1 建立模型
1.1 数据导入
train = pd.read_csv('titanic/titanic_train.csv')
data = pd.read_csv('titanic/clear_data.csv')
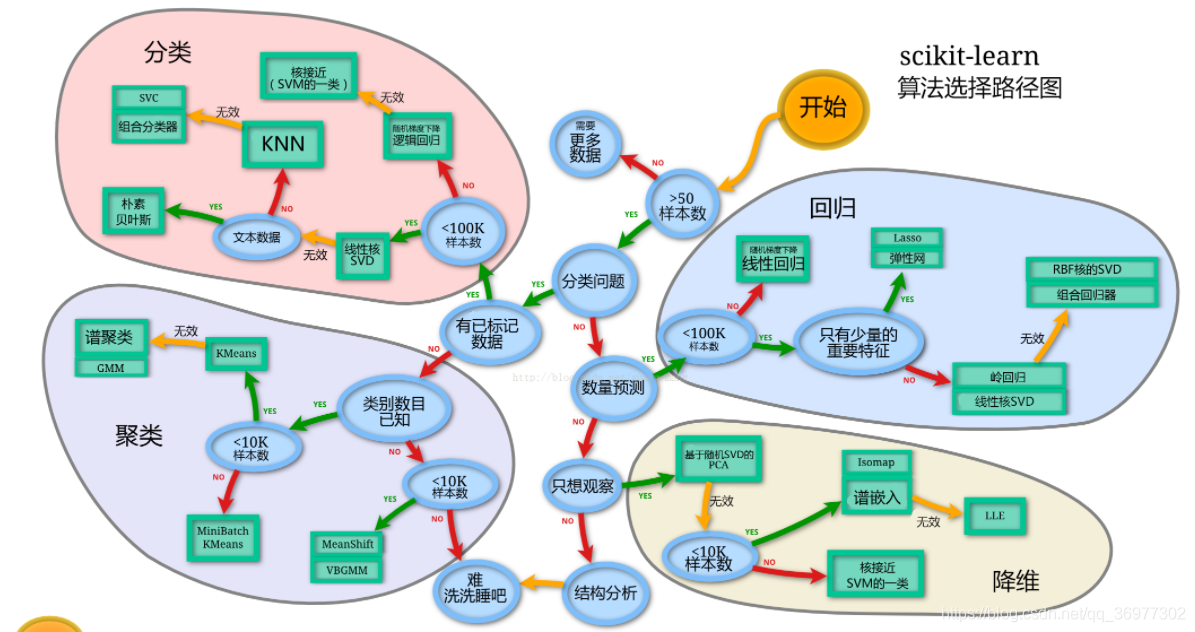
1.2 模型选择
- 判断数据集最终是进行监督学习还是无监督学习 ,通过我们要完成的任务,以及数据样本量,特征的稀疏性等来决定
- 通常先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型
- 使用机器学习最常用的一个库(sklearn)来完成我们的模型的搭建
1.3 建模
1.3.1 切割训练集与测试集
from sklearn.model_selection import train_test_split
X = data.drop(['Survived'],axis=1)
print(data.shape,X.shape)
y = data['Survived']
(891, 19) (891, 18)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
1.3.2 逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
print("训练集score:{:.2f}".format(lr.score(X_train, y_train)))
print("测试集score: {:.2f}".format(lr.score(X_test, y_test)))
训练集score:0.81
测试集score: 0.80








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









