







-
实验目标
理解数据挖掘的基本概念,掌握基于Weka工具的基本数据挖掘(分类、回归、聚类、关联规则分析)过程。
-
实验内容
- 下载并安装Java环境(JDK 7.0 64位)。
- 下载并安装Weka 3.7版。
- 基于Weka的数据分类。
- 基于Weka的数据回归。
- 基于Weka的数据聚类。
- 基于Weka的关联规则分析。
-
实验步骤
-
下载并安装Java环境(JDK 7.0 64位)
1. 搜索JDK 7.0 64位版的下载,下载到本地磁盘并安装。
我的电脑已经预先装过了jdk8,在dos窗口下用java-version命令测试,结果下图所示:

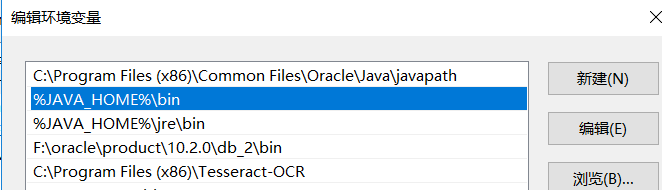
2. 配置系统环境变量PATH,在末尾补充JDK安装目录的bin子目录,以便于在任意位置都能执行Java程序。
先在系统同环境变量里面配置了JAVA_HOME,值为JDK的安装目录,然后在path里面添加了JDK的bin目录,如下图所示:
-
下载并安装Weka 3.7版
电脑上安装的是weka3.8,运行初始界面如下图所示:

-
基于Weka的数据分类
1. 读取“电费回收数据.csv”(逗号分隔列),作为原始数据。
操作步骤: 1.主界面点击“explorer” 进入探索者界面。2.点击 open file打开“电费回收数据.csv”文件 。3.打开之后点击“edit”,可查看原始数据 ,原始数据部分内容如下图所示:

实验开始前先去除对于电费回收分析无用的属性列,包括:YMD:(日期),CONS_NO(用户编号),RCVED_DATE(实收日期),CUISHOU_COUNT(催收次数),数据全为0,对于分析无帮助,去除。WZCS(违章次数),数据全为0,对于分析无帮助,去除。
去除无用属性列之后的数据集如下图所示:

2. 数据预处理
(1) 将数值型字段规范化至[0,1]区间。
规范化处理就是把连续型取值(numeric type)转化为离散型取值(nominal type)。
操作步骤:filter->unsupervised->attribute->normalize
normalize的默认参数是[0,1],直接点击apply按钮将数据集的字段规范化到[0,1]区间。规范化之后的数据集如下图所示:

(2)调用特征选择算法(Select attributes),选择关键特征。
特征选择是通过搜索数据中所有可能的属性组合,以找到预测效果最好的属性子集。自动选择属性需要设立两个对象:属性评估器和搜索方法。在进行特征选取时采取了两种方法进行特征选取,方法1注重对特征子集进行评价,方法2侧重对单个属性进行评价。
方法1:
选择CfsSubsetEval作为属性评估方法,这种方法根据属性子集中每一个特征的预测能力以及它们之间的关联性进行评估。
选择GreedyStepwise作为搜索算法,该方法进行向前向后的单步搜索。
然后点击start按钮开始选取关键特征,选取结果如下图所示:

由选取结果可看出,应选取RCVED(实收电费),TQSC(欠费时长)两个属性作为关键属性。
方法2:
选择InfoGainAttributeEval作为属性评估方法,根据与分类有关的每一个属性的信息增益进行评估。
选择Ranker作为搜索算法,对属性值排序。
然后点击start按钮开始选取关键特征,选取结果如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8453
8453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











