







一、正则化与偏差—方差分解
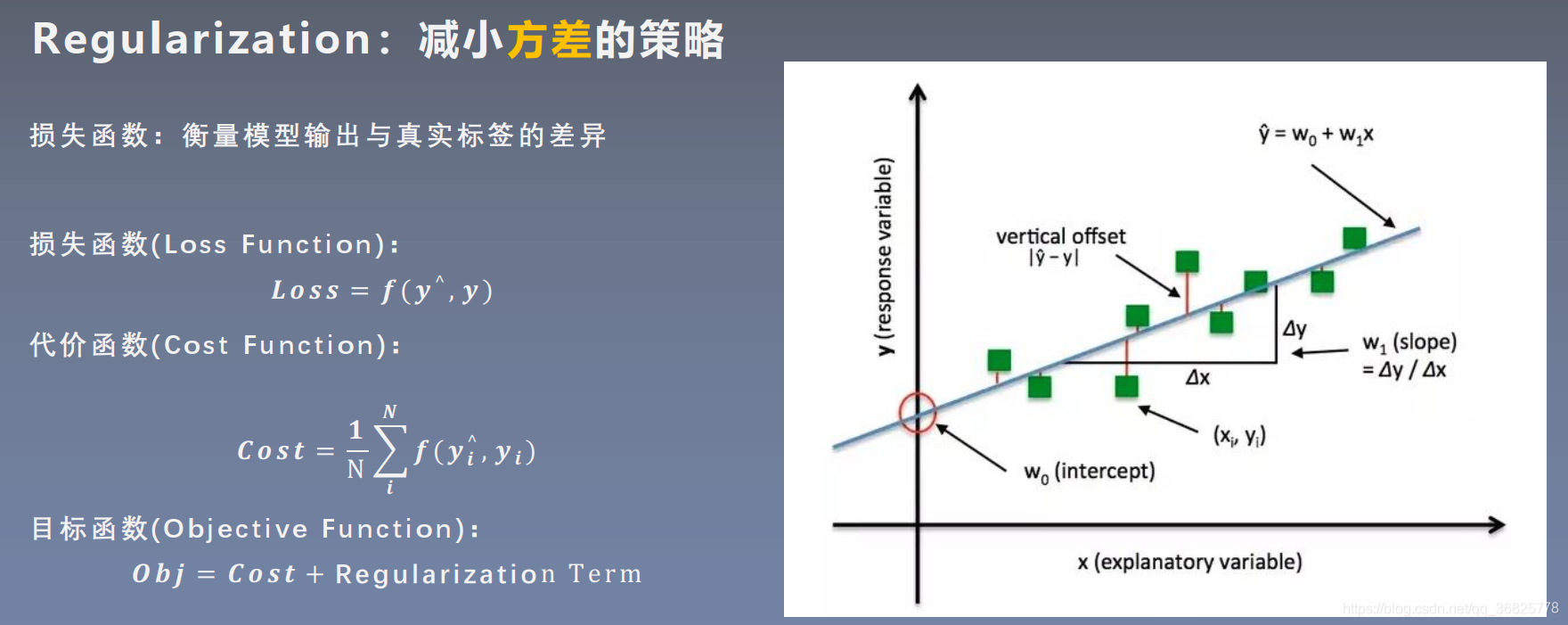
Regularization: 减小方差的策略
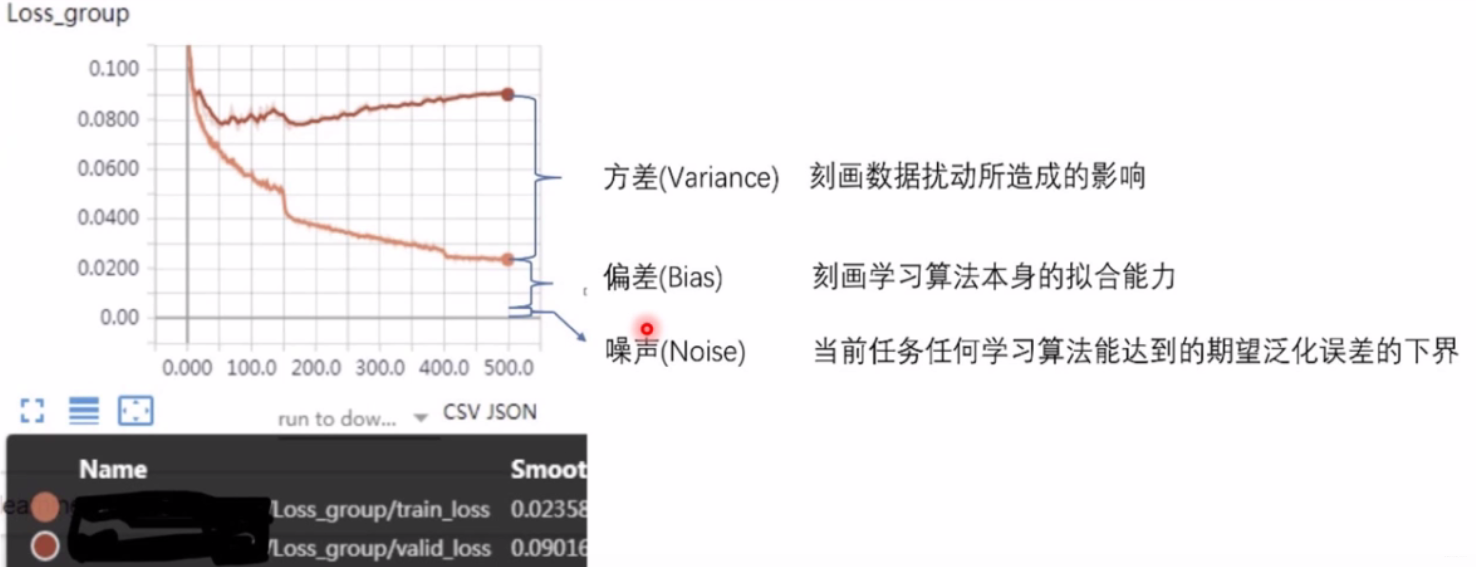
误差可分解为:偏差,方差与噪声之和。即误差=偏差+方差+噪声之和
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界
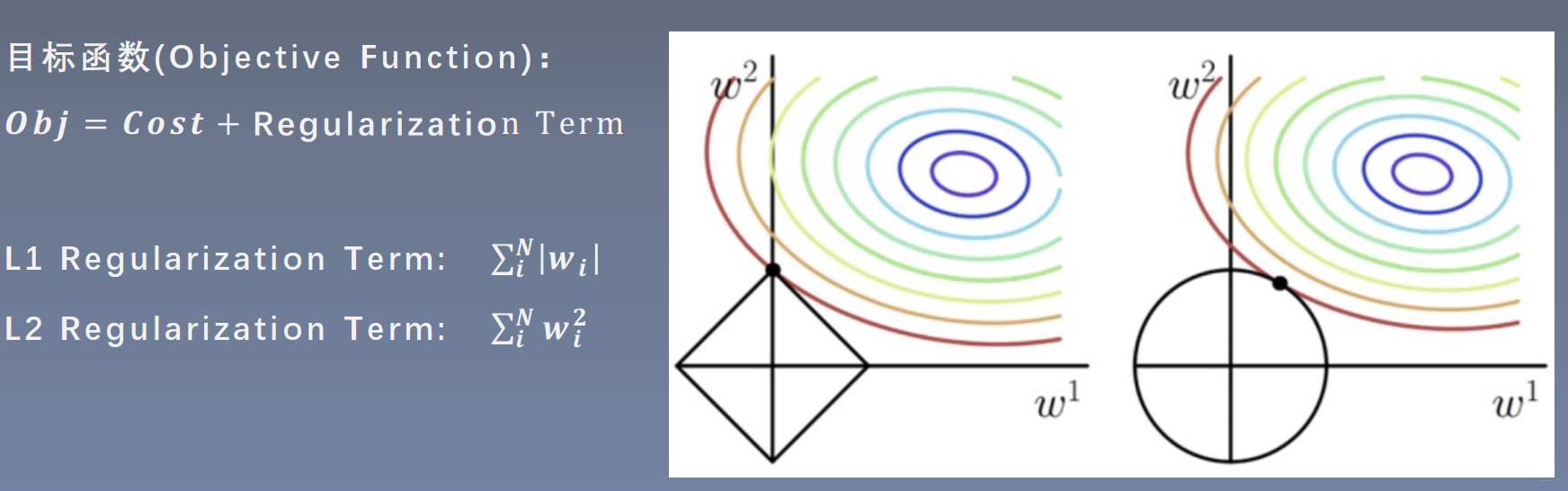
L1正则化:
加上L1正则项,目标函数需要同时满足cost和正则项都要小,如上图所示,w1和w2所满足的区域和cost的曲线相交点才能满足所需,而交点处于坐标轴,则w1=0,即参数解会产生稀疏项
L2正则化:
同样的,当cost值固定,如图中红色曲线,w1和w2的曲线与红色曲线的相交处,就是使得总体目标函数最小的位置
经过L1和L2正则化,参数值比较小,从而使得模型不会过于复杂
二、pytorch中的L2正则项——weight decay
2.1 权值衰减概念
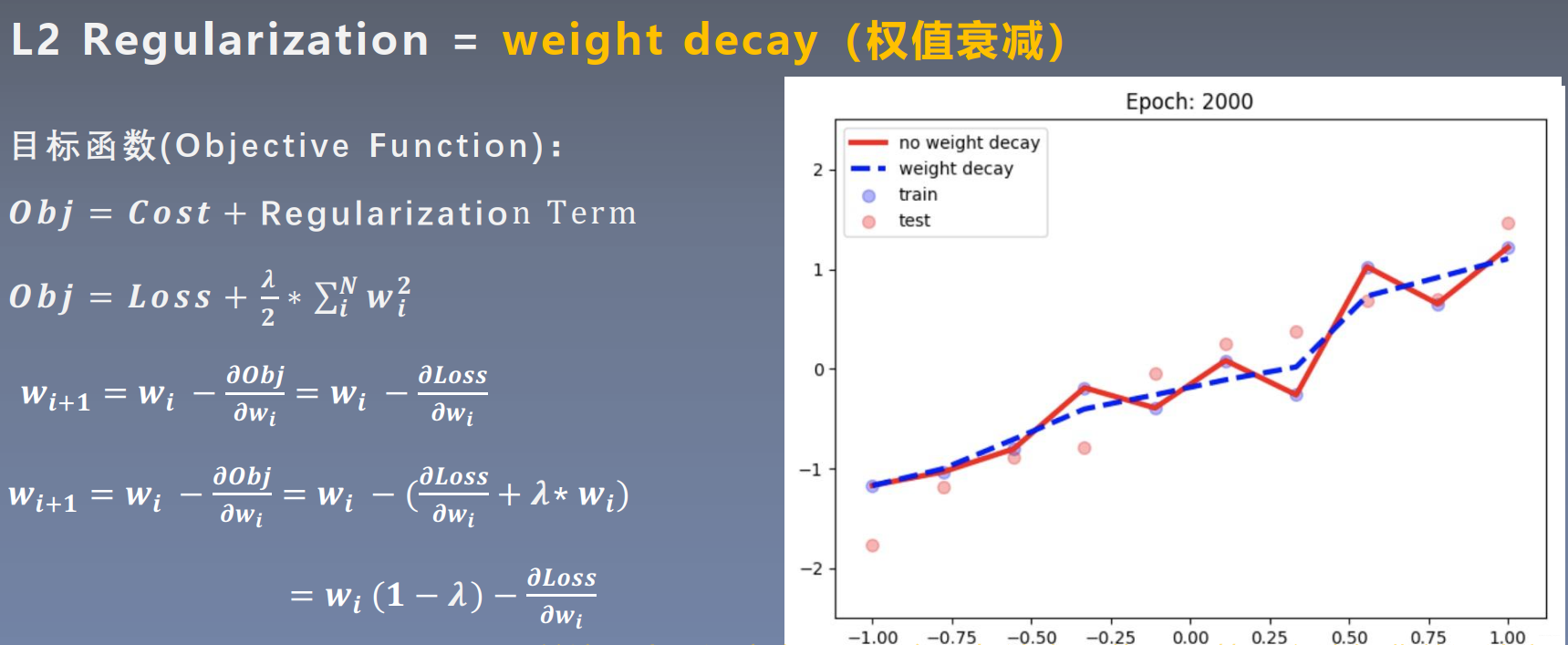
说明:
- λ \lambda λ是超参, 0 < λ < 1 0 < \lambda < 1 0<λ<1,用于调和loss和正则项的比例
- 1/2是用于方便求导
权值衰减:
从上图可知,加上L2正则化项后,w的更新公式中,wi乘以了一个小于1的正数,因此权值会发生衰减,故L2正则化也叫做权值衰减
2.2 L2正则化测试
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from tools.common_tools import set_seed
from torch.utils.tensorboard import SummaryWriter
set_seed(1) # 设置随机种子
n_hidden = 200
max_iter = 2000
disp_interval = 200
lr_init = 0.01
# ============================ step 1/5 数据 ============================
def gen_data(num_data=10, x_range=(-1, 1)):
w = 1.5
train_x = torch.linspace( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5285
5285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









