



目录
传送门
SpringMVC的源码解析(精品)
Spring6的源码解析(精品)
SpringBoot3框架(精品)
MyBatis框架(精品)
MyBatis-Plus
SpringDataJPA
SpringCloudNetflix
SpringCloudAlibaba(精品)
Shiro
SpringSecurity
java的LOG日志框架
Activiti(敬请期待)
JDK8新特性
JDK9新特性
JDK10新特性
JDK11新特性
JDK12新特性
JDK13新特性
JDK14新特性
JDK15新特性
JDK16新特性
JDK17新特性
JDK18新特性
JDK19新特性
JDK20新特性
JDK21新特性
其他技术文章传送门入口
传送门
SpringMVC的源码解析(精品)
Spring6的源码解析(精品)
SpringBoot3框架(精品)
MyBatis框架(精品)
MyBatis-Plus
SpringDataJPA
SpringCloudNetflix
SpringCloudAlibaba(精品)
Shiro
SpringSecurity
Activiti(敬请期待)
JDK8新特性
JDK9新特性
JDK10新特性
JDK11新特性
JDK12新特性
JDK13新特性
JDK14新特性
JDK15新特性
JDK16新特性
JDK17新特性
JDK18新特性
JDK19新特性
JDK20新特性
JDK21新特性
一、MyBatis进化史
1、MyBatis进化史一(无Spring)
原始MyBatis时期;最早是jdbc,为了简化jdbc贾链欲执事的代码,出现了dao层,里面有interface UserDao接口(UserDao名字后期进化了),和UserMapper.xml文件,这个xml相当于UserDao接口的实现类了。mybatis-config.xml配置了数据库驱动链接和UserDao的mapper配置(注意后期这个配置消失了)。SQLSessionFactory获取sqlSession,是线程不安全的,一次Servlet请求就获取一次sqlSession,响应则关闭sqlSession。
UserDao userDao =sqlSession.getMapper(UserDao.Class);增删改的时候一定要提交事务,sqlSession.commit();否则没有效果。
2、Mybatis进化史二(Mybatis-Spring)
SQLSessionTemplate是Mybatis-Spring的核心,是sqlSession的一个实现,可以无缝代替原始时期代码中的SQLSession,并且是线程安全的,可以被多个dao或者映射器共享。注意sqlsession是不安全的。上面的mybatis-config.xml没有配置sqlSession等,这边用applicationContext.xml配置了数据库连接池,sqlSessionFactory,sqlSessionTemplate,UserMapper的mapper配置。
Mybatis和Spring的集成:
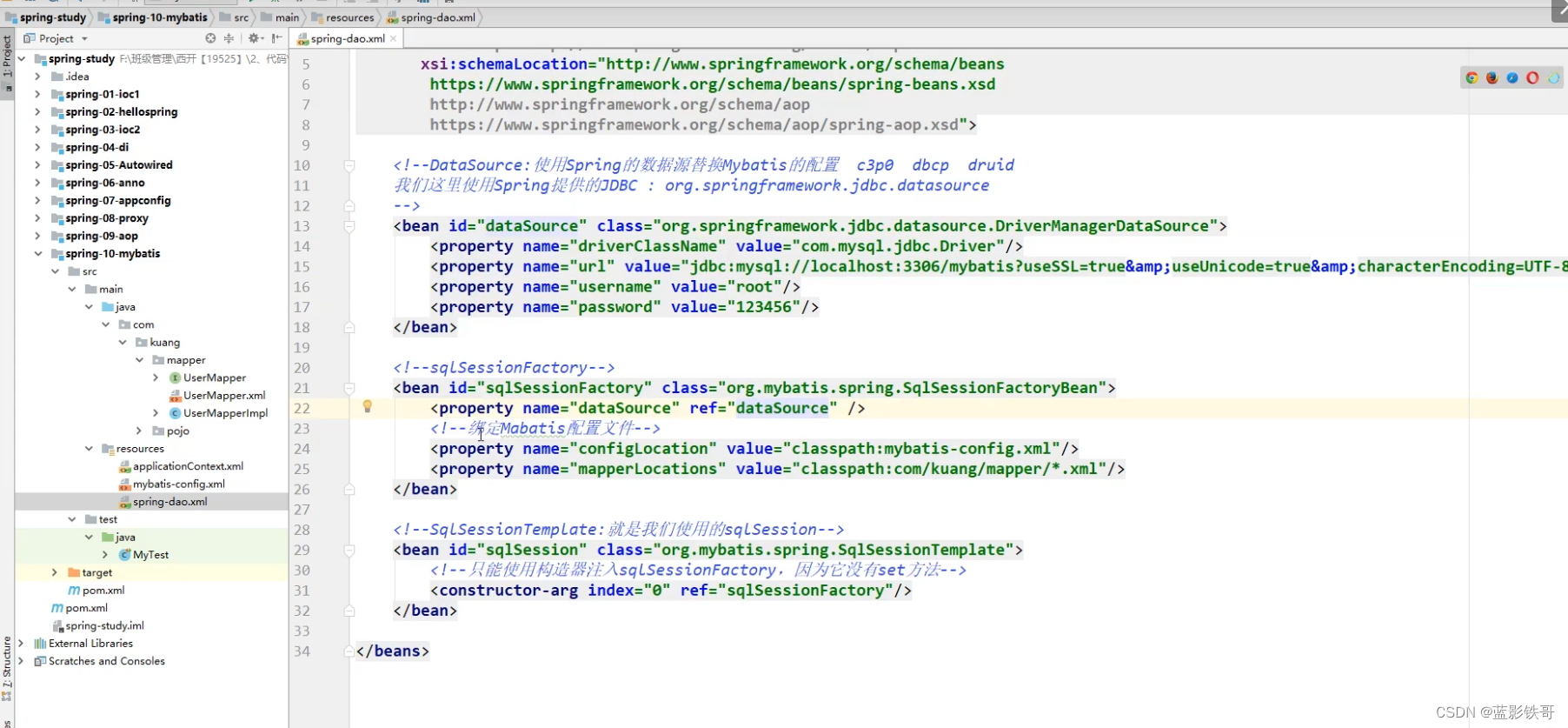
mybatis-Spring的声明式事务(也可以用官方文档中非aop的方式,官方文档更简单):
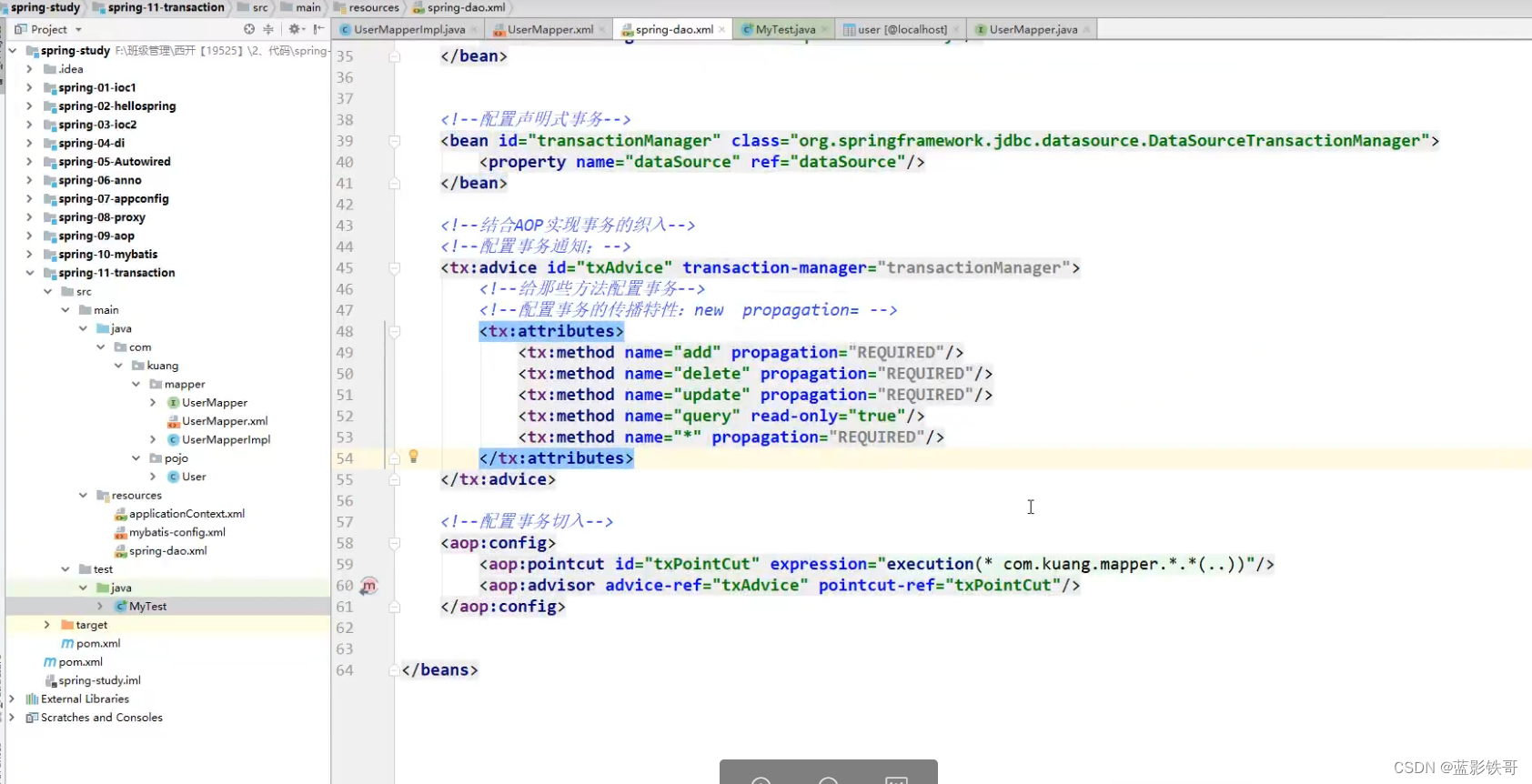
二、生命周期
SqlSessionFactoryBuilder:一旦创建了,就不需要他了。
SqlSessionFactory:可以想象为数据库连接池,一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或者重新创建另一个实例,最佳作用域是应用作用域,使用单例模式。
SqlSession:每个线程都应该有他自己的SqlSession实例,SqlSession的实例不是线程安全的,因此是不能被共享的;比如在Servlet框架中,每次收到一个Http请求,就打开一个SqlSession,响应后就关闭,这个关闭操作非常重要。
三、MyBatis执行流程-简单总结
String resource = "mybatis-config.xml";
InputStream inputStream = Resource.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder.build(inputStream);
SqlSession sqlSession = sqlSessionFactory.openSession(true);// true表示自动提交事务,后面就不用commit了
UserMapper userMapper =sqlSession.getMapper(UserMapper.Class);
userMapper.insertXXX;
//sqlSession.commit(); // 上面用了true,这边就不用了
sqlSession.close();
----------------------------------------------
1.Resource获取加载全局配置文件 2.实例化SqlSessionFactoryBuilder
3.解析配置文件流XMLConfigBuild(就是.build 操作)
4.得到Configuration所有的配置信息
5.实例化SqlSessionFactory 6.transaction事务管理器 7.创建executor执行器
8.创建SQLSession 9.实现CRUD 10.提交事务 11.关闭
四、MyBatis执行流程-详细运行原理
mybatis运行原理:
1.通过加载mybatis全局配置文件以及mapper映射文件初始化configuration对象
和Executor对象(通过全局配置文件中的defaultExecutorType初始化);
2.创建一个defaultSqlSession对象,将configuration对象和Executor对象注入给
defaulSqlSession对象中;
3.defaulSqlSession通过getMapper()获取mapper接口的代理对象mapperProxy
(mapperProxy中包含defaultSQLSession对象)
4.执行增删改查:
1)通过defaulSqlSession中的属性Executor创建statementHandler对象;
2)创建statementHandler对象的同时也创建parameterHandler和
resultSetHandler;
3) 通过parameterHandler设置预编译参数及参数值;
4)调用statementHandler执行增删改查;
5)通过resultsetHandler封装查询结果
分句解析
String resource = "mybatis-config.xml";
InputStream inputStream = Resource.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder.build(inputStream);
1、回到原始的ssm框架,我们会单独配置mybatis-config.xml这种全局配置文件,然后会写好UserMapper.xml这种业务配置文件;
全局配置文件里面可以配置具体的比如 UserMapper.xml的配置信息,也可以不配置,就是通过包扫描的形式,包扫描也能找到UserMapper.xml2、这类xxxMapper.xml信息(包扫描,是因为UserMapper.java上面加了注解,就扫描这个注解的,然后通过namespace就能找到一模一样UserMapper.xml,这样就能拿到UserMapper.xml里面的所有东西了,拿到的对象叫MapperStatement对象)。这样就把两种xml文件关联起来了。
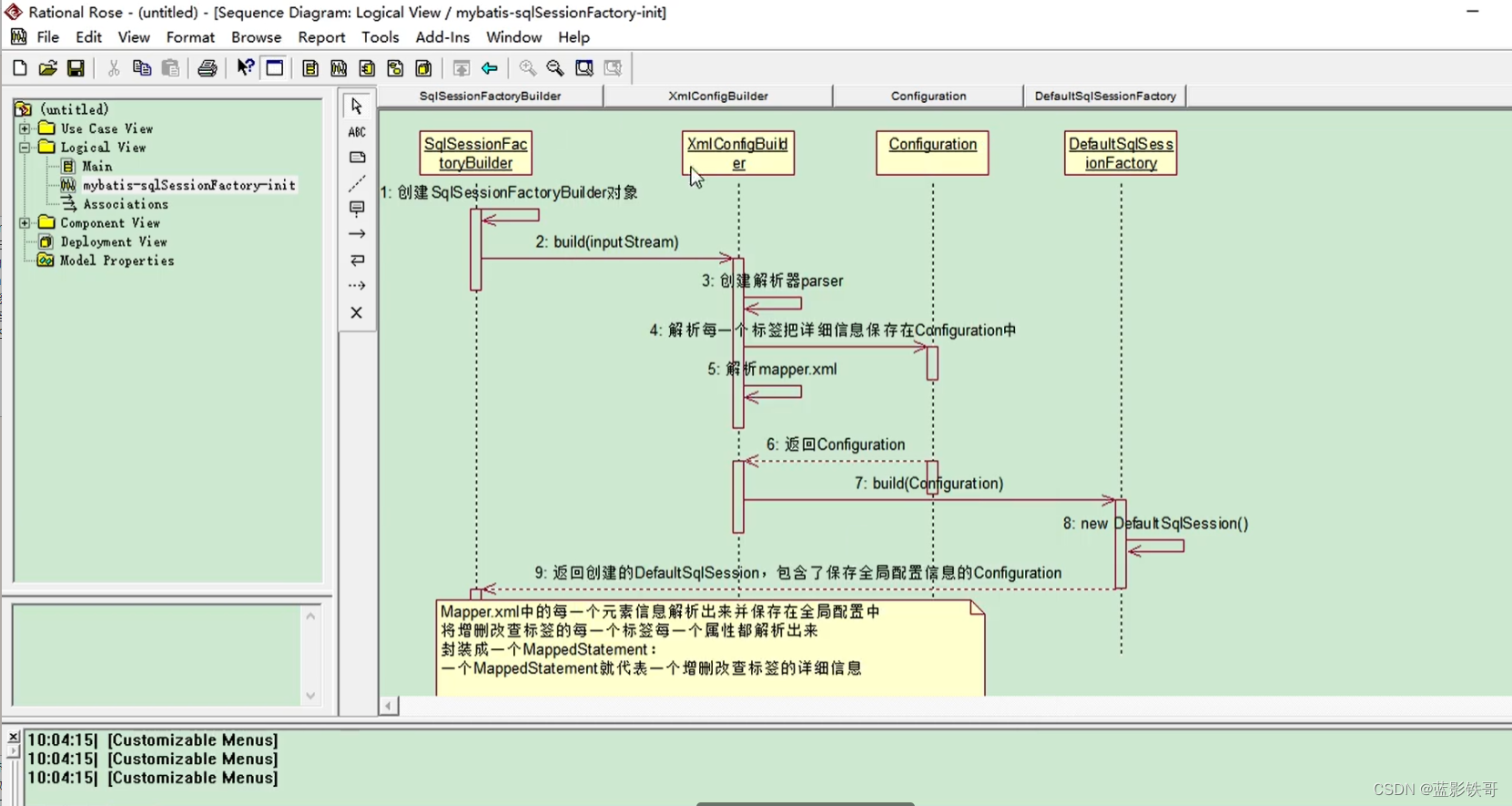
3、而mybatis-config.xml是以流的形式当参数传进去的,那么它自己本身都能被拿到,又因为它能关联到UserMapper.xml,(这个也有专门的解析器通过它自己设置的namespace能拿到它的所有),所以两个xml的信息全部能被拿到,并且存到哦一个叫Configuration的对象里面,在这个对象的基础上进而就出现了sqlSessionFactory对象(多态,sqlSessionFactory是个接口,DefaultSqlSessionFactory是真正的返回)。
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
小总结:这步核心就是把两个xml的信息封装到一个叫Configuration对象里面。
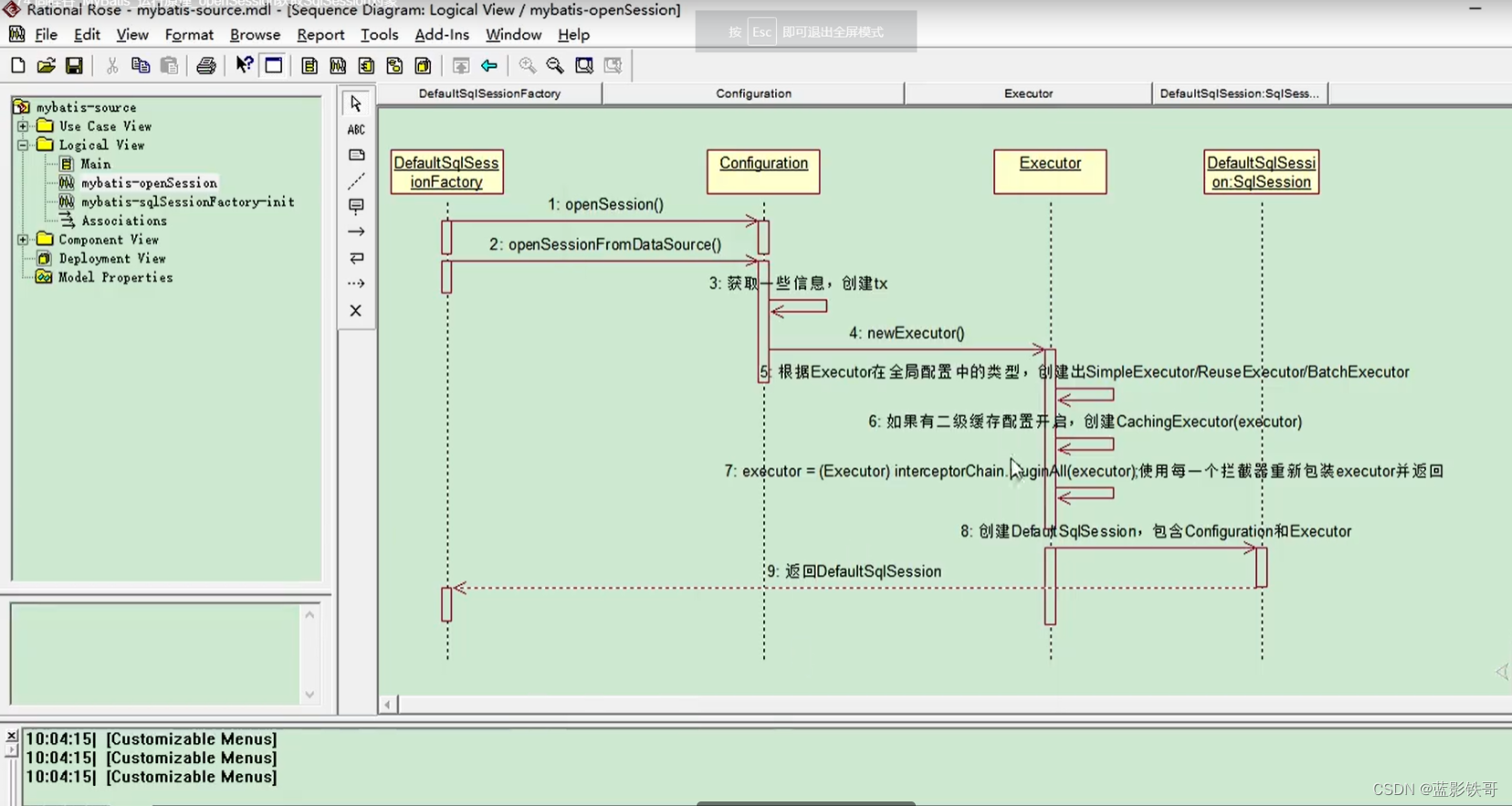
SqlSession sqlSession = sqlSessionFactory.openSession(true);// true表示自动提交事务,后面就不用commit了
1、通过上一步知道sqlSessionFactory是有Configuration所有信息的,这样能拿到事务tx对象(还有一个ExecutorType对象),进而在源码里面拿到了Executor对象,四大对象之一的执行器对象出来了,这个对象主要做增删改查;
2、Executor executor = (Executor)this.interceptorChain.pluginAll(executor); 这个Executor对象在出来之前通过ExecutorType判断了一下类型,具体是哪一类的Executor,不管哪一类,它都是个执行器对象,然后interceptorChain非常重要,这个拦截器链重新把Executor对象包装了一下,返回了我们最后的Executor对象,这个插件链很重要,我们后期可以自定义PageHelper等分页插件的基础原来就在这边。
3、通过Configuration、Executor对象,我们可以new DefaultSqlSession(this.configuration, executor, autoCommit);得到了sqlSession
(又是多态,sqlSession是个接口,这个是它的实现类)
小总结:这步核心就是通过Configuration对象引出来了四大对象的Executor执行器对象。
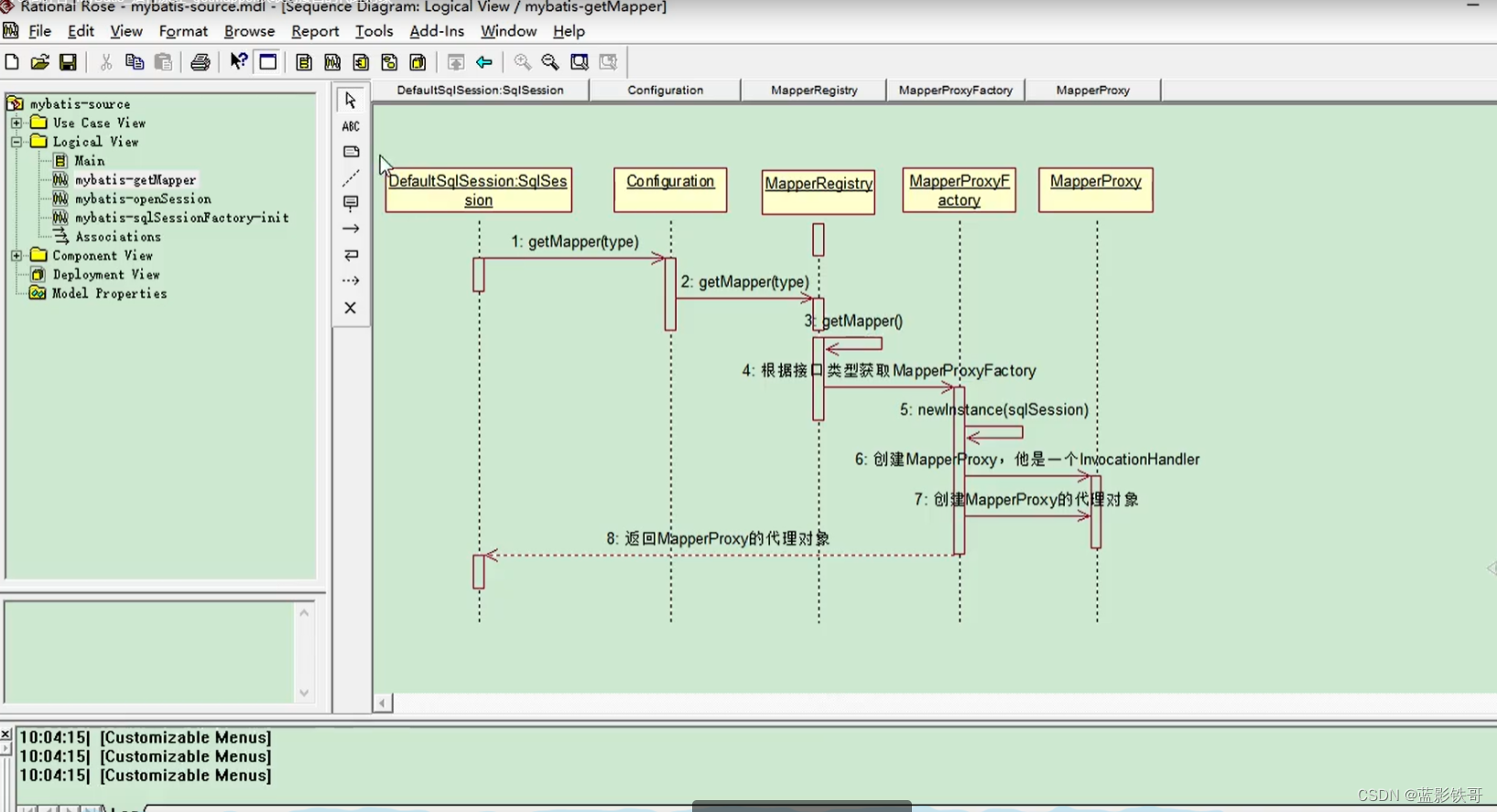
UserMapper userMapper =sqlSession.getMapper(UserMapper.Class);
1、通过上面知道sqlSession其实是包含了Configuration的,可以拿到MapperRegistry(Configuration里面的一个属性);
2、通过MapperRegistry结合sqlSession和出入的UserMapper.class这个泛型Type,就能得到MapperProxyFactory工厂;
3、这个工厂进一步可以得到MapperProxy,它是非常重要的一步,本身是一个InvocationHandler(典型jdk动态代理,通过反射包里面的Proxy.newProxyInstance(Class,mapperProxy)这个方法,就能让jdk实现一个代理类,也就是MapperProxy);
4、UserMapper userMapper = MapperProxy;(又是多态,UserMapper.java,这里本身就是个接口,实现类就是MapperProxy,所以有说法UserMapper.xml就是UserMapper.java的实现类,只不过是jdk通过动态代理变成了真正意义上的实现类MapperProxy)
5、MapperProxy是通过sqlSession一步步过来的,所以这个代理对象是包含了Configuration和Executer执行器对象的。
小总结:这步核心就是拿到动态代理后的实现类MapperProxy
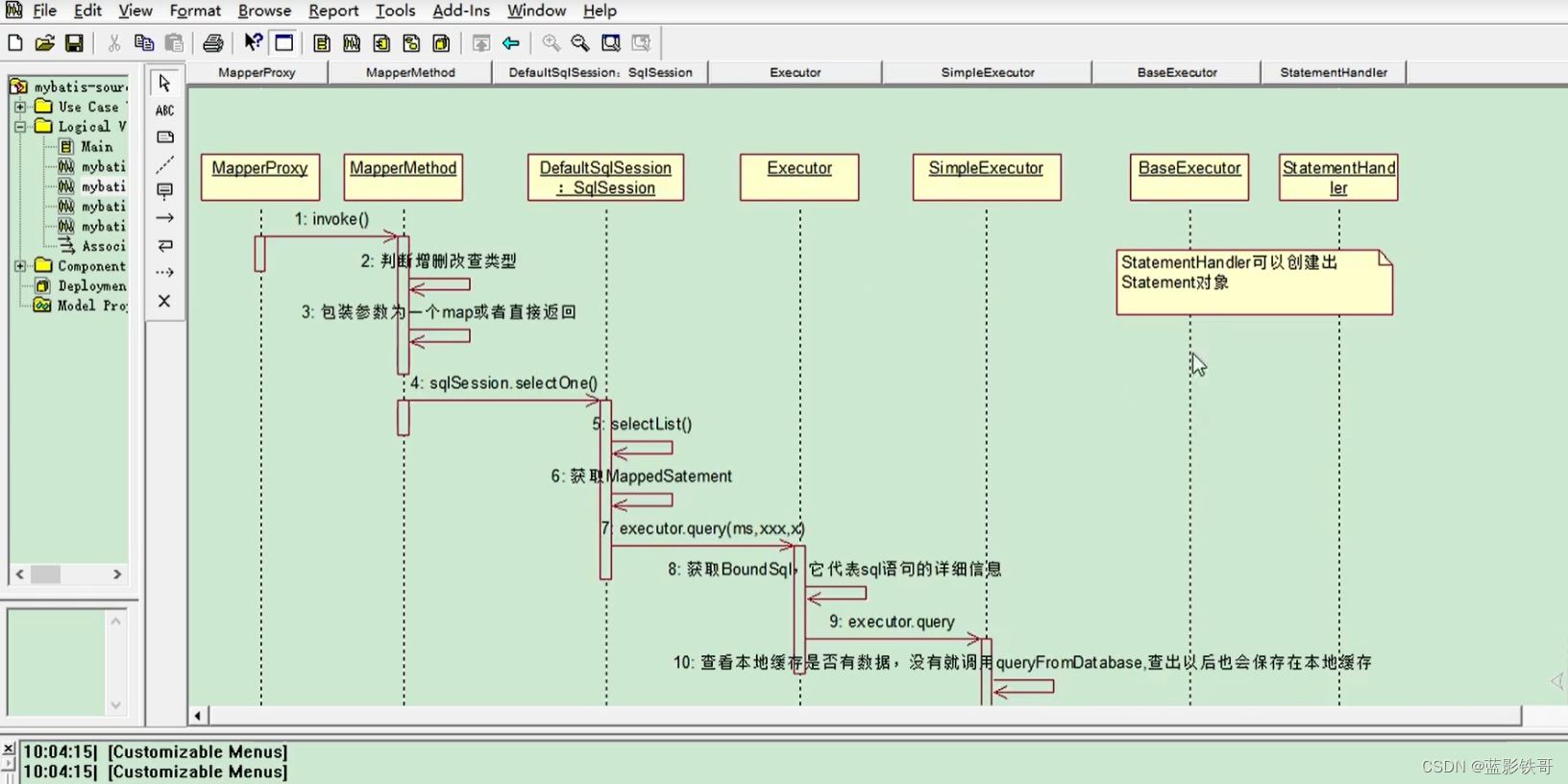
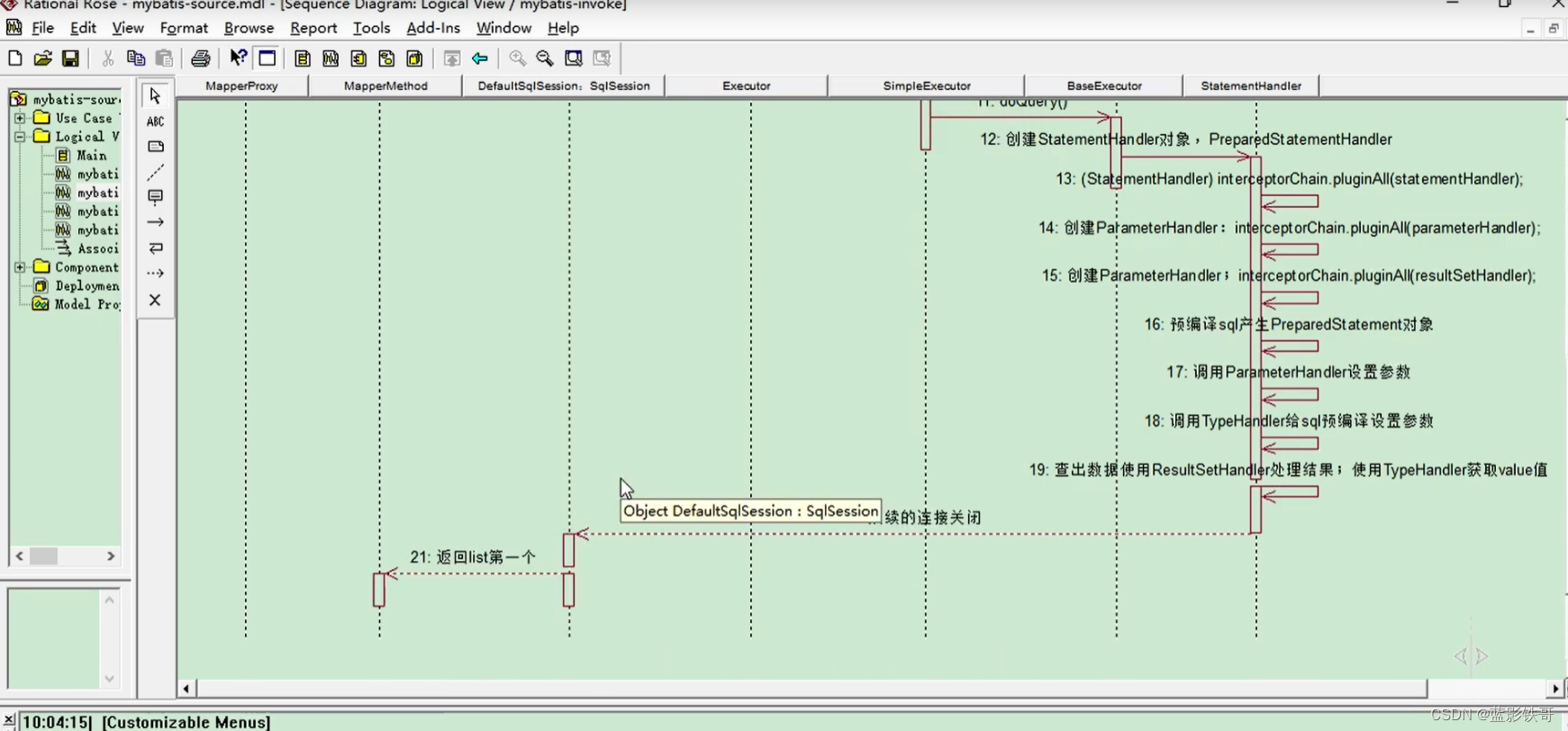
userMapper.insertXXX;
1、这里面非常多的逻辑,简单概括一下,主要是Executer对象去做增删改查;比如查询doQuery;
2、doQuery第一步就是通过Configuration拿到了StatementHandler;(四大对象之一)而且默认是预编译的Handler;
3、StatementHandler statementHandler= (StatementHandler)this.interceptorChain.pluginAll(statementHandler);熟悉的配方,这个四大对象之一的Handler也要经过拦截器链进行包装一下,拿到新的Handler。
4、StatementHandler进而可以拿到我们jdbc核心类Statement对象(加连预执释中的预编译,Statement虽然不是预编译,但是Handler在框架 下默认就是预编译,在拿到Statement的时候也预编译处理了,拿的过程中可以看到获取了Connection链接,做了预编译处理,然后handler设置了Statement对象,得到了最终的有预编译功能的PreparedStatement对象,这个对象在jdbc章节中就知道是实现了Statement接口的。);
5、在StatementHandler做预编译处理的时候,另外一个ParameterHandler也出现了(四大对象之一),主要对参数做预编译处理;还有一个ResulSetHandr也出现了(四大对象之一),主要对结果做处理;(注意:StatementHandr在初始化的时候,这两个也间接开始就初始化好了);而且这两个对象也经过了拦截器链的重新包装。
小总结:这步核心就是在上一步实现类的基础上,调用实现类里面写好的增删改查各式各样的方法,而实现这些就是靠四大对象齐上阵处理完成。
加连预执释中的后四个都是在这里面处理完成的。其实也可以看出,在jdbc中,我们除了sql语句不一样,其他的大部分步骤都一样,框架就是把这部分给抽出去了,让在xml文件中写SQL,其他的统统交给框架做了。
四大对象:
Executor执行器对象
ParameterHandler
ResultSetHandler
StatementHandler

五、插件原理
1、概念
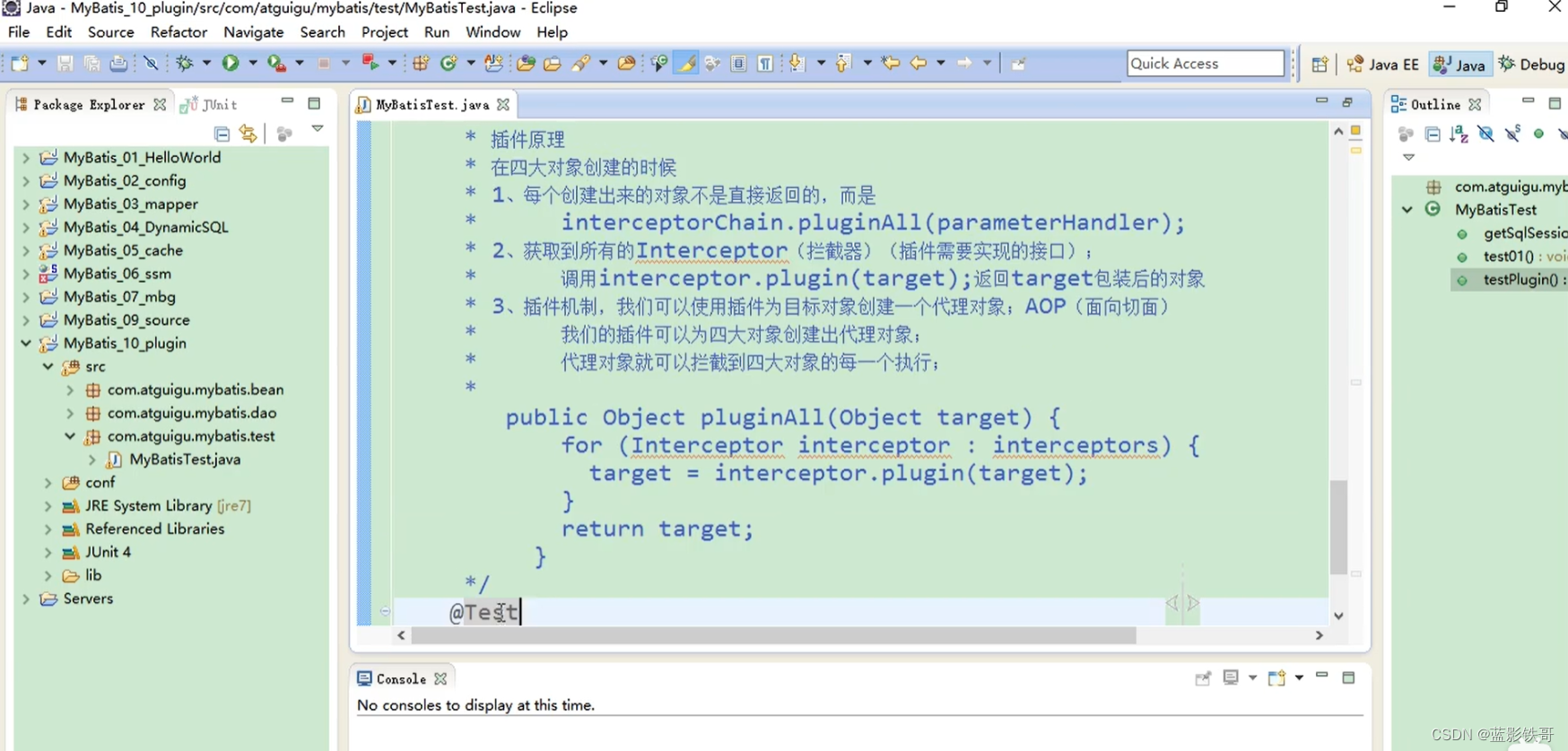
2、实现一个Interceptor接口,来包装四大对象
六、缓存
1、概念
1.一级缓存本地缓存(sqlSession级别)(默认开启):
一次请求(拿到链接到关闭sqlSession链接),一个sqlSession,User user1 = userMapper.getUser(1);User user2 = userMapper.getUser(1);查询同一条记录两次,第二次直接从缓存取的,而且user1和user2的内存地址就是相同的,user1=user2 为 ture。增删改会刷新缓存(不管改的是userId=1还是其他都会失效缓存),sqlSession.clearCache();手动清理缓存也会失效缓存。
2.二级缓存全局缓存(namespace级别或者mapper级别)(需要配置):
二级缓存配置:
在mybatis-config.xml可以加也可以不加,因为默认开启这个设置的(是设置,不是开启二级缓存)
这句话可以不写,默认就是
在userMapper中,在标签对中加一个标签 (整个mapper范围) 或者 比如 里面的查询 标签加个属性 useCache=“true”(只有这个查询是)
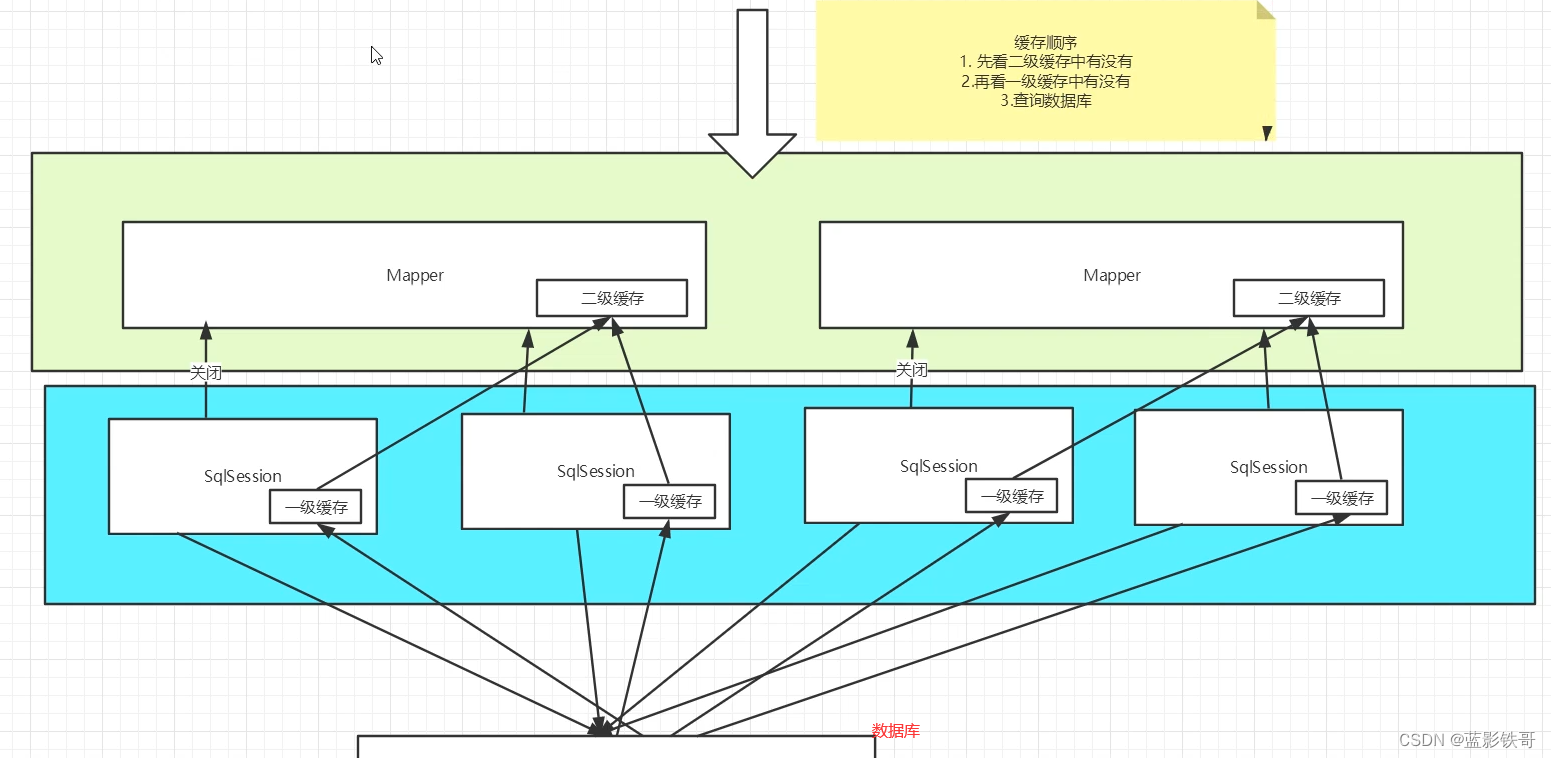
工作机制:
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中;
新的会话查询信息,就可以从二级缓存中获取内容;(注意只有一级缓存提交或者会话关闭才会提交到二级缓存中)
不同mapper查出的数据会放在自己对应的缓存(map)中;
例子:
可以一次请求也可以在不在一次请求里面,这边以一次请求为例,两个sqlSession(特例,一般一次请求就一个sqlSession)
UserMapper userMapper1 =sqlSession1.getMapper(UserMapper.Class);
User user1 =userMapper1 .getUser(1);
sqlSession1.close();
UserMapper userMapper2 =sqlSession2.getMapper(UserMapper.Class);
User user2 =userMapper2 .getUser(1);
sqlSession1.close();
user1==user2为ture 内存地址相同
注意:user对象在cache标签没有任何属性(策略)的时候要实现序列化接口,否则会报错。
缓存顺序:先看二级缓存有没有,再看一级缓存有没有,最后才是查询数据库
3.自定义缓存ehcache(已经被淘汰的技术,现在分布式重要中redis)
是一种广泛使用的开源Java分布式缓存
// cache标签加个第三方自定义的包
resource文件夹下面引入ehcache的xml配置文件(配置一些) 后面实现cache接口。
2、Mybatis高级用法
1.延迟加载:
association实现延迟加载,需要配置才能用,公司项目没有使用,我觉得很好 查看文章 https://blog.csdn.net/eson_15/article/details/51668523
2.一级缓存:(一个SqlSession对应一个SqlSession缓存区域)(默认开启)
第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
mybatis的一级缓存比较简单,我们不知不觉中就在用了 原文链接:https://blog.csdn.net/eson_15/article/details/51669021
3.二级缓存:(多个SqlSession共享一个mapper缓存区域)(需要配置)
sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到该UserMapper的二级缓存中。
如果SqlSession3去执行相同 mapper下sql,执行commit提交,则会清空该UserMapper下二级缓存区域的数据。
sqlSession2去查询用户id为1的用户信息,去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
原文链接:https://blog.csdn.net/eson_15/article/details/51669608
开启了二级缓存后,还需要将要缓存的pojo实现Serializable接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以建议mybatis中的pojo都去实现Serializable接口。
缓存的执行原理和前面提到的一级缓存是差不多的,二级缓存与一级缓存区别在于二级缓存的范围更大,多个sqlSession可以共享一个mapper中的二级缓存区域。
mybatis是如何区分不同mapper的二级缓存区域呢?它是按照不同mapper有不同的namespace来区分的,也就是说,如果两个mapper的namespace相同,
即使是两个mapper,那么这两个mapper中执行sql查询到的数据也将存在相同的二级缓存区域中。
二级缓存弊端:不支持分布式系统,多个Web的时候只会缓存到自己服务器上,无法互相共享。需要Redis支持来解决。


















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











