255, 0, 0), thickness, 2, 0);//给图片加文字
}
imshow("当前视频", frame);
if (waitKey(30) >= 0)
stop = true;
}
return 0;
}
int main()
{
deserialize("model//shape_predictor_68_face_landmarks.dat") >> predictor;
deserialize("model//dlib_face_recognition_resnet_model_v1.dat") >> net;
CreameraTest();
return 0;
}
数据集的照片:
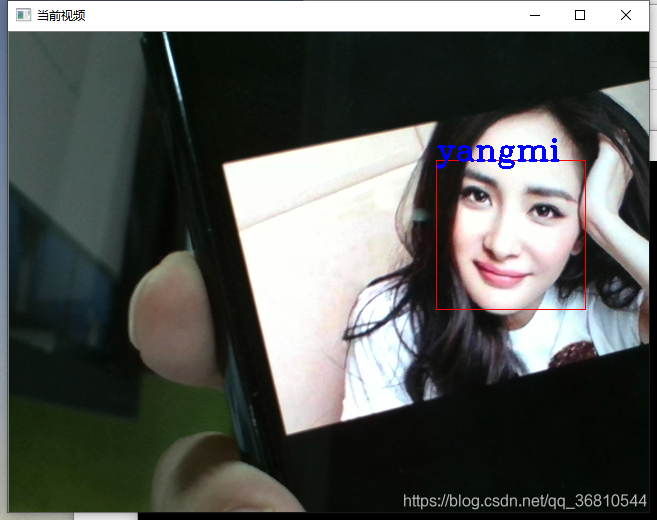
运行截图:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









