







 本文深入探讨了实地址执行环境下的寄存器和指令集,包括32位和16位寄存器的作用,以及段寄存器在存储器分段管理中的应用。详细讲解了实方式下的指令指针和堆栈指针特性,存储段的限制条件,以及段寄存器的正确使用方法。此外,还介绍了16位存储器寻址方式,系统功能调用,以及使用NASM汇编器生成二进制代码的具体步骤。
本文深入探讨了实地址执行环境下的寄存器和指令集,包括32位和16位寄存器的作用,以及段寄存器在存储器分段管理中的应用。详细讲解了实方式下的指令指针和堆栈指针特性,存储段的限制条件,以及段寄存器的正确使用方法。此外,还介绍了16位存储器寻址方式,系统功能调用,以及使用NASM汇编器生成二进制代码的具体步骤。
实地址执行环境
寄存器和指令集
- 32位寄存器EAX、EBX、ECX、EDX、ESP、EBP、ESI和EDI;
- 16位寄存器AX、BX、CX、DX、SP、BP、SI和DI;
- 8位寄存器AH、AL、BH、BL、CH、CL、DH和DL。
- 段寄存器CS、DS、SS和ES,以及段寄存器FS和GS。寄存器CS含有当前代码段的段值,寄存器DS含有当前数据段的段值,寄存器SS含有当前堆栈段的段值。
- 实方式下指令指针寄存器EIP中的高16位必须是0,相当于只有低16位的IP起作用。
- 实方式下堆栈指针寄存器ESP中的高16位必须是0,相当于只有低16位的SP起作用。
存储器分段管理
IA-32系列处理器的物理地址空间规模达到4G,实地址方式下可访问的物理地址空间只有1M即00000H——FFFFFH,实方式下每个逻辑段必须满足如下两个条件:
- 逻辑段的起始地址必须是16的倍数
- 逻辑段的最大长度为64K(2^16),所以后面用16位表示段值?
这两个条件是为了方便地计算1M地址空间中的20位地址。
由于实方式下段的起始地址必须是16的倍数,所以段的起始地址有如下形式:xxxx0H,这种20位的段起始地址可以省略掉最后的0表示成16位的XXXXH形式,这16位就称为段值。这时候就有如下关系:
段起始地址=段值*16
物理地址=段起始地址 偏移=段值*16 偏移
注意存储段既可以相连,也可以重叠。所以一个物理地址可以对应多个逻辑地址,比如:
1002H:2325H=12345H
1233H:0015H=12345H
上面两个逻辑地址就表示的是一个物理地址。
实地址方式下,段寄存器(CS、SS、DS…)中的内容是段值。
这里需要注意的是给段寄存器赋值的时候只能通过别的寄存器来进行中转赋值,不能直接把立即数赋值给段寄存器,应该像这样:
MOV AX,0F0000H
MOV DS,AX
而不是:
MOV DS,0F0000H
手动指定段寄存器的方法:
MOV [ES:EDI] ,EAX
16位存储器寻址方式
16位的存储器寻址方式主要用于实地址,在实地址方式下,存储段的长度不超过64K(32位寻址方式的存储段长度也不超过64K),注意这里是存储段的长度而不是上面的逻辑段长度,存储单元有效地址是16位。
16位有效地址EA可以有多种表示形式:
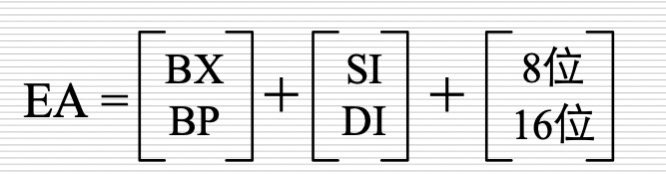
主要形式是基址 变址 位移量,其中:
- 基址部分可以是寄存器BX或BP;
- 变址部分可以是寄存器SI或DI;
- 位移量采用补码形式表示,在计算有效地址时,如位移量是8位,则被带符号扩展成16位。
需要注意的是,像下面这种寻址方式就是错误的:
MOV EAX,[SI DI]
很明显SI不能作为基址部分。
源程序和语句
首先再强调几点概念:
- 汇编语言是一种程序设计语言,是机器语言的符号化。
- 汇编语言的语句主要是汇编格式指令和伪指令。
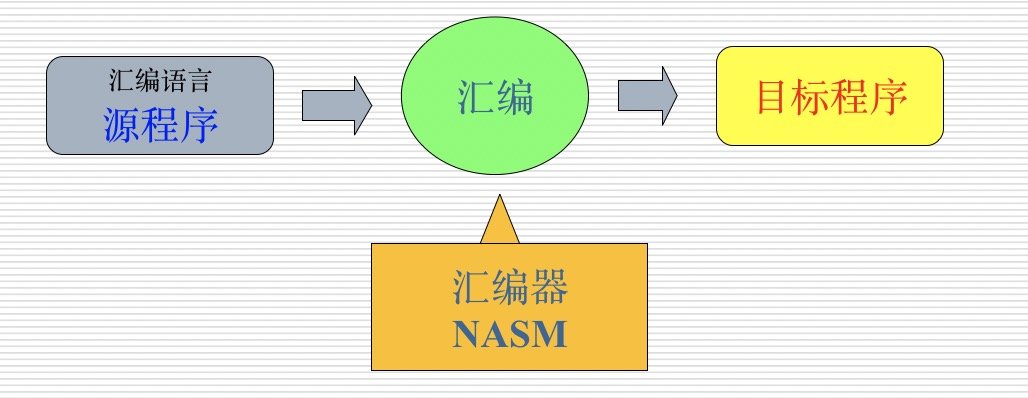
- 把用汇编语言编写的程序称为汇编语言源程序,或称为汇编源程序,或简称为源程序。
- 把汇编源程序翻译成目标程序的过程称为汇编。
- 完成汇编工作的工具或程序叫做汇编程序。
汇编过程示意图如下:
汇编语言源程序
系统功能调用
系统功能说白了就是操作系统提供的子程序,其也有入口参数和出口参数,只不过调用系统功能是采用编号的方式而不是采用程序名称的方式,DOS操作系统下:
- 编号为9的系统功能是显示输出一个以‘$结尾的字符串,入口参数为字符串首地址,DS是首地址段值,DX是首地址偏移。
- 编号为0AH的系统功能是输入一个字符串到指定缓冲区,DS是缓冲区段地址,DX是首地址偏移
- 编号为1的系统功能是接受用户按键,用户按键之后的内容放在AL寄存器中
- 编号为2的系统功能是输出一个字符,字符放在DL中
- 编号为4CH的系统功能是结束程序运行,返回DOS
调用系统功能的步骤:
- 根据相应功能填好对应参数
- 将系统功能号放入寄存器AH中
- 执行指令INT 21H
其中的INT 21H是一条软中断指令。
比如:
//显示字符串
MOV DX, hello ;准备参数
MOV AH, 9 ;9号功能
INT 21H ;调用
;
//结束程序返回DOS
MOV AH, 4CH ;4CH号功能
INT 21H ;调用
汇编
使用NASM汇编器
使用NASM汇编器生成纯二进制代码文件(***COM***类型的可执行程序)的方法:
nasm demo.asm -f bin -o demo.com
//命令名称-源程序文件名-格式项-纯二进制格式-目标文件名
语句及其格式
语句的种类
汇编语言(NASM)有四种类型的语句:
指令语句–指令
指令语句就是表示汇编格式指令的语句,也就是表示符号化的机器指令的语句。用符号表示的机器指令被称为汇编格式的指令。汇编器在对源程序进行汇编时,把指令语句翻译成机器指令。
伪指令语句–伪指令
伪指令语句就是表示伪指令的语句。
伪指令并非真正符号化的机器指令。对处理器而言,伪指令不是指令,但对汇编器而言,它却是指令。伪指令主要用于定义变量,预留存储单元。
也就是说,伪指令是为了汇编器存在的,而不是处理器。
比如伪指令可以用来定义数据,安排空间:
prompt db "Press a key: ", '$'
newline db 0DH, 0AH, '$'
result db 0, 0
宏指令语句—宏指令
宏指令语句表示宏指令。宏指令也被简称为宏,与高级语言中宏的概念相同,就是代表一个代码片段的标识符。宏指令在使用之前要先声明。
指示语句–指示
指示(directive)也常被称为汇编器指令或汇编指令,它指示汇编器怎样进行汇编,如何生成目标代码。为了避免与汇编格式指令相混淆,所以把它称为“指示”。
操作数表示
常数
主要有4种不同类型的常数:整数、字符、字符串、浮点数。
整数
- 在没有特别标记时,一个整数由十进制表示。
- 可以采用十六进制、八进制和二进制形式表示整数。
- 后缀H表示十六进制数,后缀Q或O表示八进制数,后缀B表示二进制数。当然也可以用后缀D表示十进制数。
- 为了避免与普通标识符混淆,十六进制数应以数字开头,如果以字母开头,应该再冠以数字0。还可以采用C风格的前缀0x表示十六进制数。
字符
- 字符常数是一对单引号(或双引号)之间的若干个字符。
- 每个字符表示一个字节(8个二进制位),可以认为字符的值是对应ASCII码值。
- 在表示32位数据时,包含在一对引号中的字符常数最多可以由4个字符组成。
- 对于由多个字符组成的字符常数,在存储时出现在前面的字符占用低地址存储单元。这样,按照**“高高低低”**存储规则,出现在前面的字符代表了数值的低位。
示例:
MOV AL, 'a' //AL=61H
MOV AX, 'a' //AX=0061H
MOV AX, 'ab' //AX=6261H,注意看这里,a存储在了低位,b存储在了高位
MOV EAX, 'abcd' //EAX=64636261H
MOV BX, 'abcd' //BX=6261H,该字符常数过大,汇编器NASM会给出警告,并抛弃高位部分
字符串
字符串常数与字符常数很相近,但是字符串常数可以含有更多的字符。
数值表达式
- 由运算符和括号把常数、记号和标识符等连接起来的式子,被称为表达式。
- 所谓数值表达式是指在汇编过程中能够由汇编器计算出具体数值的表达式。
- 组成数值表达式的各部分必须在汇编时就能完全确定
常见运算符及其优先级:
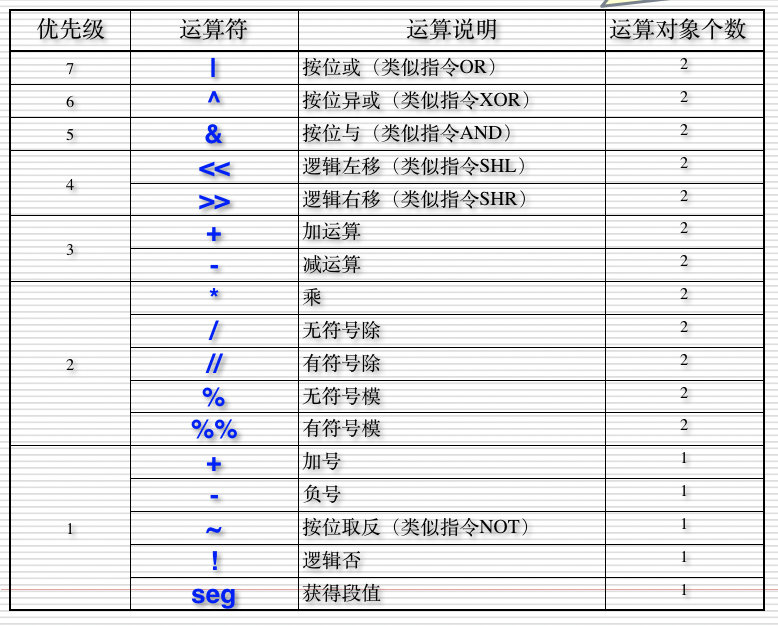
使用举例:
MOV AL, 01000111B | 00100000B ;AL=67H
MOV AL, 01101000B & 11011111B ;AL=48H
MOV AL, 03H << 4 ;AL=30H
MOV AL, 80H >> 6 ;AL=02H
MOV AL, ~ 00000001B ;AL=FEH
MOV AL, ! 1 ;AL=00H
MOV AL, -1 ;AL=FFH
数据类型说明
大部分情况下,能够根据存放操作数的寄存器来确定操作数的类型(尺寸)。
但类似如下指令,操作数类型不明确,NASM会报告错误:
MOV [BX], 1
ADD [DI 3], 5
SUB [ESI ECX*4], 6
汇编器NASM提供了BYTE、WORD、DWORD等关键字,用于说明操作数的类型(尺寸)。把这些关键词称之为类型符。在VC2010的嵌入汇编或者生成的汇编格式目标代码中,对应的类型符后面要加一个‘PTR’。
使用示例:
MOV DWORD [BX], 1 ;双字
ADD BYTE [DI 3], 5 ;字节
SUB WORD [ESI ECX*4], 6 ;字
;
MOV [BX], DWORD 1 ;双字
ADD [DI 3], BYTE 5 ;字节
SUB [ESI ECX*4], WORD 6 ;字
PUSH WORD 99H
对于把立即数压入堆栈的PUSH指令,在16位代码中默认的操作数是字,在32位代码中默认的操作数是双字,所以需要明确操作数类型。
由于PUSH指令的操作数至少是16位的,所以不能使用类型符BYTE。
伪指令语句和变量
伪指令语句就是表示伪指令的语句。伪指令并非真正符号化的机器指令。对处理器而言,伪指令不是指令,但对汇编器而言,它却是指令。伪指令主要用于定义变量,预留存储单元。
伪指令语句主要有数据定义语句(定义初始化的数据项)和存储单元定义语句(定义未出初始化的数据项)。
数据定义语句
格式:
[名字] DB 参数表 ;定义字节数据项
[名字] DW 参数表 ;定义字数据项
[名字] DD 参数表 ;定义双字数据项
DB、DW、DD分别是伪指令符,D代表define,名字是可选的,如果使用名字,那么它就代表存储单元的有效地址。确切地说,名字代表语句所定义的若干数据项中,第一个数据项对应存储单元的有效地址。
通过数据定义语句可为数据项分配存储单元,并根据需要设置其初值。还可用名字(标识符)代表数据项。
举例:
wordvar dw 1234H, 55H//定义了两个长度为word的数据,首地址/名字是wordvar
dvar dd 99H
abcstr db 'A', 'B', 0DH, 0AH, '$'//定义了四个长度为byte的数据,首地址/名字是abcstr
执行完之后的内存单元存储图如下:
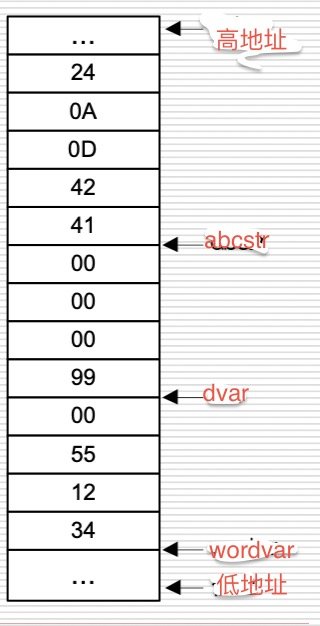
注意这里的存储原则也是“高高低低”。
存储单元定义语句
格式:
[名字] RESB 项数 ;预留字节存储单元
[名字] RESW 项数 ;预留字存储单元
[名字] RESD 项数 ;预留双字存储单元
名字可选,代表预留存储单元的首地址。
“项数”表示要定义的存储单元个数,可以是一个数值表达式。RESB、RESW或RESD分别是伪指令符。RES的含义是**“预留”**,其后字母代表存储单元类型,字节(Byte)、字(Word)和双字(DoubleWord)。
存储单元定义语句是伪指令语句。
利用存储单元定义语句可以分配存储单元,但没有初始化。可用名字代表存储单元。如果把这样的存储单元视作为变量,那么就是没有初始化的变量。
举例:
buffer resb 128 //预留128个字节
wordtab resw 4 //预留4个字
farptr resd 1 //预留1个双字
abuff resb 32*2 //预留64个字节
wtable resw 3 5 //预留8个字
**“项数”**可以是一个数值表达式,但必须是马上可以计算出结果的表达式,不能是类似于EAX EBX这样的在汇编执行时才能算出来的,因为伪指令语句是汇编层面的,不是处理器层面的。
常数符号声明语句
格式:
符号名 EQU 数值表达式
汇编过程中,NASM会计算出数值表达式的值,然后符号就代表计算结果。在随后的程序中,就可以使用该符号代替这个表达式。
举例:
COUNT equ 5 3*2 ;COUNT代表11
MIN equ 8 ;MIN代表8
MAX equ MIN COUNT 20 ;MAX代表39
两个特别的符号
汇编器NASM支持在表达式中出现两个特别的记号,即’ ′ 和 ′ '和' ′和′$’。
利用这两个记号,可以方便地获得当前位置值。
$代表它所在源代码行的指令或者数据在段内的偏移,或者就是当前位置在段内的偏移。
比如:
jmp $
代表在当前位置无限循环。
段声明和段间转移
段声明语句
段声明语句属于指示语句。它指示汇编器,开始一个新的段,或者从当前段切换到另一个段。
格式1:
section 段名 [段属性] [;注释]
格式2:
segment 段名 [段属性] [;注释]
使用举例:
section code//声明段code
..start://开始地址
MOV AX, data
MOV DS, AX
MOV DX, hello
CALL Print_str
MOV AH, 4CH
INT 21H
over:
;
section data//声明段data
hello db "Hello world!", 0DH, 0AH, 24H
section code//切换到段code
Print_str:
MOV AH, 9
INT 21H
RET
上面的代码经过汇编和连接后可生成exe类型的可执行文件,在Windows控制台窗口利用以下汇编和链接命令即可生成exe的可执行程序:
NASM demo.asm -f obj -o demo.obj
LINK demo
-o表示目标文件是obj格式,LINK后的demo表示生成demo.exe。
无条件段间转移指令
格式1:
JMP SNAME:LABEL//JMP 段名:标号
格式2:
JMP FAR OPRD(LABEL)//JMP 类型说明符 标号/双字存储单元
在实方式下,操作数OPRD应该是一个双字存储单元。FAR是类型符,明确表示段间转移(远转移)。
指令把双字存储单元OPRD中的一个字(高地址的字)作为16位的段值送到代码段寄存器CS,把双字中的另一个字(低地址的字)作为16位的偏移送到指令指针寄存器IP,从而实现转移。
示例代码:
section codeA
..start:
MOV AX, data
MOV DS, AX
MOV DL, [flagch]
MOV AH, 2
INT 21H
//1:
JMP codeB:step2
step4:
MOV DL, [flagch]
MOV AH, 2
INT 21H
MOV AH, 4CH
INT 21H
section data align=16
flagch db "ABC"
section codeC align=16
step3:
MOV DL, [flagch 2]
MOV AH, 2
INT 21H
//2:
JMP FAR step4
section codeB align=16
step2:
MOV DL, [flagch 1]
MOV AH, 2
INT 21H
//3:
JMP codeC:step3
段间过程调用和返回指令
IA-32处理器支持存储器分段管理。
通常一个程序可以含有多个段,不仅代码和数据可以各自独立,而且根据需要不同功能的代码也可以占用不同的段。
段间转移
格式1:
CALL SNAME : LABEL
格式2:
CALL FAR LABEL/OPRD
背后的步骤:
- 首先把返回地址的段值和偏移压入堆栈,注意段内过程调用是只压了EIP值即偏移。
- 然后把双字存储单元OPRD中的一个字(高地址的字)作为16位的段值送到CS,把双字中的另一个字(低地址的字)作为16位的偏移送到IP,从而转移到子程序。
段间返回
格式1:
RETF
在实方式下,指令从堆栈先后弹出返回地址的偏移和段值,分别送到IP和CS,从而实现子程序的段间返回。
格式2:
RETF count
指令在实现段间返回的同时,再额外根据count值调整堆栈指针。在实方式下具体操作是,先从堆栈弹出返回地址的偏移和段值(当然,会调整堆栈指针SP),再把count加到SP上。
示例代码:
section codeA align=16
..start:
MOV AX, CS
MOV DS, AX
MOV AX, codeC
CALL FAR [ptsubr]//段间间接调用
MOV DL, 0DH
CALL codeC:PutChar//段间直接调用
MOV DL, 0AH
CALL codeC:PutChar//段间直接调用
MOV SI, ptsubr
MOV AX, codeB
CALL FAR [SI]//段间间接调用
MOV AH, 4CH
INT 21H
ptsubr dw echo4
dw codeB
section codeB align=16
ToASCII:
AND DL, 0FH
ADD DL, '0'
CMP DL, '9'
JBE lab1
ADD DL, 7
lab1:
RET
echo4:
MOV CX, 4
MOV BX, AX
next:
ROL BX, 4
MOV DL, BL
CALL ToASCII
CALL codeC:PutChar//段间直接调用
LOOP next
MOV DL, 'H'
CALL codeC:PutChar
RETF//段间返回
section codeC align=16
PutChar:
MOV AH, 2
INT 21H
RETF//段间返回
目标文件和段模式
目标文件
不同的操作系统,对可执行文件的格式有不同要求。为了满足不同要求,有多种不同格式的目标文件。这些不仅与操作系统有关,也与汇编器和链接器有关。
纯二进制目标文件
纯二进制目标文件,只含有对应源程序的二进制代码,也即二进制形式的机器指令和数据,并不含有其他信息。纯二进制目标文件有时很有用,尤其在没有操作系统的场合。
使用nasm生成纯二进制代码文件的方法:
nasm xxx.asm -f bin -o xxx.com
nasm xxx.asm -o xxx.com //缺省bin(纯二进制)格式
nasm xxx.asm -o yyy //目标文件名可以没有后缀
Windows(32位版本)仍然支持以纯二进制目标文件形式存在的可执行程序,只要其扩展名是.com。为了运行这样的可执行程序,操作系统(Windows中的DOS)总是把纯二进制文件加载到内存代码段的偏移100H开始处,执行起始点偏移也是100H。
这就是为什么:
section code
org 100H//指示段的起始偏移
begin:
MOV AX, begin ;把标号begin代表的偏移送到AX,AX=0100H
MOV AX, $ ;把当前偏移送到AX,AX=0103H
。。。。
这样的代码中org的值一般设为100H。
obj目标文件
obj格式目标文件适用于生成EXE类型的可执行程序。早先的DOS操作系统下,可执行程序主要是EXE类型。由汇编器对源程序汇编生成obj格式目标文件,由链接器对obj格式目标文件链接后,生成EXE类型的可执行程序。
obj格式目标文件不仅含有对应源程序的机器指令和数据,而且还含有其他重要信息。例如,支持引用段值的信息。又如,程序开始执行位置的信息。所以,obj格式目标文件要比纯二进制目标文件来得长。
在用于生成obj格式目标文件的源程序中,段名代表段值,所以可以通过段名来引用段值。还可以利用运算符seg,获取标号所在段的段值。但是,在这样的源程序中,不能安排起始偏移设定语句org。在多个由链接器链接到一起的目标文件中,有且只能有1个目标文件含有开始执行的位置。就汇编器NASM而言,程序开始执行的位置,在源程序中由特定的标号**…start**给出。
段模式声明语句
无论是保护方式还是实方式,IA-32系列处理器都支持8位、16位和32位的操作数,都支持16位和32位的存储器寻址方式。
为了保持兼容,同时保证效率,IA-32系列处理器支持两种段模式,也即32位段模式和16位段模式。在保护方式下,一般采用32位段;在实方式下,只能使用16位段:
-
对于32位段,缺省的操作数尺寸是8位和32位,缺省的存储器寻址方式是32位。
-
对于16位段,缺省的操作数尺寸是8位和16位,缺省的存储器寻址方式是16位。
段模式声明语句的格式
BITS 32
BITS 16
第一条指示汇编器NASM按32位段模式来翻译随后的代码;
第二条指示按16位段模式来翻译随后的代码。
比如:
segment text
org 100H ;设起始偏移100H
MOV AX, CS
MOV DS, AX
bits 16 ;声明16位段模式
MOV AL, 1 ;B0 01
MOV AX, 1 ;B8 01 00
bits 32 ;声明32位段模式
MOV AL, 1 ;B0 01
MOV AX, 1 ;66 B8 01 00
宏
宏指用一个符号表示多个符号,或者代码片段。
在源程序中使用宏的优点:
-
可以减少重复书写,简化源程序
-
可以实现整体替换,维护源程序
汇编中的宏类似于高级语言中的宏。
宏指令的声明和使用
宏指令的声明指,说明宏指令(宏)与由它代表的多个符号或代码片段之间的替代关系。
格式1:
%macro 宏指令名 参数个数
......
%endmacro
举例:
声明一个宏,其接受从键盘输入一个键
%macro GetChar 0
MOV AH, 1
INT 21H
%endmacro
接收参数的举例:
声明一个宏,其把一个双字存储单元的内容,送到另一个存储单元
%macro MOVED 2
PUSH EAX
MOV EAX, %2
MOV %1, EAX
POP EAX
%endmacro
调用:
MOVED EAX,EBX
单行宏的声明和使用
单行宏指,一个符号代表多个符号,由一行表示之。
格式:
%define 宏名(参数表) 宏体
可以没有参数表,如果没有参数表,那么也不需要圆括号。
示例:
%define count 12
%define array(a,i) dword [a 4*i]//注意这里加入了参数
宏相关方法
宏名的脱敏
说白了就是想办法让宏名变为大小写不敏感 的,方法:

















 3224
3224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









