







在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
-
编译器优化的重排序。
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
指令级并行的重排序。
现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
-
内存系统的重排序。
由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。 从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:
 上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。 JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel称之为memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。 JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。不管怎么重排序,单线程下的执行结果不能被改变,编译器、runtime和处理器都必须遵守as-if-serial语义。

处理器重排序与内存屏障指令
现代的处理器使用写缓冲区来临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!为了具体说明,请看下面示例:
| Processor A | Processor B |
|---|---|
| a = 1; //A1 x = b; //A2 | b = 2; //B1 y = a; //B2 |
| 初始状态:a = b = 0 处理器允许执行后得到结果:x = y = 0 |
假设处理器A和处理器B按程序的顺序并行执行内存访问,最终却可能得到x = y = 0的结果。具体的原因如下图所示: 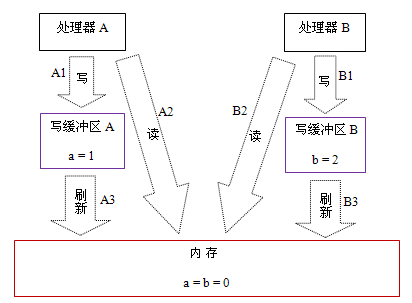 这里处理器A和处理器B可以同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3,B3)。当以这种时序执行时,程序就可以得到x = y = 0的结果。 从内存操作实际发生的顺序来看,直到处理器A执行A3来刷新自己的写缓存区,写操作A1才算真正执行了。虽然处理器A执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,处理器A的内存操作顺序被重排序了(处理器B的情况和处理器A一样,这里就不赘述了)。 这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写-读操作重排序。
这里处理器A和处理器B可以同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3,B3)。当以这种时序执行时,程序就可以得到x = y = 0的结果。 从内存操作实际发生的顺序来看,直到处理器A执行A3来刷新自己的写缓存区,写操作A1才算真正执行了。虽然处理器A执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,处理器A的内存操作顺序被重排序了(处理器B的情况和处理器A一样,这里就不赘述了)。 这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写-读操作重排序。
上表单元格中的“N”表示处理器不允许两个操作重排序,“Y”表示允许重排序。 从上表我们可以看出:常见的处理器都允许Store-Load重排序;常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO和x86拥有相对较强的处理器内存模型,它们仅允许对写-读操作做重排序(因为它们都使用了写缓冲区)。 ※注1:sparc-TSO是指以TSO(Total Store Order)内存模型运行时,sparc处理器的特性。 ※注2:上表中的x86包括x64及AMD64。 ※注3:由于ARM处理器的内存模型与PowerPC处理器的内存模型非常类似,本文将忽略它。 ※注4:数据依赖性后文会专门说明。
什么是 Memory Barrier(内存屏障)?
内存屏障,又称内存栅栏,是一个CPU指令,基本上它是一条这样的指令: 1、保证特定操作的执行顺序。 2、影响某些数据(或则是某条指令的执行结果)的内存可见性。
为了保证内存可见性,java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM把内存屏障指令分为下列四类:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 确保Store1数据对其他处理器可见(刷新到内存),之前于Store2及所有后续存储指令的存储。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 确保Load1数据装载,之前于Store2及所有后续的存储指令刷新到内存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 确保Store1数据对其他处理器变得可见(指刷新到内存),之前于Load2及所有后续装载指令的装载。StoreLoad Barriers会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。 |
StoreLoad Barriers是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
happens-before
从JDK5开始,java使用新的JSR -133内存模型(本文除非特别说明,针对的都是JSR- 133内存模型)。JSR-133使用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。 与程序员密切相关的happens-before规则如下:
-
程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
-
监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
-
volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
-
传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
注意,两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前(the first is visible to and ordered before the second)。happens- before的定义很微妙,后文会具体说明happens-before为什么要这么定义。 happens-before与JMM的关系如下图所示:s
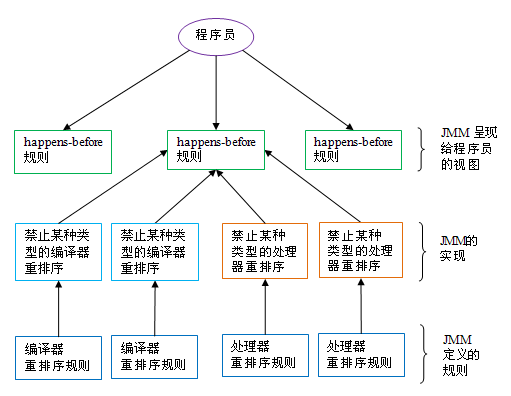 如上图所示,一个happens-before规则通常对应于多个编译器和处理器重排序规则。对于java程序员来说,happens-before规则简单易懂,它避免java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。
如上图所示,一个happens-before规则通常对应于多个编译器和处理器重排序规则。对于java程序员来说,happens-before规则简单易懂,它避免java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









