







目录
1.人工智能、机器学习与深度学习
1 人工智能与机器学习
- 人工智能分类:强人工智能、弱人工智能、超级人工智能
- 机器学习分类:有监督学习、无监督学习、强化学习
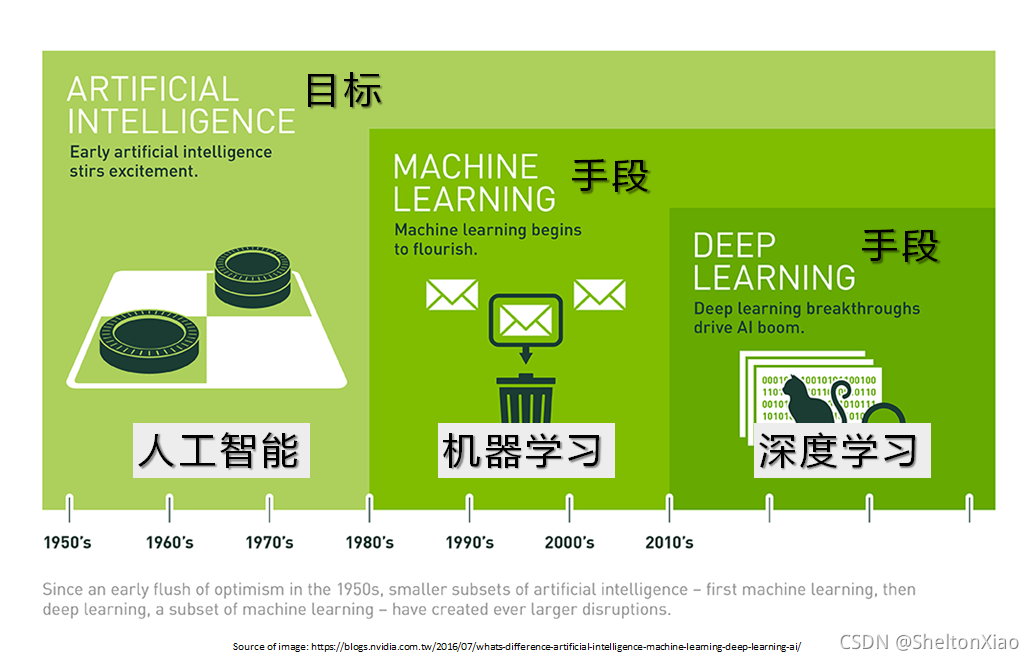
人工智能,机器学习和深度学习的关系如下图所示:
1.2 起源与发展
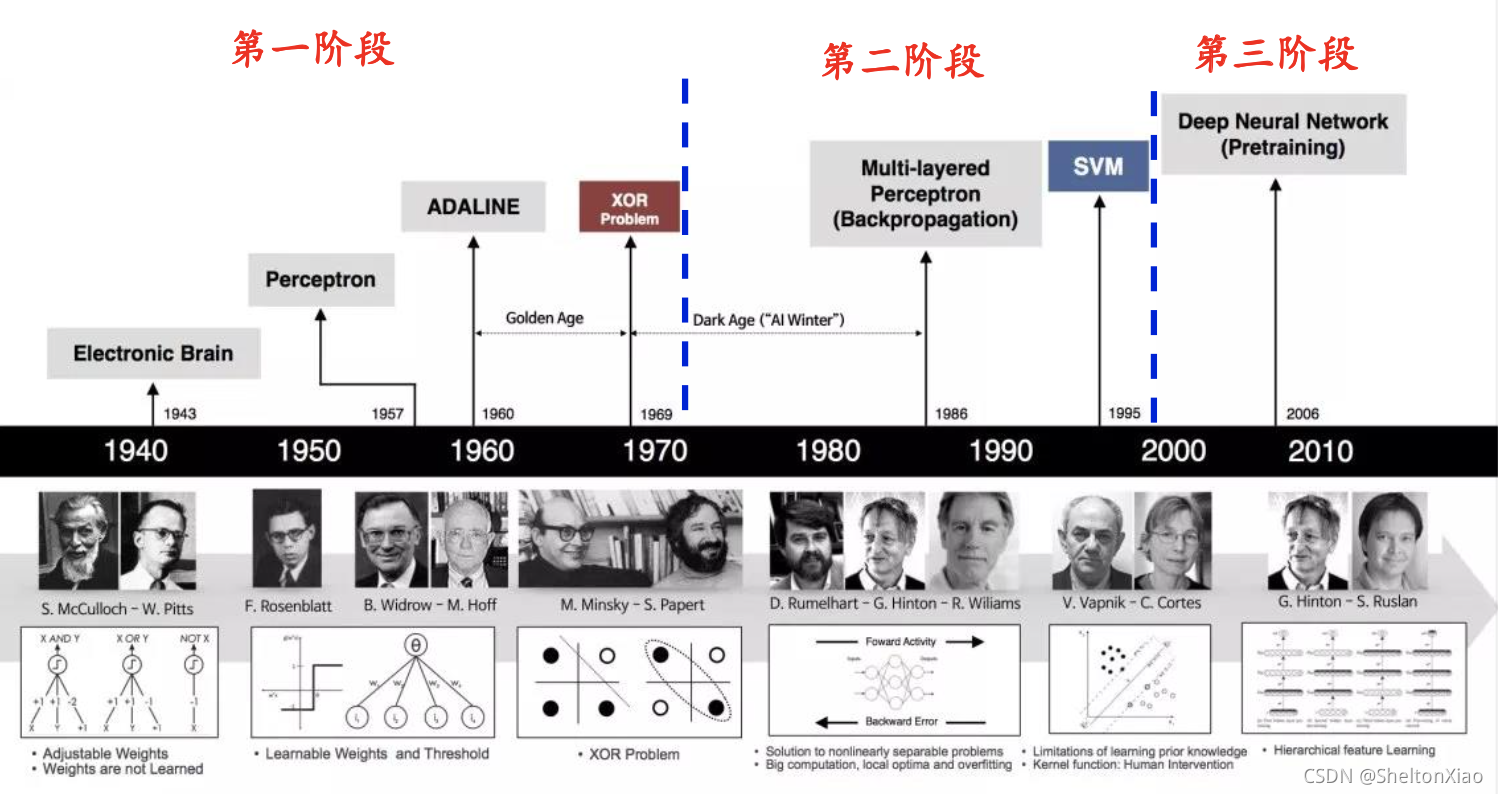
- 第1阶段:提出MP神经元模型、感知器、ADLINE神经网络,并指出感知器只能解决简单的线性分类任务,无法解决XOR简单分类问题
- 第2阶段:提出Hopfiled神经网络、误差反向传播算法、CNN
- 第3阶段:提出深度学习概念,在语音识别、图像识别的应用
1.3 深度学习定义与分类
- 定义:采用多层网络结构对未知数据进行分类或回归
- 分类:
- 有监督学习:深度前馈网络、卷积神经网络、循环神经网络等
- 无监督学习:深度信念网、深度玻尔兹曼机、深度自编码器等
1.4 主要应用
- 图像处理领域:图像分类、物体检测、图像分割、图像回归
- 语音识别领域:语音识别、声纹识别、语音合成
- 自然语音处理领域:语言模型、情感分析、神经机器翻译、神经自动摘要、机器阅读理解、自然语言推理
- 综合应用:图像描述、可视回答、图像生成、视频生成
2 深度学习数学基础
主要涵盖四个部分:矩阵论,概率统计,信息论,和最优化估计。
2.1 矩阵论
- 张量:标量是0阶张量,矢量是1阶张量,矩阵是2阶张量,三维及以上数组称为张量
- 矩阵的秩(Rank):矩阵向量中的极大线性无关组的数目
- 矩阵的逆:
- 奇异矩阵:rank(A_{n×n})<nrank(An×n)<n
- 非奇异矩阵:rank(A_{n×n})=nrank(An×n)=n
- 广义逆矩阵:如果存在矩阵BB使得ABA=AABA=A,则称BB为AA的广义逆矩阵
- 矩阵分解:
- 特征分解:A = U\Sigma U^{T}A=UΣUT
- 奇异值分解:A = U \Sigma V^{T}A=UΣVT、U^T U = V^T V = IUTU=VTV=I
2.2 概率统计
-
随机变量:
- 分类:离散随机变量、连续随机变量
- 概念:用概率分布来指定它的每个状态的可能性
常见的随机变量的概率分布如下:
离散型随机变量
连续型随机变量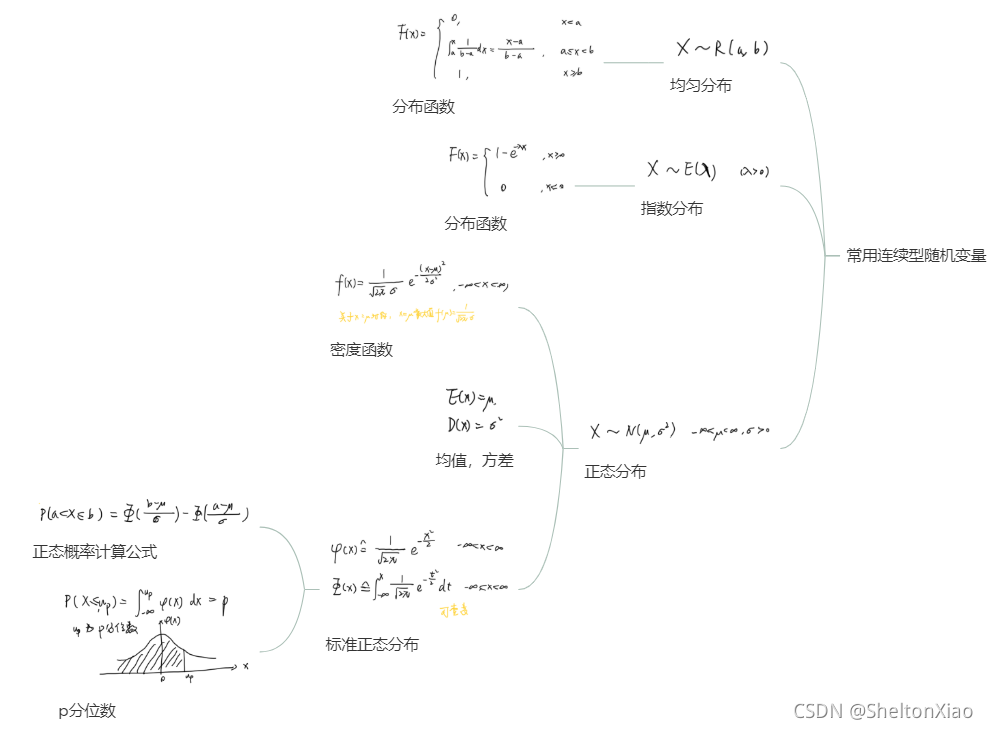
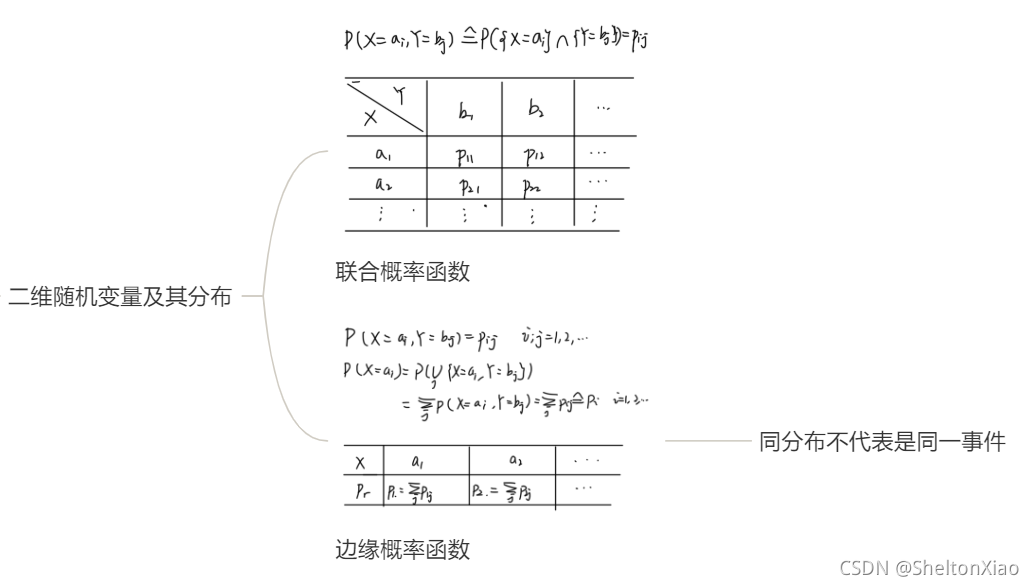
多个变量时,概率分布会有不同
-
条件概率

-
联合概率
-
先验概率
-
后验概率
-
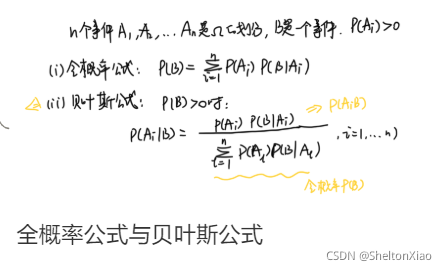
全概率公式
-
贝叶斯公式
常用统计量为
-
方差

-
协方差

2.3 信息论
-
熵:样本集纯度指标,或样本集报班的平均信息量
H(X) = - \sum_{i = 1}^n P(x_i) \log_2 P(x_i)H(X)=−i=1∑nP(xi)log2P(xi) -
联合熵:度量二维随机变量XYXY的不确定性
H(X, Y) = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i, y_j) \log_2 P(x_i, y_j)H(X,Y)=−i=1∑nj=1∑nP(xi,yj)log2P(xi,yj) -
条件熵:
\begin{aligned} H(Y|X) &= \sum_{i = 1}^n P(x_i) H(Y|X = x_i) \\ &= -\sum_{i = 1}^n P(x_i) \sum_{j = 1}^n P(y_j | x_i) \log_2 P(y_j | x_i) \\ &= -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i, y_j) \log_2 P(y_j | x_i) \end{aligned}H(Y∣X)=i=1∑nP(xi)H(Y∣X=xi)=−i=1∑nP(xi)j=1∑nP(yj∣xi)log2P(yj∣xi)=−i=1∑nj=1∑nP(xi,yj)log2P(yj∣xi) -
互信息:
I(X;Y) = H(X)+H(Y)-H(X,Y)I(X;Y)=H(X)+H(Y)−H(X,Y) -
相对熵:又称KL散度,描述两个概率分布PP和QQ差异,用概率分布QQ拟合真实分布PP时,产生的信息表达损耗
- 离散形式:\displaystyle D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)}D(P∣∣Q)=∑P(x)logQ(x)P(x)
- 连续形式:\displaystyle D(P||Q) = \int P(x)\log \frac{P(x)}{Q(x)}D(P∣∣Q)=∫P(x)logQ(x)P(x)
-
交叉熵:目标与预测值之间的差距
\begin{aligned} D(P||Q) &= \sum P(x)\log \frac{P(x)}{Q(x)} \\ &= \sum P(x)\log P(x) - \sum P(x)\log Q(x) \\ &= -H(P(x)) -\sum P(x)\log Q(x) \end{aligned}D(P∣∣Q)=∑P(x)logQ(x)P(x)=∑P(x)logP(x)−∑P(x)logQ(x)=−H(P(x))−∑P(x)logQ(x)
2.4 最优化估计
- 最小二乘估计:采用最小化误差的平方和,用于回归问题。
- 最小二乘估计又称最小平方法,是一种数学优化方法。它通过最小化误差的平方和寻找数据的最佳函数匹配。最小二乘法经常应用于回归问题,可以方便地求得未知参数,比如曲线拟合、最小化能量或者最大化熵等问题。
线性代数
- 标量(scalar):一个标量就是一个单独的数。
- 向量(vector):一个向量是一列数。
- 矩阵(matrix):矩阵是一个二维数组,其中的每一个元素被两个索引所确定。
- 张量(tensor):一个数组中的元素分布在若干维坐标的规则网络中,称之为张量。
- 转置(transpose):矩阵的转置是以主对角线为轴的镜像。
- 单位矩阵(identity matrix):所有沿主对角线的元素都是1,所有其他位置的元素都是0.
- 对角矩阵(diagonal matrix):只在主对角线上含有非零元素,其他位置都是0。
- 正交矩阵(orthogonal matrix):行向量和列向量分别标准正交的方阵。
- 正定(positive definite):矩阵所有特征值都是正数。
- 半正定(positive semidefinite):矩阵所有特征值都是非负数。
- 负定(negative definite):矩阵所有特征值都是负数。
- 半负定(negative semidefinite):矩阵所有特征值都是非正数。
- 矩阵的秩(rank):矩阵列向量中的极大线性无关组的数目,记作矩阵的列秩,同样可以定义行秩。行秩=列秩=矩阵的秩,通常记作rank(A)。

















 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











