







Python爬虫详解:爬虫是什么,如何做爬虫?
读前必看:
本篇文章为教学向文章,通俗易懂的语言难免有不合适的地方,请大佬自行退场
爬虫是什么?
去查网,你会看到这样的解释:
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本
这看起来很晦涩难懂,让我用通俗易懂的语言来解释一下:
爬虫是可以把网上的东西给你的程序,你想要的东西
废话不多说,我们打开python开始编
爬虫是怎么把你想要的东西给你的?
这里我们爬一爬B站的首页上的图片吧
第一步.得到所有的链接
首先爬虫要拿到链接,在这里我们要用到的模块是requests
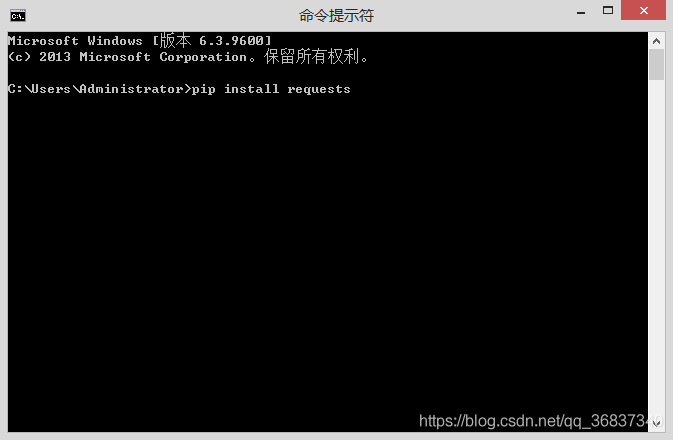
requests是一个第三方库,这里我们要下载这个库
打开cmd,直接输入pip install requests就好了
然后导入模块
import requests
接下来把你要爬的网址写成变量,这里拿B站举例
import requests
url = "http://www.bilibili.com"
然后告诉机器你要爬这个网址,并把爬下来的数据写在变量里
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
完事,这样机器就得到了网上的数据,就这么简单
接下来就该把你想要数据给你了
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text #把数据转为文本形式
切记!!! 一定要把数据转化成文本形式,不然返回的只是请求值
我们打印一下看看
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text
print(html)
返回值:
<!DOCTYPE html><html lang="zh-CN"><head><meta charset="utf-8"><title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title><meta name="description" content="bilibili是国内知名的视频弹幕网站,这里有最及时的动漫新番,最棒的ACG氛围,最有创意的Up主。大家可以在这里找到许多欢乐。"><meta name="keywords" content="Bilibili,哔哩哔哩,哔哩哔哩动画,哔哩哔哩弹幕网,弹幕视频,B站,弹幕,字幕,AMV,MAD,MTV,ANIME,动漫,动漫音乐,游戏,游戏解说,二次元,游戏视频,ACG,galgame,动画,番组,新番,初音,洛天依,vocaloid,日本动漫,国产动漫,手机游戏,网络游戏,电子竞技,ACG燃曲,ACG神曲,追新番,新番动漫,新番吐槽,巡音,镜音双子,千本樱,初音MIKU,舞蹈MMD,MIKUMIKUDANCE,洛天依原创曲,洛天依翻唱曲,洛天依投食歌,洛天依MMD,vocaloid家族,OST,BGM,动漫歌曲,日本动漫音乐,宫崎骏动漫音乐,动漫音乐推荐,燃系mad,治愈系mad,MAD MOVIE,MAD高燃"><meta name="renderer" content="webkit"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="spm_prefix" content="333.851"><link rel="dns-prefetch" href="//s1.hdslb.com"><script type="text/javascript">function getIEVersion(){var e=99;if("Microsoft Internet Explorer"==navigator.appName){var t=navigator.userAgent;null!=new RegExp("MSIE ([0-9]{1,}[.0-9]{0,})").exec(t)&&(e=parseFloat(RegExp.$1))}return e}getIEVersion()<11&&(window.location.href="https://www.bilibili.com/blackboard/activity-I7btnS22Z.html")</script><script type="text/javascript">!function(){for(var ......
一千多行!
花花绿绿的都是链接和代码
对,我们要的就是链接
接下来怎么找图片的链接呢?
第二步.找图片链接
为了教学,不用正则表达式
首先得把他们分开
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text
list_html = html.split('"')
如果要让机器提取B站图片链接
那就得让他知道B站图片链接长啥样
B站图片链接长这样:
http://i0.hdslb.com/bfs/archive/0bf1a101af3a0014def2a3978ff68101c7002106.jpg
http://i1.hdslb.com/bfs/face/f0de237671f10a9ef735636250ca89bd50c180fb.jpg
看看它们有什么特点
他们都是http协议的链接
他们一定有"hdslb.com"
他们的后缀是".jpg"
那么我们就可以开干了!
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text
list_html = html.split('"')
urls = []
for i in list_html:
if "http://" in i:
if "hdslb.com" in i and ".jpg" in i:
urls.append(i)
写个for循环依次检查每个链接是不是我们要找的链接
如果是就加进列表里
打印一下看看
['https://i0.hdslb.com/bfs/sycp/creative_img/202007/d07403ce674fb827c654006f44380879.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/d1b177d716d28038dfde1f7677ca0dbb.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/d1b177d716d28038dfde1f7677ca0dbb.jpg@412w_232h_1c_100q.jpg', 'http://i2.hdslb.com/bfs/face/6de7150ba0e78a33860538da88a6c5b787024579.jpg', 'http://i0.hdslb.com/bfs/archive/589488d99e16347892f94d56ec6e179843198318.jpg', '//i0.hdslb.com/bfs/archive/589488d99e16347892f94d56ec6e179843198318.jpg@412w_232h_1c_100q.jpg', 'http://i0.hdslb.com/bfs/face/34d7ccfe7fbfe16e2e764b7bd543d1bb566ff208.jpg', 'http://i0.hdslb.com/bfs/archive/cacb9830431d35e543438aef602900c8d911960f.jpg', '//i0.hdslb.com/bfs/archive/cacb9830431d35e543438aef602900c8d911960f.jpg@412w_232h_1c_100q.jpg', 'http://i0.hdslb.com/bfs/face/1a2554b2b54c17694fb7aa37900b28f7b7c96449.jpg', 'http://i0.hdslb.com/bfs/archive/f9c64dcf5d383b8340c1a237f8ea4d4a9dcef00e.jpg', '//i0.hdslb.com/bfs/archive/f9c64dcf5d383b8340c1a237f8ea4d4a9dcef00e.jpg@412w_232h_1c_100q.jpg', 'http://i0.hdslb.com/bfs/face/569dec5aeab5ad650ecdee0c1d8965512d32657c.jpg', 'http://i0.hdslb.com/bfs/archive/3c8bad9fb462fe76f2d8644a08ec3296ba932804.jpg', '//i0.hdslb.com/bfs/archive/3c8bad9fb462fe76f2d8644a08ec3296ba932804.jpg@412w_232h_1c_100q.jpg', 'http://i0.hdslb.com/bfs/face/1aa5fb297a1dafee8c12c809bed7eb9e8059a929.jpg', 'http://i0.hdslb.com/bfs/archive/1bd5e2c9c6d49df89a5e1d96ca7c7715c37a210c.jpg', '//i0.hdslb.com/bfs/archive/1bd5e2c9c6d49df89a5e1d96ca7c7715c37a210c.jpg@412w_232h_1c_100q.jpg', 'http://i2.hdslb.com/bfs/face/26c84ebb81c5bd1c1381bd75090bd7e39e0535fd.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/2cd187b3d851c2cb0906d12bfaa868d3.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/fc81f5f324f6f44a233272dd5c1e9f65.jpg', 'http://i0.hdslb.com/bfs/archive/28b001cd91e5b900f02bca8c93dfd1de609e8cfe.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/e2f0bd3a91bcadcd0d1a31c0cada55d1.jpg', 'http://i0.hdslb.com/bfs/archive/ab80cfa04e04a5a3e7e0c2604d2958b094f72e03.jpg', 'http://i0.hdslb.com/bfs/archive/a8144c19e221e3aca37c4c4baff31de0770f10db.jpg', 'http://i0.hdslb.com/bfs/archive/d348642d611e98021c4c13c30cf5b588a9cf5abb.jpg', 'http://i0.hdslb.com/bfs/archive/bb5f66e5f61d6b626fac43897fb9dd03c257820c.jpg', 'http://i0.hdslb.com/bfs/archive/bb5f66e5f61d6b626fac43897fb9dd03c257820c.jpg', 'http://i0.hdslb.com/bfs/face/cb620bbb9071974f37843134875d472b47532a97.jpg', 'http://i0.hdslb.com/bfs/archive/becf9e8d300838b7310bd26a7ddb25c627225a09.jpg', 'http://i2.hdslb.com/bfs/archive/becf9e8d300838b7310bd26a7ddb25c627225a09.jpg', 'http://i0.hdslb.com/bfs/face/cb620bbb9071974f37843134875d472b47532a97.jpg', '
OHHHHHHHHHH!!!
可是里面有好多重复的,这没关系
我们再改改
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text
list_html = html.split('"')
urls = []
for i in list_html:
if "http://" in i:
if "hdslb.com" and ".jpg" in i:
urls.append(i)
photo_urls = []
for i in urls:
if i not in photo_urls:
photo_urls.append(i)
返回
['https://i0.hdslb.com/bfs/sycp/creative_img/202007/d07403ce674fb827c654006f44380879.jpg', 'https://i0.hdslb.com/bfs/sycp/creative_img/202007/d1b177d716d28038dfde1f7677ca0dbb.jpg@412w_232h_1c_100q.jpg', 'http://i2.hdslb.com/bfs/face/6de7150ba0e78a33860538da88a6c5b787024579.jpg', 'http://i0.hdslb.com/bfs/archive/589488d99e16347892f94d56ec6e179843198318.jpg', '//i0.hdslb.com/bfs/archive/589488d99e16347892f94d56ec6e179843198318.jpg@412w_232h_1c_100q.jpg', 'http://i0.hdslb.com/bfs/face/34d7ccfe7fbfe16e2e764b7bd543d1bb566ff208.jpg', 'http://i0.hdslb.com/bfs/archive/cacb9830431d35e543438aef602900c8d911960f.jpg'
这下好了
第三步.保存
用with open的写入模式保存二进制数据:
import requests
url = "http://www.bilibili.com"
html = requests.get(url)
html = html.text
list_html = html.split('"')
urls = []
for i in list_html:
if "http://" in i:
if "hdslb.com" and ".jpg" in i:
urls.append(i)
photo_urls = []
for i in urls:
if i not in photo_urls:
photo_urls.append(i)
cnt = 0
for i in photo_urls:
cnt += 1
img = requests.get(i)
with open("Photo_{}.jpg".format(cnt),"wb") as f:
f.write(img.content)
完成!
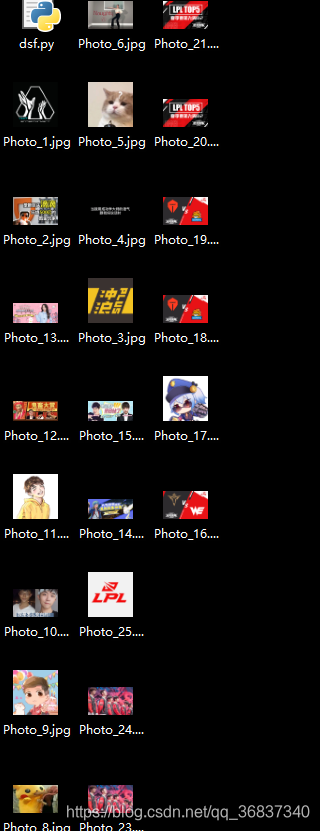
成果展示:
免责声明:如果文章中内任何图片或链接等信息侵权,请联系作者删除!
作者:Azure
绝对原创,只在CSDN发布,如见其他盗文敬请举报!















 2211
2211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









