






伙伴分配器(Buddy System)
我们知道,物理内存是以页框为单位进行管理的,假如我们不使用内存分配算法管理内存,考虑下面一个例子:我有一块256K的连续内存空间(共64页框),分配内存时要分配连续的内存:
1、申请32KB,申请64KB,申请64KB,还剩96 KB
2、我释放了第一个32KB,然后要申请128KB
3、其实内存够大,但是这128KB不连续,我就无法申请出来, 就只能使用额外内存。这样就造成了空间的浪费,也就是内存碎片的产生。

内核在频繁的请求和释放不同大小的一组连续页框,必然会导致在已经分配的块内分散了许多小块的空闲页框。由此带来的问题是,及时有足够的空闲页框可以满足请求,但是要分配一个大块的连续页框就无法满足。针对这个问题,提出了伙伴算法。
系统内核初始完毕后,使用页分配器管理物理页,使用的页分配器是伙伴分配器。伙伴系统的用途主要是尽可能减少外部碎片,同时允许快速分配与回收物理页面。伙伴分配器是以页为单位管理和分配内存。
伙伴算法的思想
先了解下面几个定义:
- 页块(page block):连续的物理页
- 阶(order):n阶页块指具有2^n个连续页
- 伙伴:满足以下条件的两个物理块称为伙伴:
- 两个块具大小相等
- 两个块的物理地连续
- 两个块必须是同一个大块中分离出来的
Linux把所有的空闲页框(4KB)分组为11个块链表,每个链表上的页框块大小是固定的。每一块链表分别包含1、2、4、8、16、32、64、128、256、512 和 1024 个连续的页框:
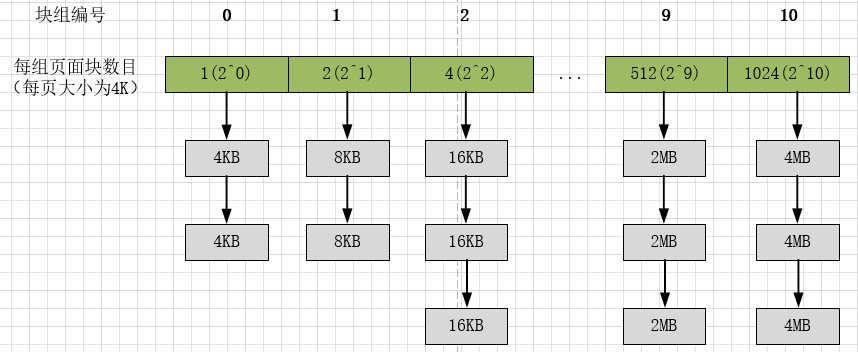
1、下面以一个例子,讲述伙伴算法申请内存的思想:
- 假设要申请1M连续空间 ,即4K * 256, 256 = 2^8,我们就可以定位到下标为8的位置,看是否有空闲的。有空闲则直接给他分配。
- 如果没有空闲,就去块大小为512个页框也就是2M的链表中找,这个2M链表是否有空闲。如果没空闲则继续向下找。
- 找到最后一个块大小是4M的链表,如果没有空闲则分配失败返回错误。如果有空闲,则将其中1M分配给程序。剩余2M和1M分别放到对应的链表中。
2、下面再以一个例子,讲述伙伴算法释放内存的思想:
前面申请内存的过程并没有体现伙伴这个词的含义,伙伴这个词是在释放内存的时候才体现出来的。
- 假设要释放一个1M =256 * 4K的连续空间,先检查所在链表中该位置是否有他的伙伴
- 如果不存在伙伴,则直接释放并将释放的块插入链表头
- 如果他所在链表中有伙伴存在,则将其从链表摘下,合并成一个大块,然后继续向后查找合并,直至不能合并或者已经合并至最大块2^10为止。
伙伴算法思想总结:在分配内存时,首先从空闲的内存中搜索不小于申请内存的最小内存块。如果这样的内存块存在,则将这块内存标记为“已用”,同时将该内存分配给应用程序。如果这样的内存不存在,则操作系统将寻找更大块的空闲内存,然后将这块内存平分成几部分,一部分返回给程序使用,另一部分作为空闲的内存块放到相应链表中。在释放内存时,首先将该内存回收,然后检查与该内存相邻的内存是否是同样大小并且同样处于空闲的状态,如果是,则将这两块内存合并,然后用相同的方式继续合并直到无法合并为止。
伙伴算法的优缺点
先通过一个例子,来说下伙伴算法的优缺点:
假设有一块1M的内存,我们使用伙伴算法来管理:

- 图b - 如果程序1想要申请一块45K大小的内存,则系统会查找空闲链表,将第一块64K的内存块分配给该程序(产生内部碎片为代价)
- 图c - 程序2申请一块68K大小的内存,系统会将128K内存分配给该程序
- 图d - 程序3要申请一块大小为35K的内存。系统将空闲的64K内存分配给该程序
- 图e - 程序4需要一块大小为90K的内存。当程序提出申请时,系统本该分配给程序D一块128K大小的内存,但此时内存中已经没有空闲的128K内存块了,于是根据伙伴算法的原理,系统会将256K大小的内存块平分,将其中一块分配给程序D,另一块作为空闲内存块保留,等待以后使用
- 图f - 程序3释放了它申请的64K内存。在内存释放的同时,系统还负责检查与之相邻并且同样大小的内存是否也空闲,由于此时程序1并没有释放它的内存,所以系统只会将程序3的64K内存回收
- 图g - 然后程序1也释放掉由它申请的64K内存,系统随机发现与之相邻且大小相同的一段内存块恰好也处于空闲状态,也就是伙伴内存。于是,将两者合并成128K内存
- 图h - 之后程序2释放掉它的128k,系统也将这块内存与相邻的128K内存合并成256K的空闲内存
- 图i - 最后程序4也释放掉它的内存,经过三次合并后,系统得到了一块1024K的完整内存
通过这个例子我们能发现:伙伴算法,就是将内存分成若干块,然后尽可能以最适合的方式满足程序内存需求的一种内存管理算法。它的优点就是能够避免外部碎片的产生,它的缺点是会产生内部碎片。
伙伴系统的内存组织
Linux将一个node抽象成一个pglist_data结构体,每个pglist_data下最多有6个zone,其中每个zone代表一种类型的内存。内核使用伙伴算法管理每个zone中的物理page。它们的关系如下图所示:
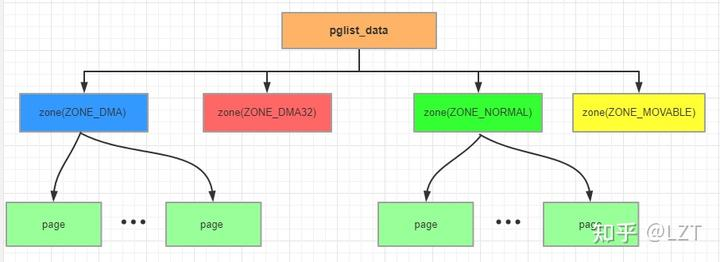
因此,伙伴算法的核心数据结构包含以下2个部分:
先看下跟伙伴算法相关的下面几个数据结构:
struct zone {
……
struct free_area free_area[MAX_ORDER]; // MAX_ORDER = 11
unsigned long watermark[NR_WMARK];//水位值,WMARK_MIN/WMARK_LOV/WMARK_HIGH
……
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES]; //内存块链表
unsigned long nr_free;//该组类别块空闲的个数
};
struct list_head {
struct list_head *next, *prev;
};前面说到伙伴算法把所有的空闲页框分组为11块链表,内存分配的最大长度便是2^10页面。上面两个结构体向我们揭示了伙伴算法管理结构。zone 结构中的 free_area 数组,大小为11,分别存放着这11个组,free_area 结构体里面又标注了该组别空闲内存块的情况。

将所有空闲页框分为11个组,然后同等大小的串成一个链表对应到free_area数组中。这样能很好的管理这些不同大小页面的块。
区域水线简介
linux物理内存中的每个zone都有自己独立的3个档位的区域水线(watermark):
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};- 最低水线(WMARK_MIN):如果内存区域的空闲页数小于最低水线,说明该内存区域的内存严重不足
- 低水线(WMARK_LOW):空闲页数小数低水线,说明该内存区域的内存轻微不足。默认情况下,该值为WMARK_MIN的125%
- 高水线(WMARK_HIGH):如果内存区域的空闲页数大于高水线,说明该内存区域水线充足。默认情况下,该值为WMARK_MAX的150%
slab分配器
通过前面介绍我们知道,伙伴分配算法是以页为单位管理和分配内存。但在内核中的需求却以字节为单位,。假如我们需要动态申请一个内核结构体(占 20 字节),若仍然分配一页内存,这将严重浪费内存。因此,提出了slab分配器。
slab分配器的思想
它的基本思想是:将内核中经常使用的对象放到高速缓存中,并且由系统保持为初始的可利用状态。每当要申请这样一个对象时,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。(比如进程描述符,内核中会频繁对此数据进行申请和释放。当一个新进程创建时,内核会直接从slab分 配器的高速缓存中获取一个已经初始化了的对象;当进程结束时,该结构所占的页框并不被释放,而是重新返回slab分配器中。如果没有基于对象的slab分 配器,内核将花费更多的时间去分配、初始化以及释放一个对象。)
注意:
1、所谓的对象可看作是内核中的数据结构。
2、高速缓存实际上指的是内存中的区域,而不是指硬件高速缓存。
3、每个 slab是由一个或多个连续的页框组成。每个页框中包含若干个对象,既有已经分配的对象,也包含空闲的对象。
slab分配器有以下三个基本目标:
- 减少伙伴算法在分配小块连续内存时所产生的内部碎片;
- 将频繁使用的对象缓存起来,减少分配、初始化和释放对象的时间开销。
- 通过着色技术调整对象以更好的使用硬件高速缓存;
slab与伙伴系统的关系
互补的
伙伴算法解决外部碎片,slab算法解决内部碎片,但事实上,slab在新建cache时同样需要用到伙伴系统来为之分配页面,而在释放cache时也需要伙伴系统来回收这个页面。也就是说,slab事实上是依赖伙伴系统的。
实际还是伙伴系统分配物理页
从slab的分配可以知道,其实所有的内存最终还是要伙伴系统来分配,这里就可以知道,这些内存都是连续的物理页。
slab作为内核缓存对象
在某些情况下内核模块可能需要频繁的分配和释放相同的内存对象,这时候slab可以作为内核对象的缓存:当对象被释放时,slab分配器并不会把对象占用的物理空间还给伙伴系统。这样的好处是当内核模块需要再次分配内存对象时,不需要那么麻烦的向伙伴系统申请,而是可以直接在slab链表中分配一个合适的对象。
slab分配器的结构
slab分配器为每种对象分配一个高速缓存,这个缓存可以看做是存储同类型对象的一块内存。每个高速缓存所占的内存区又被划分多个slab,每个 slab是由一个或多个连续的页框组成。每个页框中包含若干个对象,既有已经分配的对象,也包含空闲的对象。slab分配器的大致组成图如下:
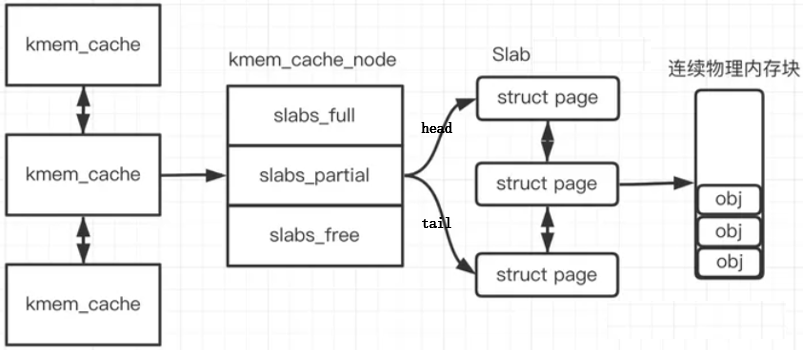
每个高速缓存通过 kmem_cache(slab管理器)来描述,这个结构中包含了对当前高速缓存各种属性信息的描述。所有的高速缓存通过双链表组织在一起,形成高速缓存链表。每个kmem_cache 结构的定义如下:
// include/linux/slab_def.h
struct kmem_cache {
/* 2) touched by every alloc & free from the backend */
slab_flags_t flags; /* constant flags */
unsigned int num; /* 每个 slab 中的 objs 数量 */
/* 3) cache_grow/shrink */
/* 每个 slab 的 order */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size; //每个object的大小。
int align;
struct kmem_cache_node *node[MAX_NUMNODES];
};kmem_cache 的 kmem_cache_node 成员记录了该 kmem_cache 下的所有 slabs 列表。每个 kmem_cache_node 节点在内存中维护称为 slab 的连续页块(一个slab包含多个page),这些页面被切成小块,用于缓存数据结构和对象。kmem_cache_node 结构的定义如下:
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
//保存所有使用了部分内存的slab(物理页)
struct list_head slabs_partial;
//保存所有使用了全部内存的slab(物理页)
struct list_head slabs_full;
//保存所有未使用的slab(物理页)
struct list_head slabs_free;
unsigned long total_slabs; // 该node上所有slab数量
unsigned long free_slabs; // 该node上空闲的slab数量
unsigned long free_objects; // 该node上空闲的object数
...
#endif
};linux内核使用 struct page 来描述一个slab,如果一个半满的slab被分配了对象后变满了,就要从 slabs_partial 链表中被删除,同时插入到 slabs_full 链表中去。一个 slab 包含页的个数为2^gfp_order。下面是 struct page 的定义:
struct page {
...
union {
...
struct { /* slab, slob and slub */
union {
//跟踪此页框属于哪个slab链表
struct list_head slab_list;
...
};
//指向该slab的管理器
struct kmem_cache *slab_cache; /* not slob */
//空闲的object第一个节点
void *freelist; /* first free object */
union {
// 指向页框中空闲对象链表
void *s_mem; /* slab: first object */
};
};
...
};
};slab分配器有关的结构体之间更加详细的关系图如下所示:
 slab分配器相关的重要函数
slab分配器相关的重要函数
//创建slab描述符,kmem_cache此时并没有真正分配内存
struct kmem_cache *kmem_cache_create(const char *, size_t, size_t,
unsigned long, void (*)(void *));
//分配slab缓存对象
void *kmem_cache_alloc(struct kmem_cache *, gfp_t flags);
//释放slab缓存对象
void kmem_cache_free(struct kmem_cache *, void *);
//销毁slab描述符
void kmem_cache_destroy(struct kmem_cache *);slob
slob可以简单理解成slab的缩小版,专门用于内存较小的设备,例如某些嵌入式设备。
slub
slub是slab的增强版,它的出现是为了解决slab存在的一些问题。
不连续页分配器
伙伴关系把内存块按大小分组管理,一定程度上减轻了外部碎片的危害,因为页框分配不在盲目,而是按照大小依次有序进行,不过伙伴关系只是减轻了外部碎片,但并未彻底消除。slab分配器使得一个页面内包含的众多小块内存可独立被分配使用,避免了内部碎片,节约了空闲内存。
所以避免外部碎片的最终思路还是落到了如何利用不连续的内存块组合成“看起来很大的内存块”。--这里的情况很类似于用户空间分配虚拟内存,内存逻辑上连续,其实映射到并不一定连续的物理内存上。Linux内核借用了这个技术,允许内核程序在内核地址空间中分配虚拟地址,同样也利用页表(内核页表)将虚拟地址映射到分散的内存页上。以此完美地解决了内核内存使用中的外部碎片问题。
内核提供vmalloc函数分配内核虚拟内存,该函数不同于kmalloc,它可以分配较kmalloc大得多的内存空间(可远大于128K,但必须是页大小的倍数),但相比kmalloc来说,vmalloc需要对内核虚拟地址进行重映射,必须更新内核页表,因此分配效率上要低一些(用空间换时间)。
vmalloc 分配的地址则限于 vmalloc_start 与 vmalloc_end 之间。每一块 vmalloc 分配的内核虚拟内存都对应一个 vm_struct 结构体(可别和 vm_area_struct 搞混,那可是进程虚拟内存区域的结构),不同的内核虚拟地址被4k大小的空闲区间隔,以防止越界)。与进程虚拟地址的特性一样,内核虚拟地址与物理内存没有简单的位移关系,必须通过内核页表才可转换为物理地址或物理页。这样才能把不连续的页利用起来。
编程接口
不连续页分配器提供了以下编程接口:
//分配不连续的物理页并且把物理页映射到连续的虚拟地址空间
void *vmalloc(unsigned long size);
//释放vmalloc分配的物理页和虚拟地址空间
void vfree(const void *addr);
//把已经分配的不连续物理页映射到连续的虚拟地址空间
void *vmap(struct page **pages, unsigned int count, unsigned long flags, pgprot_t prot);
//释放使用vmap分配的虚拟地址空间
void vunmap(const void *addr);
注:函数vmap和函数vmalloc的区别仅仅在于不需要分配物理页内核还提供了以下函数:
//先尝试使用kmalloc分配内存块,如果失败,那么使用vmalloc函数分配不连续的物理页
void *kvmalloc(size_t size, gfp_t flags);
//如果内存块是使用vmalloc分配的,那么使用vfree释放,否则使用kfree释放
void kvfree(const void *addr);数据结构
不连续页分配器的数据结构如下所示:
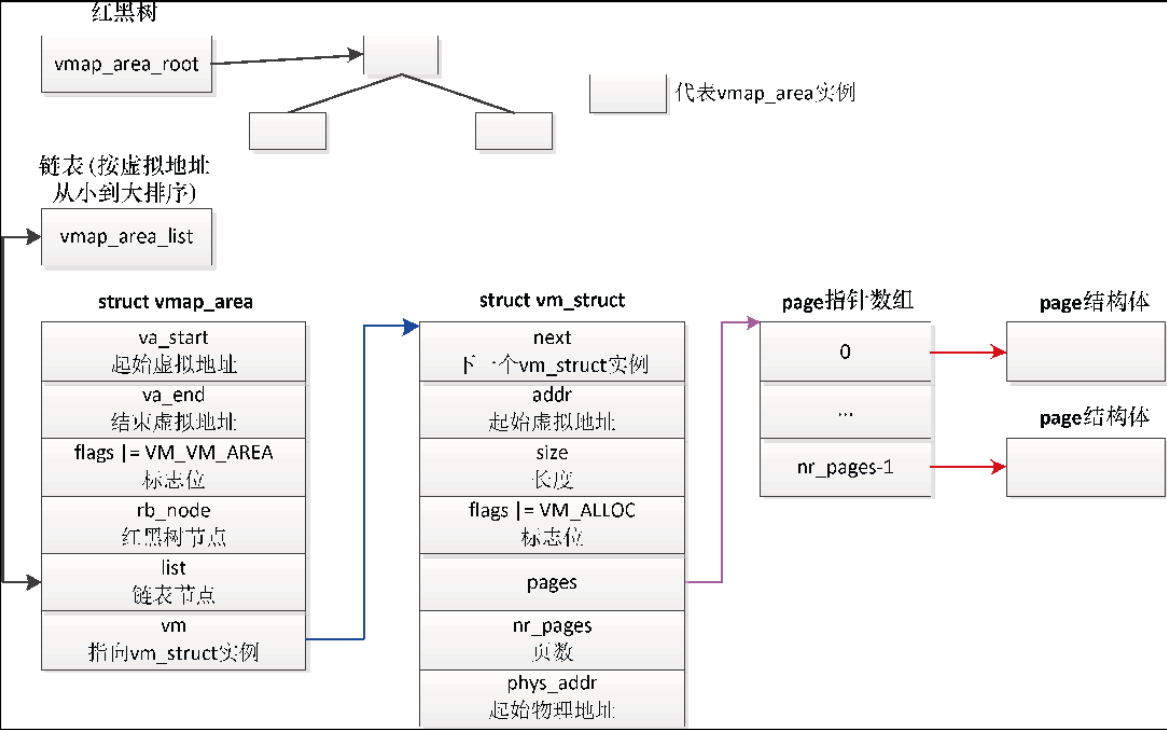
- 每个虚拟内存区域对应一个 vmap_area 实例
- 成员 va_start 是虚拟内存区域的起始虚拟地址,成员 va_end 是虚拟内存区域的结束虚拟地址。
- 成员 flags 是标志位,如果设置了标志位 VM_VM_AREA,表示成员 vm 指向一个 vm_struct实例,即 vmap_area 实例关联一个 vm_strut 实例。
- 成员 rb_node 是红黑树节点,用来把 vmap_area 实例加入根节点是 vmap_area_root 的红黑树中,借助红黑树可以根据虚拟地址快速找到 vmap_area 实例。
- 成员 list 是虚拟内存区域链表节点,用来把 vmap_area 实例加入头节点是 vmap_area_list 的链表中,这条链表按虚拟地址从小到大排序。
- 每个 vmap_area 实例关联一个 vm_struct 实例
- 成员 addr 是起始虚拟地址,成员 size 是长度
- 成员flags是标志位,如果设置了标志位VM_ALLOC,表示虚拟内存区域是使用函数vmalloc分配的
- 成员 pages 指向 page指针数组,成员 nr_pages 是页数。page指针数组的每个元素指向一个物理页的page实例。
- 成员 next 指向下一个 vm_struct 实例,成员 phys_addr 是起始物理地址
vmalloc 函数
函数 vmalloc 分配的单位是页,如果请求分配的长度不是页的整数倍,那么把长度向上对齐到页的整数倍。
函数vmalloc的执行过程分为3步:
- 分配虚拟内存区域:
分配 vm_struct 实例和 vmap_area 实例;然后遍历已经存在的 vmap_area 实例,在两个相邻的虚拟内存区域之间找到一个足够大的空洞,如果找到了,把起始虚拟地址和结束虚拟地址保存在新的vmap_area 实例中,然后把新的 vmap_area 实例加入红黑树和链表;最后把新的 vmap_area 实例关联到 vm_struct 实例。
- 分配物理页:
vm_struct 实例的成员 nr_pages 存放页数n;分配page指针数组,数组的大小是n,vm_struct 实例的成员 pages 指向 page 指针数组;然后连续执行n次如下操作:从页分配器分配一个物理页,把物理页对应的page实例的地址存放在page指针数组中。
- 在内核的页表中把虚拟页映射到物理页:
内核的页表就是0号内核线程的页表。0号内核线程的进程描述符是全局变量 init_task,成员active_mm 指向全局变量 init_mm,init_mm 的成员 pgd 指向页全局目录 swapper_pg_dir。
总结
Linux 中常用内存分配函数:
用户空间
malloc/calloc/realloc/free:
特点:不保证物理连续。大小限制(堆申请)。单位为字节。
场景:calloc初始化为0,realloc改变内存大小。
mmap/munmap:
场景:将文件利用虚拟内存技术映射到内存当中。
brk/sbrk:
场景:虚拟内存到内存的映射。
内核空间
vmalloc/vfree:
特点:虚拟连续/物理不连续。大小限制(vmalloc区)单位为页(vmalloc区域)。
场景:可能睡眠,不能从中断上下文中调用,或其他不允许阻塞情况下调用。
slab(kmalloc/kcalloc/krealloc/kfree):
特点:物理连续。大小限制(64b-4mb)。单位为2^order字节(Normal区域)。
场景:大小有限,不如vmalloc/malloc大。
还有一个叫做kmem_cache_create(物理连续。64-4mb。字节大小需要对齐(Normal区域)。
场景:便于固定大小数据的频繁分配和释放,分配时从缓存池中获取地址,释放时也不一定真正释放内存,通过slab进行管理)。
伙伴系统:
特点:物理连续。4mb (1024页),单位为页(Normal区域)。
场景:配置定义最大页面数2^11,一次能分配到的最大页面数是1024,
参考文献:
一篇看懂!伙伴系统之伙伴系统概述--Linux内存管理 - 知乎 (zhihu.com)
Linux 内核 | 内存管理——slab 分配器 - 知乎 (zhihu.com)
Linux内存管理(七)伙伴系统分配器介绍 - 知乎 (zhihu.com)
伙伴算法原理简介_Charles Ray的博客-CSDN博客
Linux内存管理之slab 1:slab原理(+buddy伙伴系统)_slab buddy_Hani_97的博客-CSDN博客















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









