







文章目录
- 一、前言
- 二、日志系统
- 三、日志系统应用:事务
- 3.1 redo log日志(保证事务的持久性,一共七点)
- 3.1.1 作用:Redolog的唯一作用
- 3.1.2 两个类型(流程的基础):Redo的类型(物理redolog和逻辑redolog,我们介绍物理redolog)
- 3.1.3 两个结构(流程的基础):Redolog的两个组成(内存redolog buffer+磁盘redolog file)
- 3.1.4 两个时机(流程的基础):什么时候写Redo?redolog写入的两个时机?(数据修改、索引修改和undo页面修改)
- 3.1.5 数据修改流程:redolog是怎样写的?以一个更新事务为例,Redolog写入流程?
- 3.1.6 持久性(流程之后):对于这个update更新事务,redo如何保证事务的持久性?为什么说redo日志保证了事务持久性?
- 3.1.7 底层实现(流程之后):mini-transaction:Redolog在InnoDB中底层实现?
- 3.2 undo log日志(保证事务的原子性)
- 四、日志系统应用:mysql容灾(binlog实现mysql容灾,不用记,但是面试要能够说出步骤)
- 五、面试金手指
- 六、小结
一、前言
MySQL日志系统三大块:bin log 二进制日志、undo log 撤销回滚日志、redo log 重做日志。
mysql在结构上分为三层:连接层(仅连接),服务层(解析where查询条件,接收存储引擎层的返回结果,按select的要求过滤、计算得到最终返回结果给client),存储引擎层(仅提供数据)。undolog和redolog是存储引擎层的日志,是innodb独有的,是innodb保证事务原子性和持久性的关键,binlog是服务层server的日志,每个存储引擎都有。
binlog以事件的形式记录了所有的DDL和DML语句(因为它记录的是操作而不是数据值,所有属于逻辑日志),可以用来做主从复制和数据恢复,这也是binlog的唯二两个功能。
undo日志(保证原子性)和redo日志(保证持久性)都是在存储引擎层的InnoDb实现的,只有InnoDB存储引擎特有,binlog日志(主从同步和mysql容灾,定时的全量复制+binlog增量复制,防止删库跑路)是在mysql server层实现的,所有类型的存储引擎都有。
对于记录的内容,binlog和undolog记录的都是sql语句,属于逻辑日志,互为逆操作,而且都是记录DDL和DML,都不记录select;redolog记录的用于刷盘的数据行,是物理日志。
理由很简单,只有InnoDB能实现事务的四个特性,undo原子性,redo持久性,各个存储引擎都支持主从同步和mysql容灾。
日志系统的应用,一共包括三个
第一,数据库事务中,redolog日志保证持久性,undolog日志保证原子性,undolog日志通过实现MVCC保证隔离性(已提交读和可重复读,然后,可序列化和未提交读不是MVCC实现的)
第二,binlog实现数据库容灾
第三,binlog实现主从复制-读写分离,binlog记录数据改变,发送到消息队列,被索引库监听。
二、日志系统
2.1 binlog
2.1.1 binlog记录的内容:SQL语句逻辑日志(statement模式)
binlog我们可以简单理解为:存储着每条变更的SQL语句(当然从下面的图看来看,不止SQL,还有XID「事务Id」等等)

raw模式存放数据变化,statement模式存放sql语句,mixed模式中,mysql根据每一条具体sql语句对待日志类型,从raw模式和statement模式中选择一种
金手指:关于binlog记录的内容,binlog记录表结构和表数据的变更。注意两点。
(1)binlog记录了数据库表结构和表数据变更,并且是与当前sql相同的操作,比如
三个表的数据操作:
当前insert,就记录insert;
当前delete/truncate就记录delete/truncate;
当前update A->B,就记录update A->B;
两个表的结构操作:
当前drop,就记录drop;
当前create,就记录create
(2)binlog它没有记录select(因为这没有对表没有进行变更)。
注意,TRUNCATE 和 DELETE 只删除数据,而 DROP 则删除整个表(结构和数据)。
2.1.2 binlog日志唯二作用:binlog数据库层面的两个作用(mysql读写分离-主从复制和mysql容灾-恢复数据)+ binlog索引库层面的作用(搜索引擎监听binlog)
因为binlog记录了数据库表的变更,所以,主要有两个作用:mysql读写分离-主从复制和mysql容灾-恢复数据
第一,mysql读写分离-主从复制:MySQL在公司使用的时候往往都是一主多从结构的,从服务器需要与主服务器的数据保持一致,这就是通过binlog来实现的
第二,mysql容灾-恢复数据:数据库的数据被误删,我们可以通过binlog来对数据进行恢复。
例如,数据恢复:比如上午9点删库跑路(解决:定时备份 + binlog )
1、定时的全量备份的数据(1:00)
2、解析1:00~9:00 binlog日志
第三,搜索引擎就会监听binlog的变更,如果binlog有变更了,那我们就需要将变更写到对应的数据源:canal就是把自己当作slave节点,实时读取master节点的binlog,做到实时同步,这个本质上还是使用主从复制的原理。
因为很多时候数据的更新就依赖着binlog,举例:数据是保存在数据库,如果对某个商品的某个字段的内容改了(数据库变更),而用户检索的出来数据是走搜索引擎的。为了让用户能搜到最新的数据,我们需要把引擎的数据也改掉。
2.2 undolog
2.2.1 undolog日志记录的内容:逆操作逻辑日志
undo日志里面记录的是什么,如何实现回滚撤销?
undo log主要存储的也是逻辑日志,但是是与操作完全相反的sql日志。比如我们要insert一条数据了,那undo log会记录的一条对应的delete日志。我们要update一条记录时,它会记录一条对应相反的update记录。
所谓回滚,就需要修改的操作相反就好,这样就能达到回滚的目的。因为支持回滚操作,所以我们就能保证:“一个事务包含多个操作,这些操作要么全部执行,要么全都不执行”。【原子性】
附加:undolog和binlog都是逻辑日志,互为逆操作,而且都是记录DDL和DML,都不记录select。
2.2.2 undolog日志唯二作用:回滚撤销(LBCC)和多版本控制(MVCC)
第一,undo log实现回滚撤销,保证事务原子性(LBCC)
在数据修改update/insert/delete的时候(select不属于数据修改),不仅记录了redo log,还记录undo log,如果因为某些原因导致事务失败或回滚了,可以用undo log进行回滚,就是撤销。
第二,undo log实现MVCC多版本控制
因为undo log存储着修改之前的数据,相当于一个前版本,MVCC实现的是读写不阻塞,读的时候只要返回前一个版本的数据就行了。
2.3 redolog
2.3.1 redolog持久化作用的整个过程:redolog重做日志实现事务持久化的整个过程
2.3.1.1 磁盘页–>内存页–>磁盘页(第一步同步刷盘)
假设我们有一条sql语句:
update table1 set website='csdn' where id = '3'
宏观意义:MySQL执行这条SQL语句,肯定是先把id=3的这条记录查出来,然后将website字段给改掉。
微观操作/底层操作:因为Innodb的基本存储结构是页(pageSize为16KB,记录都存在页里边,B+树中一个节点大小就是一个页),所以MySQL是先把这条记录所在磁盘上的页找到,然后把该页加载到内存中,将对应记录进行修改,最后在写回磁盘,就是刷盘。即磁盘页–>内存页–>磁盘页。
2.3.1.2 磁盘页–>内存页–>磁盘页(第二步异步刷盘)
现在就可能存在一个问题:如果在内存中把数据改了,还没来得及落磁盘,而此时的数据库挂了怎么办?显然这次更改就丢了。没关系,mysql内存中的数据是异步写到磁盘中的,不会丢。

2.3.1.3 磁盘页–>内存页–>磁盘页(异步刷盘 + redolog)
如果每个请求都需要将数据立马落磁盘之后,即内存数据操作同步更新到磁盘,那速度会很慢,MySQL可能也顶不住。所以MySQL是怎么做的呢?
MySQL引入了redolog重做日志文件,内存写完了,然后会写一份redo log日志文件,这份redo log记载着这次在某个页上做了什么修改。所以,图中多了一个redo log日志文件:

2.3.1.4 磁盘页–>内存页–>磁盘页(内存redolog buffer --磁盘redolog file)
值得注意的是,redo log重做日志这个文件也是在磁盘中的,而且,写redo log的时候,也会有buffer,是先写redolog buffer,再真正落到磁盘中redolog file中的。至于从buffer什么时候落磁盘中的redo log日志中,会有配置供我们配置。所以,图中多了一个buffer:

写redo log也是需要写磁盘的,但它的好处就是顺序IO(我们都知道顺序IO比随机IO快非常多)。
附加:
记住1,mysql包括内存部分和磁盘部分,这两部分中间还包括一个不属于mysql的operating system cache,在mysql的存储引擎innodb架构中就可以知道。
记住2:三个日志文件记录在哪里?
binlog:只有binlog file,在磁盘上;
redolog:同时有redolog buffer和redolog file,前者在内存,后者在磁盘;
undolog:只有undolog file,在磁盘上。
记住3:三个日志文件记录的是什么?记录的都是sql语句,不是修改的数据
binlog两个作用:需要读写分离-主从同步和mysql容灾和搜索引擎监听binglog,statement模式记录的是sql语句。
redolog一个作用:需要保证事务持久化,记录的是数据页物理修改的内容(xxxx页修改了xxx)。
undolog两个作用:需要撤销回滚事务原子化(LBCC)+MVCC(已提交读+可重复读),记录的是sql语句。
金手指:为什么不直接将mysql内存中的数据写到mysql磁盘上去,而是要通过磁盘上的redo log文件作为中介?
回答:既可以保证断电不丢失,也可以保证高效(logbuffer写入到redolog是每秒,而且是顺序IO)
1、断电不丢失:通过redo log日志文件就可以得到保存,毕竟在磁盘上,断电或mysql服务宕机不会丢失。
2、同步sql语句代替同步修改数据:写redo log也是需要写磁盘的,但是redo log中记录的是sql语句,而不是修改的数据,这样的好处就是顺序IO,从mysql内存到mysql磁盘是同步修改数据,要不断找。
所以,redo log的存在为了:当我们修改的时候,写完内存了,但数据还没真正写到磁盘的时候。此时我们的数据库挂了,我们可以根据redo log来对数据进行恢复。因为redo log是顺序IO,所以写入的速度很快,并且redo log记载的是物理变化(xxxx页做了xxx修改),文件的体积很小,恢复速度很快。
2.4 三种日志的关系
2.4.1 三种日志,记录的内容、作用和关系(辨析 binlog与undolog、undolog与redolog)(重点)
金手指:三种日志,记录的内容、作用
binlog日志:逻辑日志,记录的是sql语句,和当前sql相同的sql语句,包括三种表数据操作和两种表结构操作,没有select,三个作用:mysql读写分离-主从复制、mysql容灾-恢复数据、索引库监听消息队列
undolog日志:逻辑日志,记录的是sql语句,和当前sql相反的sql语句,包括三种表数据操作和两种表结构操作,没有select,两个作用:撤销重做保证事务原子性和MVCC
redolog日志:物理日志,记录的是数据页物理修改的内容(xxxx页修改了xxx),一个作用:保证事务的持久化。
小结1:binlog和undolog的内容:binlog和undolog是都是逻辑语句,都是sql语句,是逆过程,都是DDL和DML,没有select语句;
小结2:undolog和redolog的内容:undolog日志是redolog日志的子集,因为redolog会记录undolog的修改(第一,数据:数据修改;第二,索引:聚集索引、二级索引和undo的修改)
2.4.2 辨析:binlog和redolog(都是恢复,记录的内容、记录的作用、记录的引擎不同)
相同点:作用相同,都是用来恢复数据
第一,记录的本质和内容不同(binlog记录的是数据逻辑变化 SQL语句,redolog记录的是数据物理变化)
binlog 记录的是数据的逻辑变化,binlog记载的是update/delete/insert这样的SQL语句;
redo log 记录的是数据的物理变化,redo log记载的是数据页物理修改的内容(xxxx页修改了xxx)。
第二,接上面,实现的功能不同(虽然都是用来恢复数据,binlog三个功能,redolog一个功能)
binlog的作用是复制和恢复而生的。
(1)mysql读写分离-主从复制:对于一主多从的结构(五种主从服务器结构之一),主从服务器需要保持数据的一致性,通过binlog来同步数据。
(2)mysql容灾-误删操作:如果整个数据库的数据被误删,binlog存储着所有的数据变更情况,那么可以通过binlog来对数据进行恢复。
(3)索引库通过消息队列监听数据库数据变化:搜索引擎就会监听binlog的变更,如果binlog有变更了,那我们就需要将变更写到对应的数据源
redo log的作用是为持久化而生的。
写完内存,如果数据库挂了,那我们可以通过redo log来恢复内存还没来得及刷到磁盘的数据,将redo log加载到内存里边,那内存就能恢复到挂掉之前的数据了。
金手指:无效redolog会被删除,但是无效binlog和undolog不会被删除,binlog主从复制后还需容灾,undolog事务成功后还需MVCC(多版本控制,读已提交+可重复读)
问题:”如果整个数据库的数据都被删除了,那我可以用redo log的记录来恢复吗?“
回答:不能。redo log不会存储着历史所有数据的变更,redolog文件的内容会被覆盖。
解释:redolog 存储的是物理数据的变更,如果我们内存的数据已经刷到了磁盘了,那redo log的数据就无效了。所以redo log不会存储着历史所有数据的变更,无效的 redo log文件的内容会被覆盖的。
第三,接上面,binlog和redolog支持的引擎不同
binlog无论MySQL用什么引擎,都会有的。
redolog是MySQL的InnoDB引擎所产生的,毕竟是用来完成事务的,只有InnoDB存储引擎才有事务
附加1:InnoDB是有事务的,持久化是事务的四大特性之一。事务的持久性就是靠redolog来实现的(如果写入内存成功,但数据还没真正刷到磁盘,如果此时的数据库挂了,我们可以靠redo log来恢复内存的数据,这就实现了持久性),所以,redolog日志只有在InnoDB引擎才产生。
附加2:事务的原子性通过回滚来实现操作的原子性,而回滚又是通过undolog实现的,所以说,事务的原子性是通过undolog日志实现的
2.4.3 辨析:undolog和redolog(undolog是redolog的子集)
问题:undo log 是否是redo log的逆过程?
回答:不是,
第一,记录的本质不同:undo log是逻辑日志,记录的是数据的逻辑变化;redo是物理日志,记录的是数据页的物理变化;
第二,记录的内容不同:undo记录的是当前sql语句的相反操作(当前insert,就记录delete/truncate,当前delete就记录insert,当前update A->B,就记录update B->A,当前drop,就记录create,当前create,就记录drop);记录的是当前sql的相同操作(还有聚集索引、主键索引、undo修改)。
第三,功能不同:undolog用于事务回滚时,只是将数据库逻辑地恢复到原来的样子,保证事务原子性和MVCC;redolog用于刷盘,保证事务持久性,更新磁盘数据页;
第四,小结:undo和redo的关系:undo log不是redo log的逆过程,undo是redo的子集,因为对于undo的修改,都要写到redo日志里。
2.4.4 单数据库事务:redolog binlog undolog 顺序问题(重点)
假设有A、B两个数据,值分别为1,2.
修改SQL:update students set A=3,B=4 where id=1;
1. 事务开始
2. 记录A=1到 undo log // 执行之前记录undolog日志
3. 修改A=3
4. 记录A=3到 redo log // 执行之后记录redolog日志
5. 记录B=2到 undo log // 执行之前记录undolog日志
6. 修改B=4
7. 记录B=4到 redo log // 执行之后记录redolog日志
8. 将redo log写入磁盘(redolog buffer --redolog file redo第四步) // 事务提交前redolog buffer写入到redolog file
9. 事务提交
实际上,在insert/update/delete操作中,redo和undo分别记录的内容都不一样,记录的量也不一样。在InnoDB内存中,一般的顺序如下:
1、写undo的redo(解释:事务开始时,写undo之前,写修改这个undo的redo;原因:undo日志的修改,也要记录redo日志)
2、写undo(解释:sql第一步,修改数据页之前,写undo log,)
3、修改数据页(解释:sql第二步,修饰数据页)
4、写Redo(解释:sql第三步,修改数据页之后,写redo log)
5、写undo(解释:sql第一步,修改数据页之前,写undo log,)
6、修改数据页(解释:sql第二步,修饰数据页)
7、写Redo(解释:sql第三步,修改数据页之后,写redo log)
8、将redo log写入磁盘(redolog buffer --redolog file redo第四步)
9、事务提交 (解释:写入binlog日志)
问题:同时具有binlog和redolog,写入顺序是如何的?binlog和redolog的写入时机?
上面也提到,在修改的数据的时候,binlog会记载着变更的内容,redolog也会记载着变更的内容,undolog记录变更的内容的相反操作(只不过redolog存储的是物理变化,binlog和undolog存储的是逻辑变化)。那他们的写入顺序是什么样的呢?
回答:
第一,对整个事务来说,先写入redolog,再写入binlog。
redolog事务开始的时候,就开始记录每次的变更信息;解释:xxx
binlog是在事务提交的时候才记录。解释:binlog只有一种形式,binlog file在磁盘中,当然是最后事务完成再一次性刷盘,减少磁盘IO次数。
第二,对事务中每一条sql语句来说,先写入undolog,再写入redolog。
undo log是sql第一步,修改数据页之前,写undolog,保证如果第二步sql执行出错就可以回滚
redo log是sql第三步,修改数据页之前,写redolog buffer,表示sql执行成功好了,就记录到data --redolog buffer中。
小结:undo log是第二句错误帮助回滚,redo log是第二句正确记录,
所以,如果第二句没错undo log就没用了,但是还是可以作为MVCC作用,不能删除undo log;
如果第二句数据持久化到磁盘,redolog就没用了,数据刷盘后删除redo log。
解释1:对于整个事务,为什么redolog事务开始的时候,就开始记录每次的变更信息?
解释2:对于整个事务,为什么binlog是在事务提交的时候才记录?
binlog只有一种形式,binlog file在磁盘中,当然是最后事务完成再一次性刷盘,减少磁盘IO次数。
解释3:对于事务中的每一条SQL语句,为什么undolog是sql第一步,修改数据页之前,写undolog?
保证如果第二步sql执行出错就可以回滚
解释4:对于事务中的每一条SQL语句,为什么redolog是sql第三步,修改数据页之后,写redolog buffer?
表示sql执行成功好了,就记录到data --redolog buffer中,最后统一刷盘redolog buffer --redolog file。
解释5:对于整个事务,为什么将redo log写入磁盘(redolog buffer --redolog file redo第四步)?
最后完成了,当然统一刷盘redolog file,要不然redolog buffer有什么用。
面试问题(单数据库宕机):flush时宕机了,如何恢复?
mysql写入数据的时候,是先把数据写到缓冲区,然后再flush到磁盘的,如果在flush过程中发生了宕机,数据如何恢复。
由WAL(Write-Ahead Logging)机制和redolog保证,事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,会持久化redo log。
第一种情况,如果在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。
第二种情况,如果在9commit执行中系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redolog file把数据刷回磁盘
1.start transaction;
2.记录 A=1 到undo log;
3.update A = 3;
4.记录 A=3 到redo log;
5.记录 B=2 到undo log;
6.update B = 4;
7.记录B = 4 到redo log;
8.将redo log刷新到磁盘 第8步,写redologfile到磁盘,以这一句为分界点
9.commit
2.4.5 分布式数据库宕机:第8步写redologfile和写 binlogfile,宕机
第一种情况,如果binlogfile写和redologfile写都成功了,那这次算是事务才会真正成功,所以,保证事务原子性(undolog)、持久性(redolog)。
所以,在使用Innodb引擎的事务操作的是时候,必须保证磁盘上的binlogfile和redologfile的数据是一致的(binlogfile代表从数据库,redologfile代表主数据库),如果不一致,那就乱套了。
事务即将结束,binlog file刷盘和redolog file刷盘
第二种情况:如果事务即将结束,binlog file写成功了,而redolog file刷盘写失败了。即内存的数据还没来得及落磁盘(即redologbuffer --redologfile),机器就挂掉了。那主从服务器的数据就不一致了。(从服务器,binlogfile本来就在主服务器磁盘上,通过binlogfile将本地事务sql操作传递过去,可以得到最新的数据,但是主服务器由于redologbuffer在内存中消失了,未完成刷盘,所以redologfile没有记载,没法恢复数据)
第三种情况:如果事务即将结束,先redologfile写成功了,而binlogfile写失败了。redologfile成功,主数据库可以成功刷盘,但是binlogfile失败,无法将主数据库的本地事务sql操作传递给从数据库,那从服务器就拿不到最新的数据了。
金手指:两阶段提交,针对最后的事务提交写binlogfile和redologfile
无论情况二还是情况三,MySQL通过两阶段提交来保证磁盘上的redologfile和binlogfile的数据是一致的。根据上面,在使用Innodb引擎的事务操作的是时候,必须保证磁盘上的binlogfile和redologfile的数据是一致的(binlogfile代表从数据库,redologfile代表主数据库),如果不一致,那就乱套了。
两阶段提交过程:
阶段1:redolog刷盘,InnoDB 事务进入 prepare 状态
阶段2:binlog 刷盘,InooDB 事务进入 commit 状态
每个事务binlog的末尾,会记录一个 XID event,标志着事务是否提交成功,也就是说,恢复过程中,binlog 最后一个 XID event 之后的内容都应该被 purge清除。
两阶段提交具体操作:最后提交阶段,我写其中的某一个log,失败了,那会怎么办?
现在我们的前提是先写redo log,再写binlog,我们来看看:
第一种情况,如果写redolog失败了,那我们就认为这次事务有问题,根据undolog回滚,不再写binlog。
第二种情况,如果写redolog成功了,写binlog,写binlog写一半了,但失败了怎么办?我们还是会对这次的事务回滚,根据undolog,将无效的binlog给删除(因为binlog会影响从库的数据,所以需要做删除操作)
三、日志系统应用:事务
事务有4种特性:原子性、一致性、隔离性和持久性,在事务中的操作,要么全部执行,要么全部不做,这就是事务的目的。事务的隔离性由锁机制实现,原子性是undo日志保证的,持久性是redo 日志保证的,redo是重做,undo是撤销。
金手指:隔离性通过MVCC实现,而MVCC通过undolog实现,持久性通过redolog实现。
该句子有误,隔离性中只有已提交读和可重复读由MVCC实现,未提交读和可序列化不是由MVCC实现。
3.1 redo log日志(保证事务的持久性,一共七点)
3.1.1 作用:Redolog的唯一作用
Redo log的主要作用是用于数据库的崩溃恢复
3.1.2 两个类型(流程的基础):Redo的类型(物理redolog和逻辑redolog,我们介绍物理redolog)
重做日志(redo log)用来保证事务的持久性,即事务ACID中的D。实际上它可以分为以下两种类型:
物理Redo日志:记录的是数据页的物理变化;记录页面的实际操作。
逻辑Redo日志:记录的是数据页的逻辑变化;不是记录页面的实际修改,而是记录修改页面的一类操作,比如新建数据页时,需要记录逻辑日志。
在InnoDB存储引擎中,大部分情况下 Redo是物理日志,而逻辑Redo日志涉及更加底层的内容,这里我们只需要记住绝大数情况下,Redo是物理日志即可,DML对页的修改操作,均需要记录Redo。
3.1.3 两个结构(流程的基础):Redolog的两个组成(内存redolog buffer+磁盘redolog file)
Redo log可以简单分为以下两个部分:
一是内存中重做日志缓冲 (redo log buffer),是易失的,在内存中
二是重做日志文件 (redo log file),是持久的,保存在磁盘中
下面介绍一个update事务的四个步骤的是时候,会涉及到这两个redo文件,内存中的redolog buffer和磁盘中的redolog file。
3.1.4 两个时机(流程的基础):什么时候写Redo?redolog写入的两个时机?(数据修改、索引修改和undo页面修改)
redolog写入的两个时机?(数据修改、索引修改和undo页面修改)
1、在数据页修改完成之后,在脏页刷出磁盘之前,写入redo日志。
注意:
(1)先修改数据,后写日志;解释:第一步是磁盘中的data到内存中的databuffer;第二步才是内存中databuffer到redolog buffer。(解释,第一步第二步无法交换,redolog中的数据只能从datalog里面来,否则没有数据源)
(2)redo日志比数据页先写回磁盘。解释:第三步是内存中的redolog buffer到磁盘中的redolog file;第四步才是内存中的data buffer到磁盘中的data。(解释,就是要redolog比数据先刷盘,redo恢复数据才有用,第三步第四步倒转redo就无法完成恢复了,没卵用)
2、聚集索引、二级索引、undo页面的修改,均需要记录Redo日志。
3.1.5 数据修改流程:redolog是怎样写的?以一个更新事务为例,Redolog写入流程?
下面以一个更新事务为例,宏观上把握redo log 流转过程,如下图所示:

第一步:先将原始数据从磁盘中读入内存中来,修改数据的内存拷贝data bufffer;
第二步:生成一条重做日志并写入redo log buffer,记录的是数据被修改后的值;
第三步:当事务commit时,将redo log buffer中的内容刷新到 redo log file,对 redo log file采用追加写的方式
第四步:定期将内存中修改的数据刷新到磁盘中
小结:一个update的更新事务,在innodb中,涉及内存部分和和硬盘部分,硬盘部分是data 和 redolog file,内存部分是data buffer和datalog buffer。好记,内存部分的都是buffer类型,硬盘部分的是data和file类型。
3.1.6 持久性(流程之后):对于这个update更新事务,redo如何保证事务的持久性?为什么说redo日志保证了事务持久性?
InnoDB是一种支持事务的存储引擎,其通过Force Log at Commit 机制实现事务的持久性,即当事务提交时,先将 redo log buffer 写入到 redo log file 进行持久化,待事务的commit操作完成时才算完成。这种做法也被称为 Write-Ahead Log(预先日志持久化),在持久化一个数据页之前,先将内存中相应的日志页持久化。
小结:redo日志比数据页先写回磁盘。
为了保证每次日志都写入redo log file,在每次将redo buffer写入redo log file之后,默认情况下,InnoDB存储引擎都需要调用一次 fsync操作,因为重做日志打开并没有 O_DIRECT选项,所以重做日志先写入到文件系统缓存。为了保证重做日志一定写入到磁盘,必须进行一次 fsync操作。fsync是一种系统调用操作,其fsync的效率取决于磁盘的性能,因此磁盘的性能也影响了事务提交的性能,也就是数据库的性能。
(O_DIRECT选项是在Linux系统中的选项,使用该选项后,对文件进行直接IO操作,不经过文件系统缓存,直接写入磁盘)
上面提到的Force Log at Commit机制就是靠InnoDB存储引擎提供的参数 innodb_flush_log_at_trx_commit来控制的,该参数可以控制 redo log刷新到磁盘的策略,设置该参数值也可以允许用户设置非持久性的情况发生,具体如下:
1、当设置innodb_flush_log_at_trx_commit参数为1时,(默认为1),表示事务提交时必须调用一次 fsync 操作,最安全的配置,保证持久性。
2、当设置innodb_flush_log_at_trx_commit参数为2时,则在事务提交时只做 write 操作,只保证将redo log buffer写到系统的页面缓存中,不进行fsync操作,因此如果MySQL数据库宕机时 不会丢失事务,但操作系统宕机则可能丢失事务。
3、当设置参数为0时,表示事务提交时不进行写入redo log操作,这个操作仅在master thread 中完成,而在master thread中每1秒进行一次重做日志的fsync操作,因此实例 crash 最多丢失1秒钟内的事务。(master thread是负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性)。
金手指:fsync和write操作实际上是系统调用函数
fsync和write操作实际上是系统调用函数,在很多持久化场景都有使用到,比如 Redis 的AOF持久化中也使用到两个函数。
fsync操作定义:将数据提交到硬盘中,强制硬盘同步,将一直阻塞到写入硬盘完成后返回,大量进行fsync操作就有性能瓶颈;
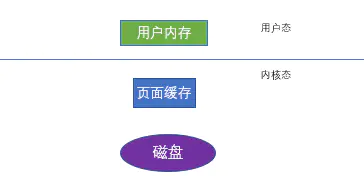
write操作定义:将数据写到系统的页面缓存后立即返回,后面依靠系统的调度机制将缓存数据刷到磁盘中去,其顺序是user buffer——page cache——>disk。
user buffer 用户内存
page cache 页面缓存
disk 硬盘
其中,在用户态就可以操作用户内存,但是,页面缓存和硬盘一定要在内核态中操作。
3.1.7 底层实现(流程之后):mini-transaction:Redolog在InnoDB中底层实现?
Redo的实现是使用mini-transaction实现的,mini-transaction是一种InnoDB内部使用的机制,通过mini-transaction来保证并发事务操作下以及数据库异常时数据页中数据的一致性,但mini-transaction不属于事务。
为了使得mini-transaction保证数据页数据的一致性,mini-transaction必须遵循以下三种协议:
The FIX Rules
Write-Ahead Log // 预先日志持久化 第三步在第四步之前,databuffer刷盘data之前,完成redologbuffer刷盘redologfile
Force-log-at-commit
The FIX Rules(作用对象是数据页)
(1)写操作-加锁:修改一个数据页时需要获得该页的x-latch(排他锁);
(2)读操作-加锁:读取一个数据页时需要该页的s-latch(读锁或者称为共享锁) 或者是 x-latch(排他锁);
(3)综合-解锁:持有该页的锁直到修改或访问该页的操作完成。
Write-Ahead Log(作用对象是数据页)
在前面阐述中就提到了Write-Ahead Log(预先写日志)。在持久化一个数据页之前,必须先将内存中相应的日志页持久化。每个页都有一个LSN(log sequence number),代表日志序列号,(LSN占用8字节,单调递增), 当一个数据页需要写入到持久化设备之前,要求内存中小于该页LSN的日志先写入持久化设备
那为什么必须要先写日志呢?可不可以不写日志,直接将数据写入磁盘?原则上是可以的,只不过会产生一些问题,数据修改会产生随机IO,但日志是顺序IO,append方式顺序写,是一种串行的方式,这样才能充分利用磁盘的性能。
Force-log-at-commit(作用对象是事务)
这一点也就是前文提到的如何保证事务的持久性的内容,这里再次总结一下,与上面的内容相呼应。
在一个事务中可以修改多个页,Write-Ahead Log 可以保证单个数据页的一致性(write ahead log 作用对象是数据页),但是无法保证事务的持久性;
Force-log-at-commit 要求当一个事务提交时(force log at commit 作用对象是事务),其产生所有的mini-transaction 日志必须刷新到磁盘中,若日志刷新完成后,在缓冲池中的页刷新到持久化存储设备前数据库发生了宕机,那么数据库重启时,可以通过日志来保证数据的完整性。
整体(the fix rules + write ahead log + force log at commit):mini-transaction实现redolog重做日志的写入流程

上图表示了重做日志的写入流程,每个mini-transaction对应每一条DML操作,比如一条update语句,其由一个mini-transaction来保证,
第一步:对数据修改后,产生redo1,首先将其写入mini-transaction私有的Buffer中,就是 redo buffer;
第二步:update语句结束后,将redo1从私有Buffer拷贝到公有的Log Buffer中,就是redo log buffer;
第三步:当整个外部事务提交时,将redo log buffer再刷入到redo log file中。
小结:写redo一共有三个:私有buffer、公有buffer和磁盘文件。
3.2 undo log日志(保证事务的原子性)
3.2.1 内容:undolog记录的内容
undo log主要记录的是数据的逻辑变化,为了在发生错误时回滚之前的操作,需要将之前的操作都记录下来,然后在发生错误时才可以回滚。只将数据库逻辑地恢复到原来的样子,用于事务的回滚操作进而保障了事务的原子性。
三个表的数据操作:
当前insert,就记录delete/truncate;
当前delete就记录insert;
当前update A->B,就记录update B->A;
两个表的结构操作:
当前drop,就记录create;
当前create,就记录drop
3.2.2 两个作用:undolog逻辑日志的两个作用(事务回滚、MVCC)
undo是一种逻辑日志,有两个作用:
(1)用于事务的回滚
(2)MVCC
这里重点关注undo log用于事务的回滚。
redo日志有两类,一类是物理日志,一类是逻辑日志;一般用物理日志,记录数据页的物理变化。
undo日志只有一个一类,就是逻辑日志,记录数据的逻辑变化。
3.2.3 两个时机:undolog的两个写入时机
1、DML操作修改聚簇索引的记录,记录undo日志
2、DML操作修改二级索引的记录,不记录undo日志
需要注意的是,undo页面的修改,同样需要记录redo日志。
回忆:redo日志写入的两个时机
redolog写入的两个时机?
1、在数据页修改完成之后,在脏页刷出磁盘之前,写入redo日志。
注意:
(1)先修改数据,后写日志;解释:第一步是磁盘中的data到内存中的databuffer;第二步才是内存中databuffer到redolog buffer。
(2)redo日志比数据页先写回磁盘。解释:第三步是内存中的redolog buffer到磁盘中的redolog file;第四步才是内存中的data buffer到磁盘中的data。
2、聚集索引、二级索引、undo页面的修改,均需要记录Redo日志。
3.2.4 undolog的存储位置
1、在InnoDB存储引擎中,undolog存储在回滚段(Rollback Segment)中(解释:每个回滚段(Rollback Segment)记录了1024个undo log segment,而在每个undo log segment段中进行undo 页的申请)。
2、在5.6以前,Rollback Segment是在共享表空间里的,5.6.3之后,可通过 innodb_undo_tablespace设置回滚段(Rollback Segment)的位置,即undo存储的位置。
3.2.5 undolog的两种类型(insert undolog、update undolog)
在InnoDB存储引擎中,undo log分为:
1、insert undo log
2、update undo log
insert undo log是指在insert 操作中产生的undo log;
因为insert操作的记录,只对事务本身可见,对其他事务不可见。故该undo log可以在事务提交后直接删除,不需要进行purge操作。
update undo log记录的是对delete 和update操作产生的undo log;
因为delete和update操作的记录,对其他事物可见,所以,该undo log可能需要提供MVCC机制,因此不能再事务提交时就进行删除。提交时放入undo log链表,等待purge线程进行最后的删除。
补充:purge线程两个作用
1、清理undo页
2、清除page里面带有Delete_Bit标识的数据行。解释:在InnoDB中,事务中的Delete操作实际上并不是真正的删除掉数据行,而是一种Delete Mark操作,在记录上标识Delete_Bit,而不删除记录。是一种"假删除",只是做了个标记,真正的删除工作需要后台purge线程去完成。
一条完整 update 语句,三个日志文件怎么搞
1、图中省略了undolog,它是和redolog同时写入的,都是由innodb存储引擎维护的,也是两阶段提交;
2、binlog日志由server层维护,redolog和undolog日志由innodb存储引擎维护,为了保证三个日志数据一直,特别是binlog和redolog数据一致,redolog/undolog这里使用两阶段提交,保证分布式(server和innodb)的一致性。

判断事务是否提交的唯一原则是 binlog 中是否有记录,就是上图中第6步是否完成。

四、日志系统应用:mysql容灾(binlog实现mysql容灾,不用记,但是面试要能够说出步骤)
4.1 需求
需求:跨服务器备份,将服务器A上的测试数据库定时备份到服务器B中
服务器A:192.168.5.193
服务器B:192.168.5.194
测试数据库TestDB
4.2 定时备份:使用crontab进行定时备份
crontab -e后
1 * * * * ~/backupDatabases.sh
以上命令使得,每小时的第一分钟,对数据库进行备份,当然也可以随意修改一些时间。
4.3 mysqldump导出数据库,mysql导入数据库(重点)
4.3.1 服务器A上的操作-增加服务器授权用户
4.3.1.1 修改服务器A上的mysql远程连接访问权限:bind-address
修改mysql的配置文件/mysql/my.conf,将bind-address后面增加远程访问IP地址或者禁掉这句话就可以让远程机登陆访问了。
4.3.1.2 在服务器A上新增一个用户
命令:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
实际:
CREATE USER 'why'@'192.168.5.194' IDENTIFIED BY '123456';
三个参数说明:username password host
username:你将创建的用户名
host:指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符%
password:该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
4.3.1.3 对服务器A上刚刚新增的用户授权
命令:
GRANT privileges ON databasename.tablename TO 'username'@'host'
flush privileges; /*刷新一下权限*/
实际:
GRANT privileges ON *.* TO 'why'@'192.168.5.194';
flush privileges; /*刷新一下权限*/
五个参数说明:
privileges:用户的操作权限,如SELECT,INSERT,UPDATE等,如果要授予所的权限则使用ALL
databasename:数据库名
tablename:表名,如果要授予该用户对所有数据库和表的相应操作权限则可用表示,如.*
username:指定用户,一般是是刚刚新建的用户,否则你新建那个用户干嘛
host:指定用户在哪个主机可以登录
4.3.1.4 实践:服务器A上的操作:新建用户 + 增加服务器授权用户
本测试实例mysql语句为:
CREATE USER 'why'@'192.168.5.194' IDENTIFIED BY '123456';
GRANT privileges ON *.* TO 'why'@'192.168.5.194';
flush privileges; /*刷新一下权限*/
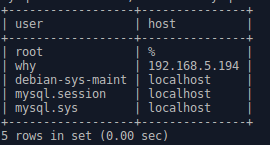
这样就建立了如下的用户权限表,查看新建的用户和允许用户在哪个主机上访问。
select user,host from mysql.user;
4.3.2 服务器B上的操作-执行备份,先导出,后导入
服务器B就是192.168.5.194,服务器A中新建why用户,且这个用户只能在192.168.5.194上连接服务器A,且密码要正确。
4.3.2.1 在服务器B上编写如下脚本
#!/bin/bash
my_user=why #服务器A的用户(必须是已经授权的,刚才在服务器A上新建用户并授权)
my_pass=123456 #服务器A的用户密码
my_host=192.168.5.193 #要连接的服务器A的地址
my_db1=TestDB #想要导出的服务器A的数据库,要想导入的服务器B的数据库(需要授权)
mm_dir=/home/fabric/backup/t2.sql #导出到服务器B的路径地址
mysqldump_cmd=/usr/bin/mysqldump #mysqldump的可运行指令地址
local_usr=root #本地数据库的用户名
local_pass=000000 #本地数据库的密码
mysql_cmd=/usr/bin/mysql #mysql的可运行指令地址
4.3.2.2 执行备份(先导出,再导入)
$mysqldump_cmd -h $my_host -u $my_user -p$my_pass $my_db1 $mm_dir
$mysql_cmd -u $local_usr -p$local_pass $my_db1 < $mm_dir
解释:$mysqldump_cmd -h $my_host -u
m
y
u
s
e
r
−
p
my_user -p
myuser−pmy_pass $my_db1 $mm_dir
参数就是配置文件里面:mysqldump_cmd表示执行本地的/usr/bin/mysqldump程序
my_host 指定要连接的服务器A的地址
my_user 指定服务器A的用户(必须是已经授权的,刚才在服务器A上新建用户并授权)
my_pass 指定服务器A的用户密码
my_db1 指定想要导出的服务器A的数据库(需要授权,服务器A上授权用户的时候授权)
mm_dir 指定导出到服务器B的路径地址
解释:导出语句,将服务器A的某个数据库my_db1 导出到服务器B的指定地址mm_dir ,
要完成这一操作,需要服务器A提供权限my_host my_user my_pass
需要服务器B提供/usr/bin/mysqldump程序
解释:$mysql_cmd -u
l
o
c
a
l
u
s
r
−
p
local_usr -p
localusr−plocal_pass $my_db1 < $mm_dir
mysql_cmd 指定指定本地的/usr/bin/mysql程序
local_usr 指定本地数据库的用户名
local_pass 指定本地数据库的密码
my_db1 指定要想导入的服务器B的数据库
mm_dir 指定服务器B的路径地址
解释:导入语句,将服务器B指定地址mm_dir的文件导入到服务器B的某个数据库my_db1,要完成这一操作,需要服务器B提供权限local_usr local_pass
需要服务器B提供/usr/bin/mysql程序
4.3.2.3 查看服务器A上的数据
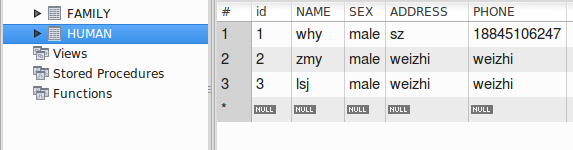
Family表和human表

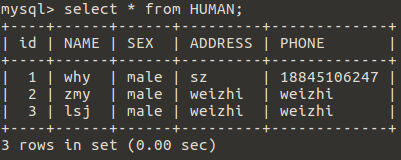
4.3.2.4 运行如上脚本后,查看服务器B的数据,可以看到这里备份成功了

4.3.3 mysqldump备份原理
使用mysqldump命令备份的底层原理
mysqldump命令将数据库中的数据备份成一个sql文本文件。表的结构和表中的数据将存储在生成的文本文件中。
mysqldump命令的工作原理很简单。它先查出需要备份的表的结构,再在文本文件中生成一个CREATE语句。然后,将表中的所有记录转换成一条INSERT语句。然后通过这些语句,就能够创建表并插入数据。
导出的sql文本文件解析
文件的开头会记录MySQL的版本、备份的主机名和数据库名。
文件中以“–”开头的都是SQL语言的注释,以"/!40101"等形式开头的是与MySQL有关的注释。40101是MySQL数据库的版本号,如果MySQL的版本比4.1.1高,则/!40101和*/之间的内容就被当做SQL命令来执行,如果比4.1.1低就会被当做注释。
附:导出多个数据库
定义:
mysqldump -u username -p --databases dbname2 dbname2 Backup.sql
加上了–databases选项,然后后面跟多个数据库
实际:
mysqldump -u root -p --databases test mysql D:\backup.sql
附:备份所有数据库
mysqldump命令备份所有数据库的语法如下:
mysqldump -u username -p -all-databases BackupName.sql
示例:
mysqldump -u -root -p -all-databases D:\all.sql
附:导入数据库语法:
mysql -u root -p [dbname] < backup.sql
示例:
mysql -u root -p < C:\backup.sql
4.4 直接复制整个数据库目录 + 直接还原复制目录的备份(仅适用于MyISAM类型表)
4.4.1 直接复制整个数据库目录
MySQL有一种非常简单的备份方法,就是将MySQL中的数据库文件直接复制出来。这是最简单,速度最快的方法。
不过在此之前,要先将服务器停止,这样才可以保证在复制期间数据库的数据不会发生变化。如果在复制数据库的过程中还有数据写入,就会造成数据不一致。这种情况在开发环境可以,但是在生产环境中很难允许备份服务器。
注意:这种方法不适用于InnoDB存储引擎的表,而对于MyISAM存储引擎的表很方便。同时,还原时MySQL的版本最好相同。
4.4.2 直接还原复制目录的备份
通过这种方式还原时,必须保证两个MySQL数据库的版本号是相同的。MyISAM类型的表有效,对于InnoDB类型的表不可用,InnoDB表的表空间不能直接复制。
4.5 使用mysqlhotcopy工具快速备份(仅适用于MyISAM类型表)
一看名字就知道是热备份。因此,mysqlhotcopy支持不停止MySQL服务器备份。而且,mysqlhotcopy的备份方式比mysqldump快。mysqlhotcopy是一个perl脚本,主要在Linux系统下使用。其使用LOCK TABLES、FLUSH TABLES和cp来进行快速备份。
原理:先将需要备份的数据库加上一个读锁,然后用FLUSH TABLES将内存中的数据写回到硬盘上的数据库,最后,把需要备份的数据库文件复制到目标目录。
命令格式如下:
[root@localhost ~]# mysqlhotcopy [option] dbname1 dbname2 backupDir/
dbname:数据库名称;
backupDir:备份到哪个文件夹下;
常用选项:
–help:查看mysqlhotcopy帮助;
–allowold:如果备份目录下存在相同的备份文件,将旧的备份文件加上_old;
–keepold:如果备份目录下存在相同的备份文件,不删除旧的备份文件,而是将旧的文件更名;
–flushlog:本次辈分之后,将对数据库的更新记录到日志中;
–noindices:只备份数据文件,不备份索引文件;
–user=用户名:用来指定用户名,可以用-u代替;
–password=密码:用来指定密码,可以用-p代替。使用-p时,密码与-p之间没有空格;
–port=端口号:用来指定访问端口,可以用-P代替;
–socket=socket文件:用来指定socket文件,可以用-S代替;
mysqlhotcopy并非mysql自带,需要安装Perl的数据库接口包;下载地址为:http://dev.mysql.com/downloads/dbi.html
目前,该工具也仅仅能够备份MyISAM类型的表。
面试金手指:谈一谈mysql容灾
mysql容灾就是要在服务器宕机的情况下保留数据,因为服务器不能保证永远不宕机,所以mysql容灾就是mysql备份
四种备份方式:
定时备份:使用crontab进行定时备份
mysqldump导出数据库,mysql导入数据库(重点)
直接复制整个数据库目录 + 直接还原复制目录的备份(仅适用于MyISAM类型表)
使用mysqlhotcopy工具快速备份(仅适用于MyISAM类型表)















 6751
6751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











