









1.scala第一个程序
在配好相应环境之后,输入
$ cd /usr/lcoal/scala/mycode
$ vim test.scala
进入编辑第一个scala程序
object HelloWorld{
def main(args:Array[String]){
println("Hello,world!")
}
}
编译执行
$scalac test.scala
$scala -classpath . HelloWold
编译的时候用scala文件名,执行的时候用的是对象名称
2.基本语法
| val | var |
|---|---|
| 不可变 | 可变 |
| 声明时必须初始化 | 声明时需要进行初始化 |
| 初始化后不能改变其值 | 初始化后可以再赋值 |
tips:在scala中按回车可以输入多行代码
scala数据类型有:Byte、Char、Short、Int、Long、Float、Double、Boolean,但这些都是类。
在scala中 a 方法 b 等价于a.方法(b)
scala> var sum1 =5+3
scala> var sum2 = (5).+(3)
scala中没有++和–,所以递增为i+=1,递减为i-=1
从1到5的数值序列可以有以下几种表达方式:
scala>1 to 5 //从1-5,包含区间端点
scala> 1.to(5)
scala>1 to 10 by 2 // 步长为2
scala>1 until 5 //不包含区间终点5,步长为1
scala> 0.5f to 5.9f by 0.8f
从控制台读入

向控制台输出信息用:print()和println()、printf()
scala 中的条件表达式和java类似,不同的是,if表达式的值可以赋给变量
val x = 6
val a = if (x>0) 1 else -1
for循环语句基本格式:for (变量 <- 表达式)语句块,其中“变量 <- 表达式”称为生成器(generator)
for(i<-1 to 5) println(i)
可以在for中加一些限制条件,称为“守卫”(guard)
for (i<-1 to 5 if i%2==0)println(i)
多个生成器时需要用;隔开
for(i<-1 to 5 if i%2==0;j<- 1 to 3 if j!= i)println(i*j)
for 推导式 for (变量<-表达式) yield {语句块}
val r =for(i<-1 to 5 if i%2==0)yield{println(i);i}
得到的r是一个集合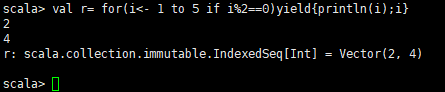
3.scala的数据结构
scala的collection库中包括:
- List
- Array
- Set
- Map
- Tuple等

- 列表(List):共享同类型不可变的对象序列。
var strList = List("bigdata","hadoop","spark")
strList.head //返回bigdata
strList.tail //返回的除第一个元素外其他值构成的新列表即("hadoop","spark")
val otherList = "Apache"::strList //::是在已有列表前端加元素
//strList保持不变,是将strList的值并上Apache成为一个新的列表
val intList = 1::2::3::Nil //Nil表示空列表对象
val intList = List(1,2,3)
- 集合(set):无重复的对象集合,所有元素都是唯一的,包括可变集和不可变集。
var mySet = Set("hadoop","spark")
mySet += "scala"
//默认情况下为不可变集,变的是mySet这个变量,而非集合本身
import scala.collection.mutable.Set
val myMutableSet =Set("Database","Bigdata")
myMutableSet += "CloudComputer"
//可变集需要导入包
注意,虽然可变Set和不可变Set都有添加或删除元素的操作,但是有一个非常大的差别。对不可变Set进行操作,会产生一个新的set,原来的set并没有改变,这与List一样。 而对可变Set进行操作,改变的是该Set本身。
- 映射(Map):键值对的容器,键是唯一的。
也包括可变映射和不可变映射,和Set一样,如果是可变的需要导入scala.collection.mutable.Map
import scala.collection.mutable.Map
val people = Map("a"->"Alice","b"->"Jim","c"->"Bob")
people("a") = "Amy" //更新元素值
people("d") ="Tom" //添加元素
people += ("e"->"Daisy","f"->"Frank")
循环遍历映射for((k,v)<-映射)语句块
for((k,v)<-people) 语句块
for(k<-people.keys) 语句块 //遍历键
for(v<-people.values) 语句块 //遍历值
- 迭代器(Iterator):不是集合,提供访问集合的方法
val iter = Iterator("hadoop","spark","scala")
while(iter.hasNext){ //hasNext是否有下一个值
println(iter.next()) //next返回迭代器下一个元素
}
val iter = Iterator("hadoop","spark","scala")
while(elem<-iter){
println(elem)
}
Iterable返回迭代器的方法:
grouped:返回增量分块
sliding:返回滑动窗口
- 数组(Array):可变、可索引、元素有相同类型的数据集合
val intArr = new Array[Int](3)
intArr(0) = 1
intArr(1) = 2
intArr(2) = 3
val StrArr = new Array[String](3)
StrArr(0) = "bigdata"
StrArr(1) = "hadoop"
StrArr(2) = "spark"
for(i <- 0 to 2)println(StrArr(i))
//也可以不给出数组类型,scala可以自动推断
val intArr2 = Array(1,2,3)
val strArr2 = Array("bigdata", "hadoop","spark")
//二维数组
val Matrix = Array.ofDim[Int](3,4)//以Matrix(0)(1)形式索引
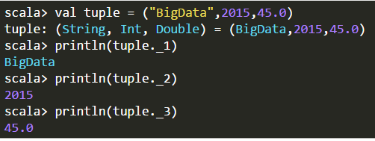
- 元组(Tuple):不同类型的值的集合
本文是看了网易云课堂上厦大的《spark编程基础》的总结,因为内容太多,只将我觉得比较重要的部分记录下来,以后遇到需要的部分再补。















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









