







目录
前言
本题来源于全国职业技能大赛之大数据技术赛项工业数据处理赛题 - 离线数据处理 - 指标计算
注:由于个人设备问题,代码执行结果以及最后数据显示结果将不会给出。
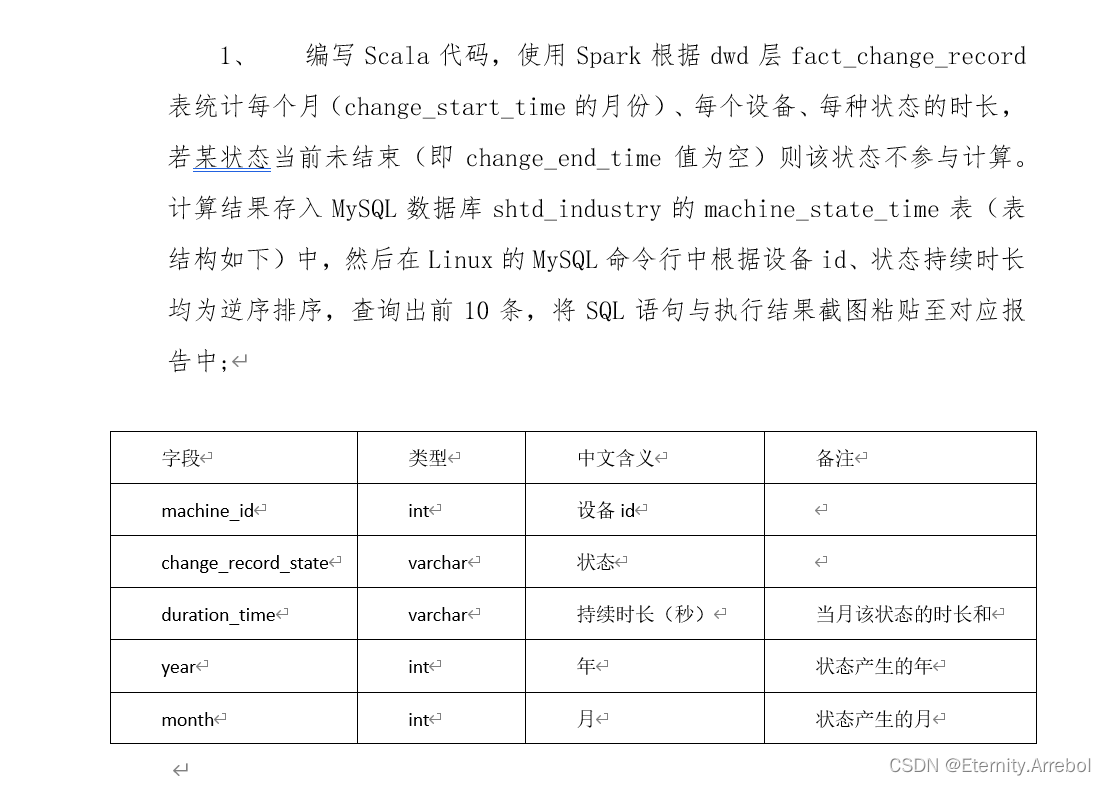
题目:
提示:以下是本篇文章正文内容,下面案例可供参考(使用Scala语言编写)
一、读题分析
涉及组件:Spark,Scala,MySQL
涉及知识点:
- 数据处理计算
- spark函数的使用
二、处理过程
直接上代码
package A.offlineDataProcessing.shtd_industry.task3_indicatorCalculation
import org.apache.spark.sql.functions.{month, unix_timestamp, year}
import org.apache.spark.sql.{DataFrame, SparkSession, functions}
import java.util.Properties
/*
1.读取dwd层fact_change_record表中的数据,并将其加载到Spark DataFrame中。
2.对fact_change_record表中的数据进行处理,进行以下操作:
对于每个设备,仅保留其change_start_time字段月份相同的记录。
如果change_end_time字段为空,则该记录不参与计算。
对于剩余的记录,根据change_start_time和change_end_time计算每个设备的每种状态的持续时长,并存储结果到一个新的DataFrame中。
3.将统计结果存储到MySQL数据库shtd_industry的machine_state_time表中。
4.在MySQL命令行中,使用逆序排序命令,查询出前10条结果。
*/
object answer_No1 {
def main(args: Array[String]): Unit = {
// 创建spark session
val spark = SparkSession.builder().appName("calculate").master("local[*]").enableHiveSupport().getOrCreate()
// 读取hive中的dwd层fact_change_record表数据
val df: DataFrame = spark.sql(
"""
|SELECT ChangeMachineID, ChangeRecordState, ChangeStartTime,
| ChangeEndTime FROM dwd .fact_change_record
| WHERE ChangeEndTime IS NOT NULL
|""".stripMargin
)
// 统计每个月、每个设备、每种状态的时长
/**
* df()相当于df.apply()查询列
* year()识别列的年份
* alias()将列命名为
* agg()里面放的是聚合函数,用于对数据进行聚合操作
* unix_timestamp将选中列转换为一个时间戳
*/
val result = df.groupBy(
df("ChangeMachineID").alias("machine_id"),
df("ChangeRecordState").alias("change_record_state"),
year(df("ChangeStartTime")).alias("year"),
month(df("ChangeStartTime")).alias("month")
).agg(
functions.sum(
unix_timestamp(df("ChangeEndTime")) -
unix_timestamp(df("ChangeStartTime"))
).alias("duration_time")
).select("machine_id", "change_record_state", "duration_time", "year", "month")
// df.show()
// 写入MySQL数据库
val url = "jdbc:mysql://192.168.59.100:3306/shtd_industry"
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
//mysql数据库的类型是latin1,不支持写入中文,显示为??,在spark集群中中文显示ok
result.write.jdbc(url, "machine_state_time", prop)
// 关闭spark session
spark.stop()
/*
bin/spark-submit --master spark://hadoop100:7077 --class org.shtd_industry.task3_indicatorCalculation
.answer_No1 --conf "spark.executor.extraJavaOptions=-Dfile.encoding=UTF-8" --conf "spark.driver
.extraJavaOptions=-Dfile.encoding=UTF-8" /opt/datas/bigdata-1.0-SNAPSHOT.jar
*/
}
}
看过往期的代码,这个代码理解起来应该不难
三、重难点分析
聚合函数的使用,主要是对数据处理的思路和方法。习惯后,遇到类似题可以熟练掌握。
本期为指标计算第1篇,后续应该还会出5篇。
总结
本文将介绍如何使用Scala和Spark对数据库中的数据进行ETL以及计算,最终将结果存储到MySQL数据库中。具体实现过程包括:使用Spark读取数据库表格,数据预处理和清洗,按月、设备、状态统计持续时长,将结果存储到MySQL数据库的特定表格中,最后使用MySQL命令行查询结果。
本文还包括前10条设备状态持续时间最长的数据的SQL语句和执行结果的截图,以加强读者对实现过程的理解和实际应用场景的认识。
请关注我的大数据技术专栏大数据技术 作者: Eternity.Arrebol
请关注我获取更多与大数据相关的文章Eternity.Arrebol的博客
















 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











