







博文写于2020-05-10,于2020-07-07再次编辑
1.一个小小的引子:
写这篇博文的时候,日子有点特殊,啥日子大家应该都知道。用一篇某高二学生母亲节的英语作文,先祝天下所有母亲身体健康,母亲节快乐。
Mother's Day
There is no doubt that mother is the greatest person in the world. She gives me life and takes care of me
all the time. It is natural to have a day to show the great respect to our mothers, so people named a day
as Mother's Day in the second Sunday of May. At this meaningful day, people find some specila ways to
express gratitude.
Mother's Day gives people a chance to express their gratityde to their mothers and it is important to do
so. My parents are traditional and they don't often say words about love, but the things they do for me are
never less. When I went to middle school, my classmates sent messagses to their mothers or just gave a call
on Mother's Day, until then I realized I must do something for my mother. So I borrowed my friend's phone
and sent a message to my mom, telling her that I loved her. Later, my father told me that mom was really happy.
Every small act we do for our mothers will touch them deeply. If we can’t make her happy every day, at least
let her know how much we love her.
这词汇量,这英语功底,这言语润色,高中时代的我和Ta相比,简直自惭形秽,现在的我和Ta相比,算了还是别比了。but,英语词汇量多+眼尖的同学有没有发现其中有单词拼写错了(虽然你可能没看,看了也可能没发现#滑稽脸)。毕竟:研表究明,汉字的序顺并不定一能影阅响读,这是因为人一次并不是只取读一个汉字。普通人精读一段文字的时候,一次凝视大约读取1.5个词。这段话你都能顺顺当当的读完,何况更是一篇英语作文中有一些错误拼写呢。
其实我看的时候也没发现,只是通过其他方式发现了而已....不对,是我故意把单词改错的,所以我很清楚哪个位置,哪个单词错在哪。
2.本文适宜读者范围:
还有:
此段落和文章标题相互呼应,点名主旨......点明失败,首先文章主旨不明确 。
3.文章主旨:
好了,东扯西扯,是扯不完的,言归正传,文章主旨就是实现一个基于朴素贝叶斯的文章单词检查拼写器,这东西你肯定也用过,有点类似
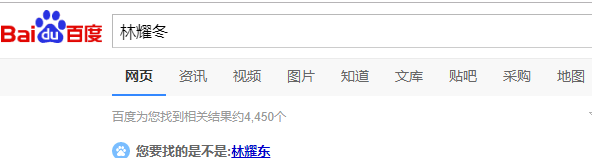
只不过咱们这个只针对英文单词,最终实现效果:
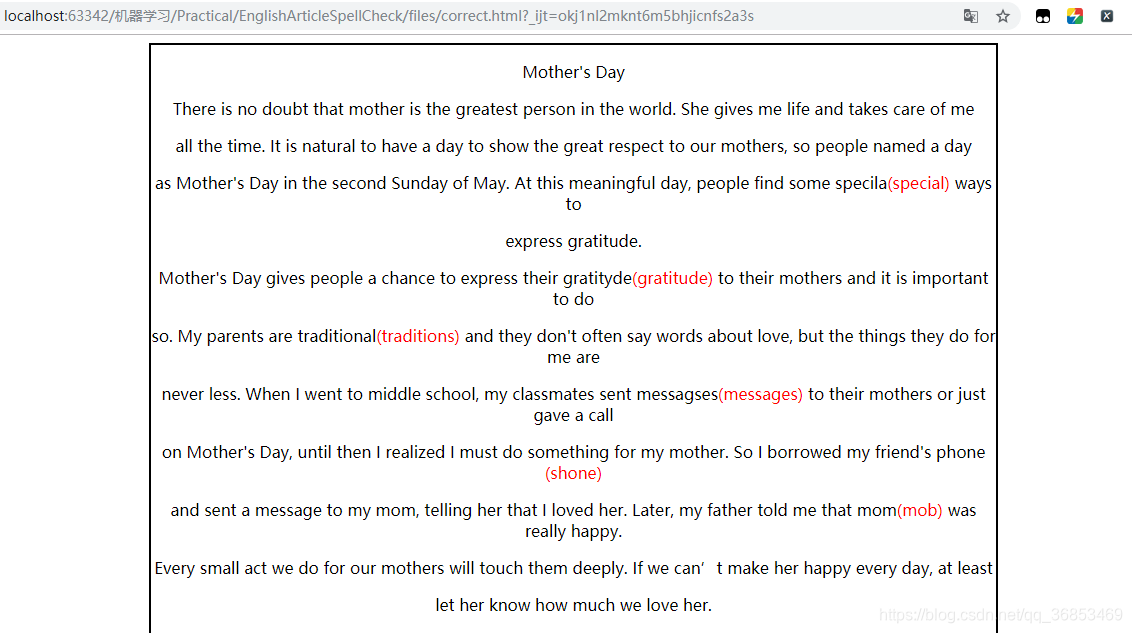
效果讲解:在错误单词或疑似错误单词之后追加显示正确单词,并以网页的形式,将正确单词高亮显示,便于用户修改。
4.朴素贝叶斯:
关于朴素贝叶斯公式,详细一点的参考博文 朴素贝叶斯算法及其实战。这里不细说,初略过一下,因为鲁迅先生说过:文章每多一个公式,就会少一个读者
又又又又双叒叕带偏大家了,这话貌似是霍金说的。
全文唯一的一个公式:

其中:
P(A):文章出现正确拼写词A的概率,程序中直接用词频表示,即(词A总数 / 所有词总词数)
P(B|A):用户把词A错敲成B的概率
为了便于大家理解:举个之前文章中的例子:
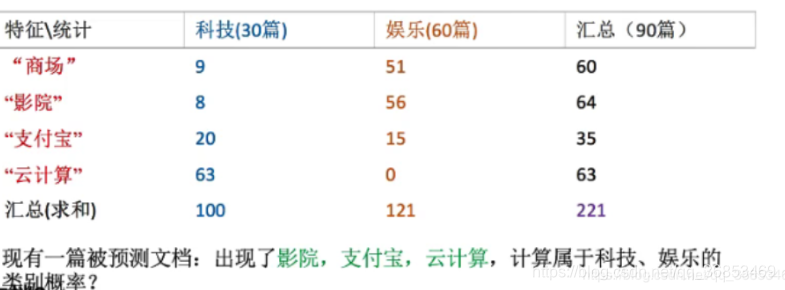
科技:
P(科技|影院,支付宝,云计算) = P(影院,支付宝,云计算|科技)*P(科技)
=(8/100)*(20/100)*(63/100)*(30/90)
= 126 / 37500
≈ 0.0036
娱乐:
P(娱乐|影院,支付宝,云计算) = P(影院,支付宝,云计算|娱乐)*P(娱乐)
= (56/232)*(25/122)*(0/121)*(60/90)
= 0 5. 文章单词纠错器的主要逻辑与代码实现:
5.1 从文件中逐步逐行读取内容,分割:
with open(self.filePath, encoding="utf-8", errors="ignore") as f:
text = f.readlines()
for lines in text:
wordsList = lines.split(" ") # 根据空格划分单词
for oldWord in wordsList:
# 和标点链接的单词,先略过了,待优化!!!
if '"' in oldWord or "'" in oldWord or "." in oldWord or "," in oldWord: # Jason's or Jason: or Jason.
pass
else:
if not oldWord or oldWord == "\n" or oldWord == "\t":
pass
else:
rightWord = self.check(oldWord.replace("\r", "").replace("\n", "").replace("\t", ""))
if rightWord not in oldWord:
oldWord += '<span class="highlighted">(' + rightWord + ')</span>' #将错误单词在html中高亮显示
print("原单词:", oldWord, " 你可能需要的单词为:", rightWord)
newLines.append(oldWord)
with open("./files/correct.html", "a", encoding="utf-8") as f:
f.write("<p>" + " ".join(newLines) + "</p>") # 空格为界限拼接单词
newLines = [] #每写入一次需要将newLines置空5.2 所读取单词拼写检查:
提取出big.txt的所有单词,并且计算它们出现的次数,再除以单词总数作为该词的频率P(A),存储方式为字典格式:
def train(self):
'''
:return: 词频构成的字典 {key:value} key:word value:countNum
'''
text = open(self.bigtxtPath, 'r', encoding='utf-8').read()
allWords = re.findall('[A-Za-z]+', text) #匹配出所有英文单词
result = collections.defaultdict(lambda: 1)
for word in allWords:
result[word] += 1
return result对输入的单词在词典里进行匹配,至少0次编辑,最多2次编辑,找出编辑距离最小的
def edit_first(self, word):
"""
只编辑一次就把一个单词变为另一个单词
:return: 所有与单词word编辑距离为1的集合
"""
length = len(word)
return set([word[0:i] + word[i + 1:] for i in range(length)] + # 从头至尾,依次将word中删除一个字母,构成一个新单词
[word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(length - 1)] + # 从头至尾,依次将word中相邻的两个字母调换顺序,构成一个新单词
[word[0:i] + c + word[i + 1:] for i in range(length) for c in self.alphabet] + # 从头至尾,依次将word中的一个字母进行修改
[word[0:i] + c + word[i:] for i in range(length + 1) for c in self.alphabet]) # 从头到尾,依次在word中插入一个字母
def edit_second(self, word):
"""
编辑两次的集合
:return:
"""
words = self.train()#得到存放着所有单词词频的字典
return set(e2 for e1 in self.edit_first(word) for e2 in self.edit_first(e1) if e2 in words)
def already_words(self, word):
"""
返回已知的和错误单词相近的正确单词集合,允许进行两次编辑
:return:
"""
words = self.train()
return set(w for w in word if w in words)当编辑距离为最小的不止一个时,找出所有单词里的概率最大的作为返回输出层
def check(self, word):
words = self.train()
#输入的单词是否在字典中 一次编辑的单词是否在字典中 二次编辑的单词是否在字典中
neighborhood = self.already_words([word]) \
or self.already_words(self.edit_first(word)) \
or self.already_words(self.edit_second(word)) \
or [word]
# 取概率最大的正确单词,即词频最多的
return max(neighborhood, key=lambda w: words[w])5.3 纠正后展示部分: 即将文章展示到html中
最初的想法是利用JavaScript动态追加,后面发现直接静态写死或许会简单点,最终:
with open("./files/correct.html", "w+", encoding="utf-8") as f:
f.write('''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文章错误单词高亮显示</title>
<style>
body{ text-align:center}
.show{ margin:0 auto; width:60%; height:100%; border:2px solid}
.highlighted{color:red;display:inline-block;}
/* css注释:为了观察效果设置宽度 边框 高度等样式 */
</style>
</head>
<body>
<div class="show">
''') with open("./files/correct.html", "a", encoding="utf-8") as f:
f.write("<p>" + " ".join(newLines) + "</p>") # 空格为界限拼接单词
newLines = [] #每写入一次需要将newLines置空
finally:
with open("./files/correct.html", "a", encoding="utf-8") as f:
f.write('''
</div>
</body>
</html>
''')
6.总体代码:
# -*- coding: UTF-8 -*-
'''
@Author :Jason
Version3.0:read .txt files
'''
import re,collections
class SpellCheck(object):
def __init__(self,filePath):
self.alphabet = list('abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ')
self.filePath = filePath
self.bigtxtPath = "./files/big.txt"
def train(self):
'''
:return: 词频构成的字典 {key:value} key:word value:countNum
'''
text = open(self.bigtxtPath, 'r', encoding='utf-8').read()
allWords = re.findall('[A-Za-z]+', text) #匹配出所有英文单词
result = collections.defaultdict(lambda: 1)
for word in allWords:
result[word] += 1
return result
def edit_first(self, word):
"""
只编辑一次就把一个单词变为另一个单词
:return: 所有与单词word编辑距离为1的集合
"""
length = len(word)
return set([word[0:i] + word[i + 1:] for i in range(length)] + # 从头至尾,依次将word中删除一个字母,构成一个新单词
[word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(length - 1)] + # 从头至尾,依次将word中相邻的两个字母调换顺序,构成一个新单词
[word[0:i] + c + word[i + 1:] for i in range(length) for c in self.alphabet] + # 从头至尾,依次将word中的一个字母进行修改
[word[0:i] + c + word[i:] for i in range(length + 1) for c in self.alphabet]) # 从头到尾,依次在word中插入一个字母
def edit_second(self, word):
"""
编辑两次的集合
:return:
"""
words = self.train()#得到存放着所有单词词频的字典
return set(e2 for e1 in self.edit_first(word) for e2 in self.edit_first(e1) if e2 in words)
def already_words(self, word):
"""
返回已知的和错误单词相近的正确单词集合,允许进行两次编辑
:return:
"""
words = self.train()
return set(w for w in word if w in words)
def check(self, word):
words = self.train()
#输入的单词是否在字典中 一次编辑的单词是否在字典中 二次编辑的单词是否在字典中
neighborhood = self.already_words([word]) \
or self.already_words(self.edit_first(word)) \
or self.already_words(self.edit_second(word)) \
or [word]
# 取概率最大的正确单词,即词频最多的
return max(neighborhood, key=lambda w: words[w])
def main(self):
'''
主函数,对文档单词进行检查
:return:None
'''
newLines = [] # 用于存放纠正后的一行文本
with open("./files/correct.html", "w+", encoding="utf-8") as f:
f.write('''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>文章错误单词高亮显示</title>
<style>
body{ text-align:center}
.show{ margin:0 auto; width:60%; height:100%; border:2px solid}
.highlighted{color:red;display:inline-block;}
/* css注释:为了观察效果设置宽度 边框 高度等样式 */
</style>
</head>
<body>
<div class="show">
''')
try:
with open(self.filePath, encoding="utf-8", errors="ignore") as f:
text = f.readlines()
for lines in text:
wordsList = lines.split(" ") # 根据空格划分单词
for oldWord in wordsList:
# 和标点链接的单词,先略过了,待优化!!!
if '"' in oldWord or "'" in oldWord or "." in oldWord or "," in oldWord: # Jason's or Jason: or Jason.
pass
else:
if not oldWord or oldWord == "\n" or oldWord == "\t":
pass
else:
rightWord = self.check(oldWord.replace("\r", "").replace("\n", "").replace("\t", ""))
if rightWord not in oldWord:
oldWord += '<span class="highlighted">(' + rightWord + ')</span>' #将错误单词在html中高亮显示
print("原单词:", oldWord, " 你可能需要的单词为:", rightWord)
newLines.append(oldWord)
with open("./files/correct.html", "a", encoding="utf-8") as f:
f.write("<p>" + " ".join(newLines) + "</p>") # 空格为界限拼接单词
newLines = [] #每写入一次需要将newLines置空
except Exception as e:
print("文章读取和单词检查出错:", e)
finally:
with open("./files/correct.html", "a", encoding="utf-8") as f:
f.write('''
</div>
</body>
</html>
''')
if __name__ == '__main__':
filePath = "./files/MotherDayArticle.txt" #文档路径
s = SpellCheck(filePath=filePath) #实例化
s.main()
7.完整实现效果:

别误会,没有自带翻译功能,翻译是我后面在后面放上去的,当然,调个API翻译也不是不可以实现。
8.总结:
一些场面话,经过这个小小小项目,加深了对机器学习中贝叶斯公式的理解,提升了对python的学习兴趣....等等等等等
缺点与不足(待优化之处):
1.效率问题:逐个单词对比,花费的时间有点久,读取big.txt文件也是循环读取,逻辑待优化,后期可以考虑用上多线程等;
2.读取文档类型为txt文本,大部分文件可能还是word,后期可以将读取文件改为doc.docx;
3.对于单词和标点相连的单词,暂时跳过了处理;
9.参考:
https://blog.csdn.net/springtostring/article/details/79834067
http://vlambda.com/wz_wZRknw0EUr.html
https://blog.csdn.net/u013830811/article/details/46539919














 1843
1843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









