







Courese2-第二周:优化算法
Mini-Batch
Batch梯度下降法:同时处理整个训练集。
Mini-batch梯度下降法:每次同时处理的单个的mini-batch X(t)和Y(t),而不是同时处理全部的X和Y的训练集。
随机梯度下降法:每个样本都是独立的mini-batch。
缺点:
- Batch梯度下降法:一次性处理整个训练集,当训练数量巨大时,单次迭代耗时太长。
- 随机梯度下降法:丢失了所有向量化带来的加速,一次性只能处理一个训练样本,效率低下。
所以选择mini-batch:一方面得到大量的向量化,另一方面不需要等待整个训练集被处理完就可以开始进行后续工作。
指数加权移动平均数(Exponentially weighted averages)
计算趋势的话,如温度的局部平均值,或者说移动平均值。
关键方程: v t = β v t − 1 + ( 1 − β ) θ t v_t = βv_{t-1}+(1-β)θ_t vt=βvt−1+(1−β)θt,β∈[0, 1]
其中,
V
t
表
示
第
t
天
的
移
动
平
均
值
\quad V_t表示第t天的移动平均值
Vt表示第t天的移动平均值。
V
t
−
1
表
示
第
t
−
1
天
的
移
动
平
均
值
\quad \qquad V_{t-1}表示第t-1天的移动平均值
Vt−1表示第t−1天的移动平均值。
θ
t
表
示
第
t
天
的
实
际
观
察
值
\quad \qquad θ_t表示第t天的实际观察值
θt表示第t天的实际观察值。
计算时,可视 v t v_t vt大概是 1 1 − β \frac{1}{1-β} 1−β1的每日温度,如β=0.9,这是十天的平均值。
当高值的β:曲线要平坦一些,因为多平均了几天的温度,所以曲线波动更小,更加平坦。缺点:曲线进一步右移,指数加权平均公式在温度变化时,适应地更缓慢一些,会出现一定的延迟。
当低值的β:由于平均的数据太少,所以得到的曲线有更多的噪声,可能出现异常值,但这个曲线能够更快适应温度变化。
Question:到底需要平均多少天的温度?
Answer:我们平均了大约 1 1 − β \frac{1}{1-β} 1−β1天的温度。
执行过程:
V_theta = 0
Repeat{
Get Next theta_t
V_theta := β*V_theta + (1 - β)* theta_t
}指数加权平均数公式的好处之一:它占用极少的内存,电脑内存中只占用一行数字而已。其效率,基本上只占用一行代码。
指数加权平均的偏差修正(Bias correction in exponentially weighted averages)
偏差修正:让平均数运算更加准备。
v t = β v t − 1 + ( 1 − β ) θ t v_t = βv_{t-1}+(1-β)θ_t vt=βvt−1+(1−β)θt,β∈[0, 1]
使用上述方程进行运算时,V0 = 0,计算V1、V2时,不能很好地估测这一年前两天的温度。通常会比正确值低很多,为了让估测变得更好。特别在估测初期,也就是不用 V t V_t Vt,而是用 V t 1 − β t \frac{V_t}{1-β^{t}} 1−βtVt,其中t就是现在的天数。随着t增加, β t β^t βt接近于0,所以当t很大的时候,偏差修正几乎没有作用。
e g : 当 t = 2 , 1 − β t = 1 − 0.9 8 2 = 0.0396 eg:当t = 2,1 - β^t = 1 - 0.98^2 = 0.0396 eg:当t=2,1−βt=1−0.982=0.0396,因此对第二天温度的估测变成了 V 2 0.0396 = 0.0196 θ 1 + 0.02 θ 2 0.0396 \frac{V_2}{0.0396} = \frac{0.0196\theta_1+0.02\theta_2}{0.0396} 0.0396V2=0.03960.0196θ1+0.02θ2,即 θ 1 和 θ 2 \theta_1和\theta_2 θ1和θ2的加权平均数,并去除了偏差。
动量梯度下降法(Gradient descent with Momentum)
基本的想法:计算梯度的指数加权平均数,并利用该梯度更新你的权重。
Gradient descent example:
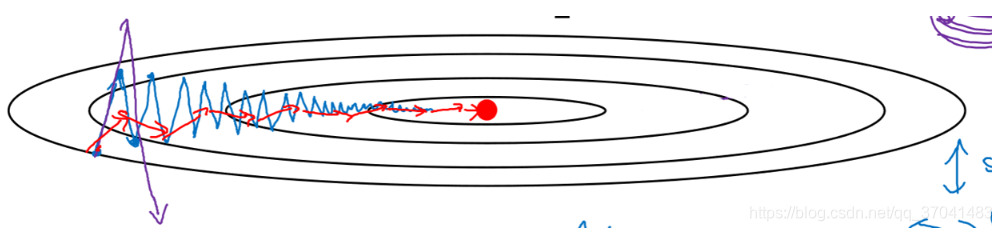
开始梯度下降算法(蓝色线),会发现其慢慢摆动到最小值,这种上下波动减慢了梯度下降法的速度。但你又无法使用更大的学习率,因为如果使用较大的学习率(紫色线),结果可能会偏离函数的范围,为了避免摆动过大,要用一个较小的学习率。
所以在纵轴上,希望学习慢一点,因为不想要这些摆动,但在横轴上,希望加快学习,希望快速从左移向右,移向最小值即红点。所以使用动量梯度下降法。
在每次迭代中,需要计算微分dW, db。我们通过计算 V d w = β V d w + ( 1 − β ) d W V_{dw} = βV_{dw} + (1 - β)dW Vdw=βVdw+(1−β)dW,获得dW的移动平均数,同理得到 V d b V_{db} Vdb,然后重新赋值权重, W : = W − α V d w W:=W-αV_{dw} W:=W−αVdw,同理 b : = b − α V d b b:=b-αV_{db} b:=b−αVdb,这样就可以减缓梯度下降的幅度。
Momentum算法在此:
Vdw = 0, Vdb = 0 # 零向量
On iteration t:
Compute dW, db on the current mini-batch
Vdw = β * Vdw + (1 - β) * dW
Vdb = β * Vdb + (1 - β) * db
W := W - α * Vdw
b := b - α * Vdb
Hyperparameters:α、β β常用值 = 0.9
学习率α、参数β控制着指数加权平均数可以想象Momentum项(Vdw、Vdb)相当于速度,你拿了一个球,dW, db即微分项给了这个球一个加速度,此时球正向山下滚,球因为加速度越滚越快,又因为β稍小于1,相当于表现出了一些摩擦力,所以球不会无限加速下去。
你会发现这些纵轴上的摆动平均值接近于零,所以在纵轴方向,你希望放慢一点,平均过程中,正负数相互抵消,所以平均值接近于零。
在横轴方向,所有的微分都指向横轴方向,因此横轴方向的平均值仍然较大。
用算法几次迭代后,会发现动量梯度下降法,最终纵轴方向的摆动变小了,横轴方向运动更快。
RMSprop(root mean square prop)

假设纵轴代表参数b,横轴代表参数W,可能有
W
1
,
W
2
W_1, W_2
W1,W2或者其他参数,为便于理解,被称为b和W。
RMSprop算法可以实现:减缓b方向的学习,即纵轴方向,同时加快,至少不是减缓横轴方向的学习。
RMSprop算法在此:
On iteration t:
Compute dW, db on current Mini-batch
S d w = β S d w + ( 1 − β ) ( d W ) 2 S_{dw} = βS_{dw} + (1 - β)(dW)^2 Sdw=βSdw+(1−β)(dW)2
S d b = β S d b + ( 1 − β ) ( d b ) 2 S_{db} = βS_{db} + (1 - β)(db)^2 Sdb=βSdb+(1−β)(db)2
W : = W − α d W S d w W := W - α\frac{dW}{\sqrt{S_{dw}}} W:=W−αSdwdW
b : = b − α d b S d w b := b - α\frac{db}{\sqrt{S_{dw}}} b:=b−αSdwdb
这里一直把纵轴和横轴方向分别称为b和W,但实际中,你会处于参数的高维度空间,所以需要消除摆动的垂直维度,你需要消除摆动,实际上是参数W1,W2等的合计,水平维度可能W3,W4等。实际上dW是一个高维度的参数向量,db也是一个高维度的参数向量。
Adam优化算法(Adam optimization algorithm)
Adam优化算法基本上就是将Momentum和RMSprop结合在一起。
思路:
1.首先初始化 V d w = 0 , S d w = 0 , V a b = 0 , S a b = 0 V_{dw}=0, S_{dw}=0, V_{ab}=0,S_{ab}=0 Vdw=0,Sdw=0,Vab=0,Sab=0
2.在第t次迭代中,计算微分,用当前的mini-batch计算dW, db,一般会用mini-batch梯度下降法。
3.接下来,计算Momentum指数加权平均数。 V d w = β 1 V d w + ( 1 − β 1 ) d W V_{dw} = \beta_1V_{dw}+(1-\beta_1)dW Vdw=β1Vdw+(1−β1)dW, V d b = β 1 V d b + ( 1 − β 1 ) d b V_{db} = \beta_1V_{db}+(1-\beta_1)db Vdb=β1Vdb+(1−β1)db
4.接着用RMSprop进行更新。 S d w = β 2 S d w + ( 1 − β 2 ) ( d W ) 2 S_{dw} = \beta_2S_{dw}+(1-\beta_2)(dW)^2 Sdw=β2Sdw+(1−β2)(dW)2, S d b = β 2 S d b + ( 1 − β 2 ) ( d b ) 2 S_{db} = \beta_2S_{db}+(1-\beta_2)(db)^2 Sdb=β2Sdb+(1−β2)(db)2
5.一般使用Adam算法时,要计算偏差修正。 V d W c o r r e c t e d = V d W 1 − β 1 t V^{corrected}_{dW} = \frac{V_{dW}}{1-\beta^t_1} VdWcorrected=1−β1tVdW, V d b c o r r e c t e d = V d b 1 − β 1 t V^{corrected}_{db} = \frac{V_{db}}{1-\beta^t_1} Vdbcorrected=1−β1tVdb
S也要使用偏差修正, S d W c o r r e c t e d = S d W 1 − β 2 t S^{corrected}_{dW} = \frac{S_{dW}}{1-\beta^t_2} SdWcorrected=1−β2tSdW, S d b c o r r e c t e d = S d b 1 − β 2 t S^{corrected}_{db} = \frac{S_{db}}{1-\beta^t_2} Sdbcorrected=1−β2tSdb
6.最后更新权重。(如果只是使用Momentum,用 V d w V_{dw} Vdw或修正后的 V d w V_{dw} Vdw,但现在加入了RMSprop的部分,所以要除以修正后 S d w 的 平 方 根 加 上 ε S_{dw}的平方根加上ε Sdw的平方根加上ε) W : = W − α V d W c o r r e c t e d S d W c o r r e c t e d + ε W:=W - \frac{\alpha V^{corrected}_{dW}}{\sqrt{S^{corrected}_{dW}} + ε} W:=W−SdWcorrected+εαVdWcorrected, b : = b − α V d b c o r r e c t e d S d b c o r r e c t e d + ε b:=b - \frac{\alpha V^{corrected}_{db}}{\sqrt{S^{corrected}_{db}} + ε} b:=b−Sdbcorrected+εαVdbcorrected
Adam optimization algorithm:
首先初始化: V d w = 0 , S d w = 0 , V a b = 0 , S a b = 0 V_{dw}=0, S_{dw}=0, V_{ab}=0,S_{ab}=0 Vdw=0,Sdw=0,Vab=0,Sab=0
On iterator t:
Compute dW, db, using mini-batch
V d w = β 1 V d w + ( 1 − β 1 ) d W V_{dw} = \beta_1V_{dw}+(1-\beta_1)dW Vdw=β1Vdw+(1−β1)dW, V d b = β 1 V d b + ( 1 − β 1 ) d b V_{db} = \beta_1V_{db}+(1-\beta_1)db Vdb=β1Vdb+(1−β1)db
S d w = β 2 S d w + ( 1 − β 2 ) ( d W ) 2 S_{dw} = \beta_2S_{dw}+(1-\beta_2)(dW)^2 Sdw=β2Sdw+(1−β2)(dW)2, S d b = β 2 S d b + ( 1 − β 2 ) ( d b ) 2 S_{db} = \beta_2S_{db}+(1-\beta_2)(db)^2 Sdb=β2Sdb+(1−β2)(db)2
V d W c o r r e c t e d = V d W 1 − β 1 t V^{corrected}_{dW} = \frac{V_{dW}}{1-\beta^t_1} VdWcorrected=1−β1tVdW, V d b c o r r e c t e d = V d b 1 − β 1 t V^{corrected}_{db} = \frac{V_{db}}{1-\beta^t_1} Vdbcorrected=1−β1tVdb
S d W c o r r e c t e d = S d W 1 − β 2 t S^{corrected}_{dW} = \frac{S_{dW}}{1-\beta^t_2} SdWcorrected=1−β2tSdW, S d b c o r r e c t e d = S d b 1 − β 2 t S^{corrected}_{db} = \frac{S_{db}}{1-\beta^t_2} Sdbcorrected=1−β2tSdb
W : = W − α V d W c o r r e c t e d S d W c o r r e c t e d + ε W:=W - \frac{\alpha V^{corrected}_{dW}}{\sqrt{S^{corrected}_{dW}} + ε} W:=W−SdWcorrected+εαVdWcorrected, b : = b − α V d b c o r r e c t e d S d b c o r r e c t e d + ε b:=b - \frac{\alpha V^{corrected}_{db}}{\sqrt{S^{corrected}_{db}} + ε} b:=b−Sdbcorrected+εαVdbcorrected
Hyperparameters choice:
在使用Adam时,一般使用缺省值即可,如下:
α : \alpha: α: need to be tune
β 1 : 0.9 \beta_1: 0.9 β1:0.9
β 2 : 0.999 \beta_2: 0.999 β2:0.999
ε : 1 0 − 8 \varepsilon: 10^{-8} ε:10−8
Question:为什么叫做Adam算法?
Answer:Adam代表Adaptive Moment Estimation(自适应矩估计), β 1 \beta_1 β1用于计算微分(dW),叫做第一矩, β 2 \beta_2 β2用来计算平方数的指数加权平均数 ( d W ) 2 (dW)^2 (dW)2,叫做第二矩。
学习率衰减
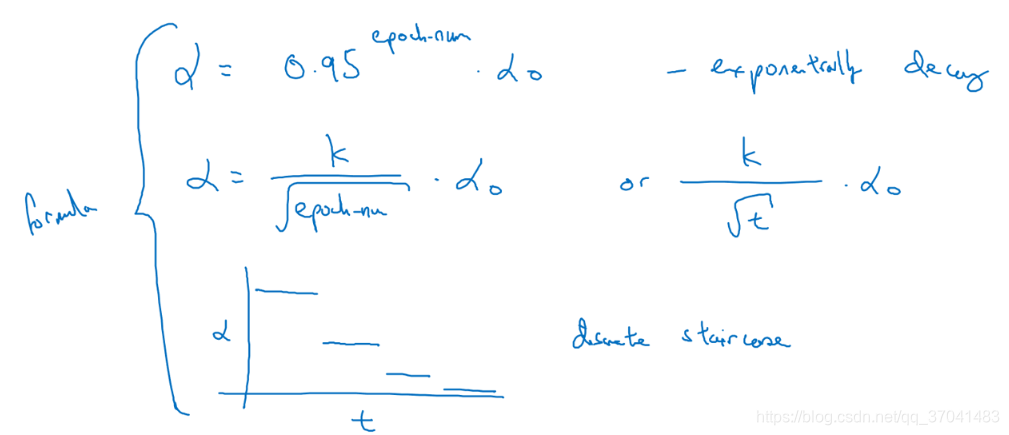
Question: 为什么要计算学习率衰减?
Answer: 若使用mini-batch梯度下降法,在迭代过程中会有噪音(蓝色),下降朝向最小值,但不会精确地收敛,算法最后在附近摆动,并不会真正收敛。所以慢慢减小学习率α地话,在学习初期,你能承受较大的步伐,但当开始收敛的时候,小一些的学习率能让你步伐小一些,所以最后你的曲线(绿色)会在最小值附近的一小块区域摆动,而不是在训练过程中,大幅度在最小值附近摆动。
mini-batch,第一次遍历训练集叫做第一代,第二次叫做第二代,以此类推。
学习率 α = 1 1 + d e c a y r a t e ∗ e p o c h n u m a 0 α = \frac{1}{1 + decayrate * epochnum}a_0 α=1+decayrate∗epochnum1a0,其中decay-rate为衰减率,epoch-num为代数, a 0 a_0 a0为初始学习率。
衰减率是另一个需要调整的超参数。
Other learning rate decay methods
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yeMvHK77-1577681758504)(attachment:image.png)]](https://img-blog.csdnimg.cn/20191230125650567.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3MDQxNDgz,size_16,color_FFFFFF,t_70)
局部最优的问题
事实上,如果要创建一个神经网络,通常梯度为零的点并不是图中的局部最优点(左图),实际上成本函数的零梯度点,通常是鞍点(右图)。
(attachment:image.png)]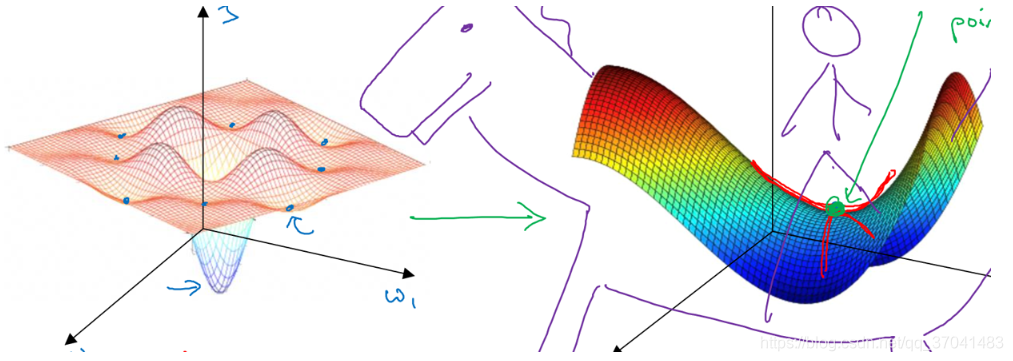
局部最优不是问题,问题是:你会花很长时间慢慢抵达平稳段的这个点。因为平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于0,若你在此处,梯度会从曲面从上向下下降,因为梯度等于或接近0,曲面很平坦,所以会花很长时间抵达平稳段这个点,又因为左边或右边的随机扰动,算法能够走出这个平稳段。
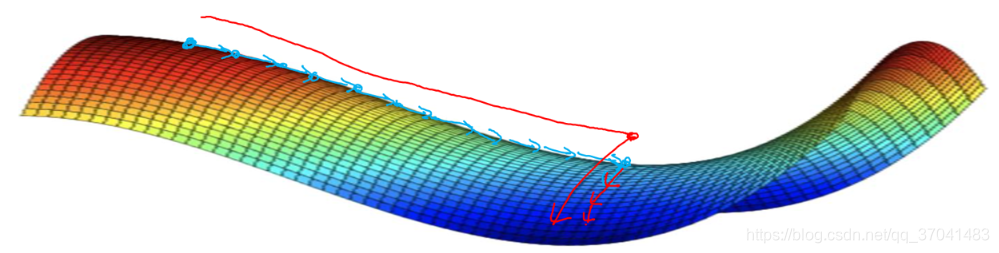
要点
- 在训练较大的神经网络,存在大佬参数,且成本函数J被定义为在较高的维度空间时,不太可能困在极差的局部最优中。
- 平稳段使得学习十分缓慢。在这些情况下,需要更成熟的优化算法,如Adam算法,加快速度,尽早走出平稳段。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









