







树状目录结构:
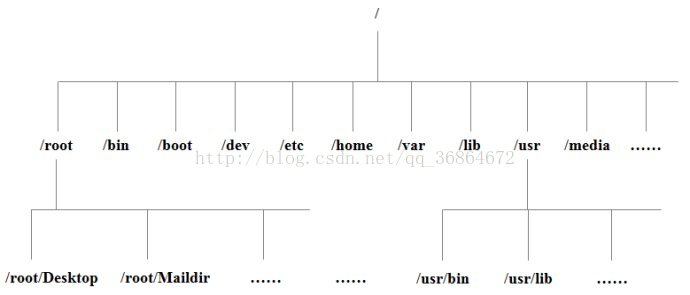
以下是对这些目录的解释:
/bin:
bin是Binary的缩写, 这个目录存放着最经常使用的命令。
/boot:
这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev :
dev是Device(设备)的缩写, 该目录下存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。
/etc:
这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home:
用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。
/lib:
这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
/lost+found:
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
/media:
linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。
/mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
/opt:
这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc:
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
/root:
该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin:
s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/selinux:
这个目录是Redhat/CentOS所特有的目录,Selinux是一个安全机制,类似于windows的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
/srv:
该目录存放一些服务启动之后需要提取的数据。
/sys:
这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。
sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp:
这个目录是用来存放一些临时文件的。
/usr:
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与windows下的program files目录。
/usr/bin:
系统用户使用的应用程序。
/usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:内核源代码默认的放置目录。
/var:
这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
在linux系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。
/etc: 上边也提到了,这个是系统中的配置文件,如果你更改了该目录下的某个文件可能会导致系统不能启动。
/bin, /sbin, /usr/bin, /usr/sbin: 这是系统预设的执行文件的放置目录,比如 ls 就是在/bin/ls 目录下的。
值得提出的是,/bin, /usr/bin 是给系统用户使用的指令(除root外的通用户),而/sbin, /usr/sbin 则是给root使用的指令。
/var : 这是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在/var/log 目录下,另外mail的预设放置也是在这里。伪分布式:
虚拟机命名规则:
全名:neworigin
用户名:neworigin
密码:123456
确认密码:123456
虚拟机名称:ubuntu-desktop-2-00
位置:F:\vmware-systems\ubuntu-desktop-2-00
192.168.134.99
192.168.134.254
子网掩码:255.255.255.0
子网ip:192.168.134.0
网关ip:192.168.134.2
sudo nano /etc/network/interfaces
auto lo
iface lo inet loopback
iface eth0 inet static
address 192.168.134.100
netmask 255.255.255.0
gateway 192.168.134.2
dns-nameservers 192.168.134.2
auto eth0
[//重启主机]
sudo reboot
sudo halt
win32
[C:\Windows\System32\drivers\etc\hosts]
192.168.134.100 s100
[终端]
>ping s100
ubuntu
>sudo nano /etc/hosts //几台主机hosts相同
然后进C:\Windows\System32\drivers\etc修改hosts为:
192.168.178.100 s100
192.168.178.101 s101
192.168.178.102 s102
[客户机桌面模式和文本模式切换]
快捷键:ctrl+ alt + f6 //文本模式
快捷键:ctrl+ alt + f7 //桌面模式
[查看网络端口]
netstat -ano | grep 8080
[创建文件夹]
sudo mkdir /data
cd /
ls -all
[改变拥有者]
sudo chown neworigin:neworigin /data/
[拷贝]
cp /mnt/hgfs/BigData/第四天/jdk-8u121-linux-x64.tar.gz /data/
[解压]
tar -xzvf jdk-8u121-linux-x64.tar.gz
[查看路径]
pwd
[/etc/environment]
>sudo nano /etc/environment
JAVA_HOME=/data/jdk1.8.0_121
PATH="$PATH:/data/jdk1.8.0_121/bin"
>source /etc/environment
[查看环境]
>java -version
hadoop配置
[拷贝]
cp /mnt/hgfs/BigData/第四天/hadoop-2.7.0.tar.gz /data/
[解压]
tar -xzvf hadoop-2.7.0.tar.gz
[etc/environment]
HADOOP_HOME=/data/hadoop-2.7.0
PATH=$PATH:/data/hadoop-2.7.0/bin:/data/hadoop-2.7.0/sbin
[测试]
>hadoop version
[配置文件]
>cd /data/hadoop-2.7.0/etc/hadoop
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
--------------------------------------
cp mapred-site.xml.template mapred-site.xml
[mapred-site.xml]
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[设置免密登录](节点可能远程访问主机执行脚本)
[安装]
sudo apt-get install ssh
[生成秘钥]
ssh-keygen -t rsa[根目录执行]或
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cd ~/.ssh/
[拷贝到公钥] 私钥加密,公钥解密
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 或
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
>ssh localhost
>exit
>ssh localhost
[启动hadoop]
>hdfs namenode -format [工作禁止使用]
>start-all.sh
[查看Java进程]
>jps
[暂停hadoop]
>stop-all.sh
[webui]
s100:50070
[进程]
DataNode //数据节点 DN
ResourceManager//资源管理器RM
NameNode //名称节点 NN
NodeManager //节点管理器 NM
SecondaryNameNode//辅助名称节点2NN
[hadoop shell]
>hadoop fs
[创建目录]
>hadoop fs -mkdir -p /user/neworigin/
[上传文件]
>echo helloworld > 1.txt
>hadoop fs -put ~/1.txt /user/neworigin/
[查看文件系统]
>hadoop fs -lsr 或
>hadoop fs -ls -R 或
>hadoop fs -ls -R /
[修改文件权限]
>hadoop fs -chmod 777 1.txt
[删除文件]
>hadoop fs -rm 1.txt
[读文件]
>hadoop fs -cat 1.txt 或
>hadoop fs -text 1.txt
>hdfs dfs -cat 1.txt
Hadoop端口说明:
默认端口 设置位置 描述信息
8020 namenode RPC交互端口
8021 JT RPC交互端口
50030 mapred.job.tracker.http.address JobTracker administrative web GUI JOBTRACKER的HTTP服务器和端口
50070 dfs.http.address NameNode administrative web GUI NAMENODE的HTTP服务器和端口
50010 dfs.datanode.address DataNode control port (each DataNode listens on this port and registers it with the NameNode on startup)
DATANODE控制端口,主要用于DATANODE初始化时向NAMENODE提出注册和应答请求
50020 dfs.datanode.ipc.address DataNode IPC port, used for block transfer DATANODE的RPC服务器地址和端口
50060 mapred.task.tracker.http.address Per TaskTracker web interface TASKTRACKER的HTTP服务器和端口
50075 dfs.datanode.http.address Per DataNode web interface DATANODE的HTTP服务器和端口
50090 dfs.secondary.http.address Per secondary NameNode web interface 辅助DATANODE的HTTP服务器和端口
分布式:
[集群搭建]
3台虚拟机(s100, s101, s102)
s100 -- master
s101 -- slave1
s102 -- slave1
[配置网络]
/etc/network/interfaces
[配置网络映射]
/etc/hosts
[更改主机名称]
/etc/hostname
------------------
[创建目录]
>sudo mkdir /data (s100, s101, s102)
>sudo chown neworigin:neworigin /data
[无密登录ssh]
[s100, s101, s102]
>sudo apt-get install ssh //安装
>rm -rf ~/.ssh
[s100]
>ssh-keygen -t rsa -f ~/.ssh/id_rsa//在s100(生产公钥)
>cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
>ssh-copy-id s101//把s100的公钥拷贝到s101
>ssh-copy-id s102//把s100的公钥拷贝到s102
>ssh localhost
>exit
>ssh s101
>exit
>ssh s102
>exit
[s100]
cat ~/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEy23ilBVz3NmX5SniIBtxgLT/aFDCCxdc5eTApyjfXg4ISHYcfXsYxDAtqtW9SJQD7KIRvVmRn9hO4nA5MWQVAmPINP96bh7k1eDp8i+1ObKxTd1GXBAhG3dUg3Z7NqOjFBZCMJpwovsR6opajI02g5a27d6YAxZqbBP7RCzIgfuaVEuHqn2HtOA5f7A+eXcNpyb3bvJxmbMe4gUrPQtP+gIS9T13wBKK0EibojpQ52ZKEZUXJFMpX5EThymhBanSVe4KUr8/jmHGQRTMsQMqv2sPNRyL4Sq/C3KsneX4lJt8j8ubPZvzdMOiwQxdYFDn32qsp19BOjlioZpv2JkZ neworigin@s100
[s101] cat ~/.ssh/authorized_keysssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDEy23ilBVz3NmX5SniIBtxgLT/aFDCCxdc5eTApyjfXg4ISHYcfXsYxDAtqtW9SJQD7KIRvVmRn9hO4nA5MWQVAmPINP96bh7k1eDp8i+1ObKxTd1GXBAhG3dUg3Z7NqOjFBZCMJpwovsR6opajI02g5a27d6YAxZqbBP7RCzIgfuaVEuHqn2HtOA5f7A+eXcNpyb3bvJxmbMe4gUrPQtP+gIS9T13wBKK0EibojpQ52ZKEZUXJFMpX5EThymhBanSVe4KUr8/jmHGQRTMsQMqv2sPNRyL4Sq/C3KsneX4lJt8j8ubPZvzdMOiwQxdYFDn32qsp19BOjlioZpv2JkZ neworigin@s100
[s102]cat ~/.ssh/authorized_keysssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDEy23ilBVz3NmX5SniIBtxgLT/aFDCCxdc5eTApyjfXg4ISHYcfXsYxDAtqtW9SJQD7KIRvVmRn9hO4nA5MWQVAmPINP96bh7k1eDp8i+1ObKxTd1GXBAhG3dUg3Z7NqOjFBZCMJpwovsR6opajI02g5a27d6YAxZqbBP7RCzIgfuaVEuHqn2HtOA5f7A+eXcNpyb3bvJxmbMe4gUrPQtP+gIS9T13wBKK0EibojpQ52ZKEZUXJFMpX5EThymhBanSVe4KUr8/jmHGQRTMsQMqv2sPNRyL4Sq/C3KsneX4lJt8j8ubPZvzdMOiwQxdYFDn32qsp19BOjlioZpv2JkZ neworigin@s100
[多台主机执行相同命令]
[/usr/local/bin/]
>sudo nano xcall
#!/bin/bash
#获取参数个数
pcount=$#
if((pcount<1));then
echo no args;
exit;
fi
for((host=100;host<103;host=host+1));do
echo ------------s$host-----------------
ssh s$host $@
done
[发送文件]
[scp]
>scp -r /home/neworigin/Desktop/1.txt neworigin@s101:/home/neworigin/Desktop/
[rsync]
远程同步工具,主要用于备份和镜像;支持链接,设备等等;速度快,避免复制相同内容的文件数据;不支持两个远程主机间的复制
>rsync -rvl /home/neworigin/Desktop/1.txt neworigin@s101:/home/neworigin/Desktop/
#!/bin/bash
pcount=$#
if((pcount<1));then
echo no args
exit
fi
p1=$1
fname=`basename $p1`
#echo $fname
pdir=`cd -P $(dirname $p1);pwd`
#echo $pdir
cuser=`whoami`
for((host=101;host<103;host=host+1));do
echo -------------s$host---------------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done
[免密码]
>sudo passwd
>su root
>sudo nano /etc/sudoers
neworigin ALL=(ALL:ALL) NOPASSWD:ALL
[安装jdk]
>xsync /data/jdk/
[/etc/environment]
JAVA_HOME=/data/jdk1.8.0_121
PATH="$PATH:/data/jdk1.8.0_121/bin"
[复制]
>cd /data/hadoop-2.7.0/etc
>cp -rf hadoop/ hadoop_tmp
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s100/</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/neworigin/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/neworigin/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/neworigin/hadoop/hdfs/namesecondary</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s100</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/neworigin/hadoop/nm-local-dir</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
</configuration>
[slaves]
s100
s101
s102
[新建文件夹]
>xcall mkdir /home/neworigin/hadoop/
[发送]
>xsync /data/hadoop-2.7.0
[配置环境s101, s102]
HADOOP_HOME=/data/hadoop-2.7.0
PATH="$PATH:/data/hadoop-2.7.0/bin:/data/hadoop-2.7.0/sbin"
[启动s100]
>hdfs namenode -format
>start-all.sh //启动
[进程]
>xcall jps
------------s100-----------------
15824 ResourceManager
16065 NodeManager
15122 NameNode
16514 Jps
15358 DataNode
15646 SecondaryNameNode
------------s101-----------------
9233 DataNode
9468 NodeManager
9710 Jps
------------s102-----------------
9192 NodeManager
9434 Jps
8957 DataNode
[webui]
s100:50070
>stop-all.sh //暂停
[jar整理]
tests
sources
core-site.xml hadoop-common-2.7.0.jar core-default.xml
hdfs-site.xml hadoop-hdfs-2.7.0.jarhdfs-default.xml
yarn-site.xml hadoop-yarn-common-2.7.0.jar yarn-default.xml
mapred-site.xml hadoop-mapreduce-client-core-2.7.0.jarmapred-default.xml
[win7配置]
计算机->属性->高级系统设置->环境变量->系统变量
[不要有中文]
HADOOP_HOME=D:\hadoop-2.7.0
Path=$Path;D:\hadoop-2.7.0\bin;D:\hadoop-2.7.0\sbin
[core-site.xml]
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s100/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/neworigin/hadoop</value>
</property>
</configuration>
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/namesecondary</value>
</property>
</configuration>
[yarn-site.xml]
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s100</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file://${hadoop.tmp.dir}/nm-local-dir</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>16384</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>16</value>
</property>
</configuration>
[logs日志]
/data/hadoop-2.7.0/logs
gedit hadoop-neworigin-datanode-s100.log
[hdfs shell]
hadoop fs -mkdir -p /home/neworigin/hadoop/ //创建目录
hadoop fs -put ~/1.txt /home/neworigin/hadoop///上传数据
[hdfs-site.xml]
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/name1,file://${hadoop.tmp.dir}/hdfs/name2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/data1,file://${hadoop.tmp.dir}/hdfs/data2</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.tmp.dir}/hdfs/namesecondary</value>
</property>
</configuration>
[修过之后重新启动]
>xcall rm -rf /home/neworigin/hadoop
>xcall rm -rf /home/neworigin/hadoop
>start-all.sh
>hadoop fs -put ~/1.txt /home/neworigin/hadoop
>hadoop fs -copyFromLocal ~/1.txt /home/neworigin/hadoop
>hadoop fs -copyToLocal /home/neworigin/hadoop/1.txt ~/
>hadoop fs -ls -R /
>hadoop fs -chmod 777 /home/neworigin/hadoop/1.txt
[查找fsimage]
xcall ls -all -R /home/neworigin/hadoop/ | grep image
[hdfs API]
新建java项目(Hadoop01)
新建libs文件夹,拷贝share下面的143jar包到libs下面
选中143jar包,build path->add
新建java文件URLSytem
package org.neworigin.com;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
public class URLSytem {
public static void main(String[] args) throws Exception {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//url路径
String urlStr = "hdfs://s100:8020/home/neworigin/hadoop/1.txt";
//url对象
URL url = new URL(urlStr);
//url链接
URLConnection conn = url.openConnection();
//打开输入流
InputStream input = conn.getInputStream();
//文件输出流
FileOutputStream fileout = new FileOutputStream("F:/BigData/hadoop01.txt");
byte [] buf = new byte[1024];
int len = -1;
while((len = input.read(buf)) != -1){
fileout.write(buf, 0, len);
}
input.close();
fileout.close();
System.out.println("over");
}
}

将Hadoop安装包解压,将hadoop_dll_winutil_2.7.1/zip放到bin目录并解压

新建 _libs目录,将下列几个个jar包放到新建conf文件夹下并解压

新建sources文件夹,将share拷贝过去所有带有sources的jar包放入

新建tests文件夹,将share拷贝过去所有带有tests的jar包放入

去除警告:把log4j配置文件放到你的src根路径下。

调用api访问hdfs文件系统

导入下面jar包可查看源码;

使用filesystem访问hdfs文件系统:

程序报错,解决如下:

原因是因为configuration默认加载core-default.xml和core-site.xml.而core-default.xml在Hadoop-common默认有,而core-site.xml没有,core-default.xml里默认是file:///.在src下新建core-site.xml

DistributedFileSystem的实现
DistributedFileSystem类由四个成员变量,代码如下:
在这四个成员变量中,最重要的就是dfs了,它是DFSClient类型,用于与HDFS集群上的其他节点进行交互,其他三个成员变量用于实现FileSystem要求的,而DFSClient中没有提供的功能。
workingDir保存了文件系统的当前路径;
uri保存文件系统的URI模式和授权机构部分,通过getUri()可以获取uri变量;
verifyChecksum用于标识是否使用校验,如果开启数据校验,那么在每次客户端读取完一部分数据(根据配置而决定)后就会对数据进行CRC-32校验,默认为true。
DistributedFileSystem类中有个initialize()方法,用于在每次创建完DistributedFileSystem的对象后进行初始化,因为客户端获取的具体文件系统是在XML配置文件中配置的,所以每次创建对象都是用反射的方式创建对象,这样创建完之后再用initialize()方法执行初始化。workingDir、uri、dfs这三个成员变量都会在这个方法里面初始化,具体代码如下:
注意,在DistributedFileSystem类中还有一个静态代码块:
这个代码块用于加载hdfs-default.xml文件和hdfs-site.xml文件,它们提供了用于访问Hadoop分布式文件系统的一些配置,hdfs-default.xml一般在Hadoop-core-1.2.1.jar包中提供,hdfs-site.xml在项目的CLASSPATH中,可以由用户修改。

















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









