







本文转载自知乎用户吕昱峰 https://www.zhihu.com/people/lu-yu-feng-46-1
https://www.zhihu.com/people/lu-yu-feng-46-1
OOM与梯度累加
Out of memory
先来说下OOM问题,其实也是日常会遇到的情况。如下图所示,模型申请的显存超过了设备实际显存大小,则会报错Out of Memory。一般情况下,batch size设置过大,或者本身自己手里的计算设备(GPU、NPU等)显存较小,会经常触发这个问题。
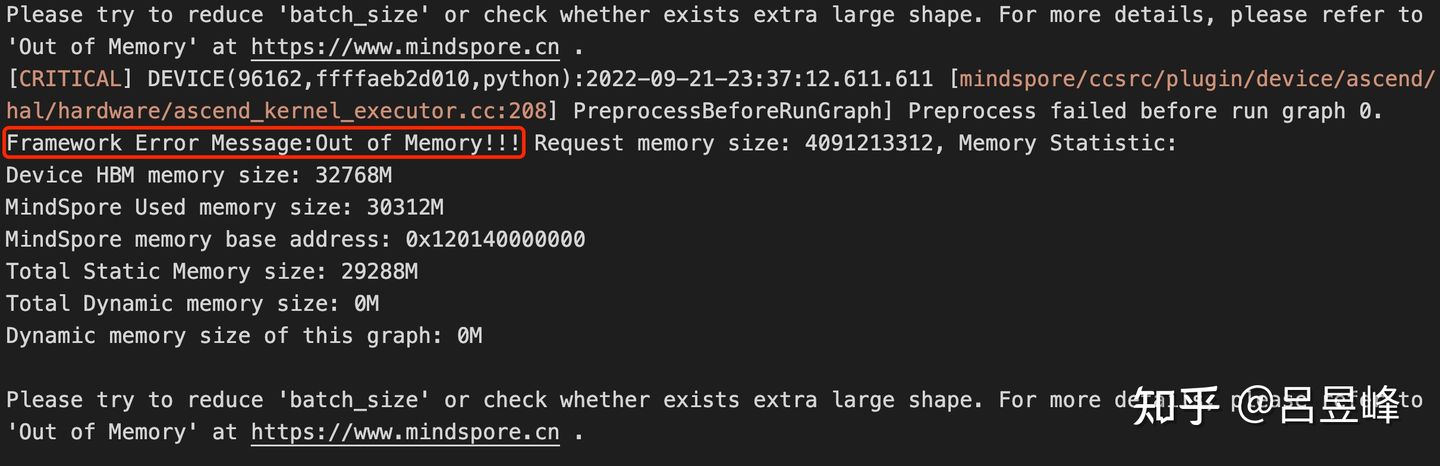
MindSpore在Ascend上显存不足的报错
一般遇到这个情况,都会选择调小batch size,但是很多模型本身就非常大(尤其是预训练模型当道的今天),记得19年的时候拿一张1080ti做BERT finetune,11G的显存,batch size最大也就就能设置成4。但是batch size又是很影响训练效果的超参,在很多时候只能在原作者调参得到的那个数值下才能训练出较好的结果。此时,有钱就选择加卡,不然就只能另辟蹊径来磨一磨手里这张小显存的计算卡了。
Gradient Accumulation
梯度累加,顾名思义,就是将多次计算得到的梯度值进行累加,然后一次性进行参数更新。如下图所示,假设我们有batch size = 256的global-batch,在单卡训练显存不足时,将其分为多个小的mini-batch(如图分为大小为64的4个mini-batch),每个step送入1个mini-batch获得梯度,将多次获得的梯度进行累加后再更新参数,以次达到模拟单次使用global-batch训练的目的。
简单来说:时间换空间。加长训练时间,来换取大batch在小设备上可训练。

梯度累加示例
再来看参数更新过程,以随机梯度下降(Stochastic Gradient Descent)为例,使用global batch训练时,参数更新公式为:
其中
为模型的参数(weight或bias), 为学习率,
为梯度。
当使用梯度累加时,
,
为拆分的mini-batch数,此时,参数更新公式变为:
自动微分机制和梯度累加实现
由于不同深度学习框架的自动微分机制不同,所以实现梯度累加的方式有显著差异。当前业界框架的自动微分机制分为两类:
- 以Tensor为核心的自动微分,Tensor可配置
requires_grad参数控制是否需要梯度。每个Tensor对象有grad_fn属性用来存储该Tensor参与的反向操作,同时还有grad属性,存储该Tensor对应的梯度。计算梯度时通过标量loss.backward()实现。由于API接口使用方式很符合反向传播的概念,业界多数框架选择此方案,如Pytorch、Paddle、Oneflow、MegEngine等。 - 函数式自动微分。将神经网络正向计算视作输入到Loss的计算函数,通过函数变换获得反向计算函数,并调用反向计算函数来获得梯度。业界采用此方案的框架有Jax、MindSpore,此外Tensorflow的GradientTape本质上也可以视作该方案的变种。
自动微分原理都是一致的,这两种方案的核心差异点在于是否暴露了自动微分更底层的接口,如Pytorch等框架更多定位纯深度学习,此时只体现backward更符合目标用户的使用习惯。而Jax、MindSpore则在定位上更加底层,Jax直接明言自身为数值计算框架,MindSpore则定位为AI+科学计算融合计算框架,因此函数式自动微分设计更符合框架定位。
由于两种方案的差异,也造成了梯度累加实现的差异,下面分别以Pytorch和MindSpore为例,讲一下梯度累加的实现。
Pytorch实现
# batch accumulation parameter
accum_iter = 4
# loop through enumaretad batches
for batch_idx, (inputs, labels) in enumerate(data_loader):
# forward pass
preds = model(inputs)
loss = criterion(preds, labels)
# scale the loss to the mean of the accumulated batch size
loss = loss / accum_iter
# backward pass
loss.backward()
# weights update
if ((batch_idx + 1) % accum_iter == 0) or (batch_idx + 1 == len(data_loader)):
optimizer.step()
optimizer.zero_grad()由于Pytorch本身在求完梯度后会自动挂载到Tensor.grad属性上,而在没有手动清空(即optimizer.zero_grad())的情况下,每个step训练求得的梯度会自动累加,因此只需要控制梯度清零和参数更新的间隔步数即可。
这里着重强调一个位置,loss = loss / accum_iter这一行操作的含义及实现。稍微翻看了一下搜索引擎排名靠前的几篇,发现误导不少。
首先是注释里说明的含义,不知出处但是几乎所有人都备注一句normalize loss to account for batch accumulation,中文译作loss正则化。这个地方显然是越写越偏了。
实际上这里就是做了一次求mean的操作。原因是直接累加的accum_iter次梯度值作为一次参数更新的梯度,是将梯度值放大了accum_iter倍,而Pytorch的参数更新是写在optimizer.step()方法内部,无法手动控制,因此只能根据链式法则,在loss处进行缩放,来达到缩放梯度的目的。与常规理解的正则化没有任何关系。
此外,还有一个谬误的写法:
loss = criterion(outputs, labels)
loss += loss / accumulation_steps
loss.backward()loss通常不会这样累加,一般会单独维护一个 total_loss, 且累加之后再做loss.backward(),微分结果也是错误的,由左式正确的偏导,变为loss累加和对w求偏导:
MindSpore实现
回过头来看函数式自动微分,由于暴露接口更加底层,所以是直接求导返回梯度的,下面是一个简单的示例:
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())
loss, grads = grad_fn(x, y)
print(grads)因为没有直接挂载到Tensor属性的操作,因此需要单独维护一份和训练参数相同大小的参数进行累加的计算。下面直接来看代码:
import mindspore as ms
from mindspore import Tensor, Parameter, ops
@ms.jit_class
class Accumulator():
def __init__(self, optimizer, accumulate_step):
self.optimizer = optimizer
self.inner_grads = optimizer.parameters.clone(prefix="accumulate_", init='zeros')
self.zeros = optimizer.parameters.clone(prefix="zeros_", init='zeros')
self.counter = Parameter(Tensor(1, ms.int32), 'counter_')
assert accumulate_step > 0
self.accumulate_step = accumulate_step
self.map = ops.HyperMap()
def __call__(self, grads):
# 将单步获得的梯度累加至Accumulator的inner_grads
self.map(ops.partial(ops.assign_add), self.inner_grads, grads)
if self.counter % self.accumulate_step == 0:
# 如果达到累积步数,进行参数优化更新
self.optimizer(self.inner_grads)
# 完成参数优化更新后,清零inner_grads
self.map(ops.partial(ops.assign), self.inner_grads, self.zeros)
# 计算步数加一
ops.assign_add(self.counter, Tensor(1, ms.int32))
return True如上代码实现了一个单独的Accumulator,其中self.inner_grads就是单独存储累加梯度的参数,直接clone一份训练参数即可。此外,还需要单独维护一个计数器,用来保证间隔accumulate_step 进行一次参数更新。
在__call__函数里实现的步骤和Pytorch的实现无异,都是持续累加,达到累加步数后先更新参数,后清零已有的梯度。由于单独维护了一个Accumulator,这里将optimizer作为入参统一放进了Accumulator进行计算,完整的训练过程如下:
accumulate_step = 2
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), 1e-2)
accumulator = Accumulator(optimizer, accumulate_step)
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
# loss除以累加步数accumulate_step
return loss / accumulate_step
grad_fn = value_and_grad(forward_fn, None, model.trainable_params())
@ms.jit
def train_step(data, label):
loss, grads = grad_fn(data, label)
loss = ops.depend(loss, accumulator(grads))
return loss需要注意的是,由于函数式自动微分接口更底层,因此对于梯度的处理可以更加灵活,我们可以取消forward_fn中做的mean操作,而在Accumulator中将self.optimizer(self.inner_grads) 改为self.optimizer(self.map(ops.div, self.inner_grads, self.accumulate_step))可以达到同样的效果。
此外,Optimizer是否需要和 Accumulator分开执行,让Accumulator只纯粹地负责累加和清零操作,都可以根据使用习惯进行任意组装。这是低阶接口的灵活性优势,但相应的,相较于Pytorch将大部分操作封装后不需感知,还是增加了些许复杂度,不过对于学习原理还是更合适。
小结
梯度累加是个很常规的trick了,也是没想到能搜到的居然有那么多错。2023年应该会写一批文章,敬请期待。















 3044
3044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









