






 本文讲述了如何将下载的文件中的字节码转换为汇编指令,利用IDA工具在32位模式下对机器代码进行分析,通过反汇编过程解密数据,最终获取flag的过程。
本文讲述了如何将下载的文件中的字节码转换为汇编指令,利用IDA工具在32位模式下对机器代码进行分析,通过反汇编过程解密数据,最终获取flag的过程。
我们下载下来文件,看到的是这样的东西
 不知道是什么,百度搜了搜前面几个十六进制数,发现是字节码。那就好办了,我们需要做的就是把字节码还原为汇编指令。
不知道是什么,百度搜了搜前面几个十六进制数,发现是字节码。那就好办了,我们需要做的就是把字节码还原为汇编指令。
把所有十六进制码弄成一个数组(这个可以用高级语言的字符串处理),然后把所有十六进制码弄成一个二进制文件:
hex_data=[0x55,0x8b,0xec,0x81,0xec,0xa8,0x0,0x0,0x0,0xa1,0x0,0x40,0x41,0x0,0x33,0xc5,0x89,0x45,0xfc,0x68,0x9c,0x0,0x0,0x0,0x6a,0x0,0x8d,0x85,0x60,0xff,0xff,0xff,0x50,0xe8,0x7a,0xc,0x0,0x0,0x83,0xc4,0xc,0xc7,0x85,0x58,0xff,0xff,0xff,0x27,0x0,0x0,0x0,0xc7,0x85,0x5c,0xff,0xff,0xff,0x0,0x0,0x0,0x0,0xeb,0xf,0x8b,0x8d,0x5c,0xff,0xff,0xff,0x83,0xc1,0x1,0x89,0x8d,0x5c,0xff,0xff,0xff,0x83,0xbd,0x5c,0xff,0xff,0xff,0x27,0xf,0x8d,0xed,0x0,0x0,0x0,0x8b,0x95,0x5c,0xff,0xff,0xff,0x81,0xe2,0x3,0x0,0x0,0x80,0x79,0x5,0x4a,0x83,0xca,0xfc,0x42,0x85,0xd2,0x75,0x25,0x8b,0x85,0x5c,0xff,0xff,0xff,0x8b,0x8c,0x85,0x60,0xff,0xff,0xff,0x3,0x8d,0x5c,0xff,0xff,0xff,0x8b,0x95,0x5c,0xff,0xff,0xff,0x89,0x8c,0x95,0x60,0xff,0xff,0xff,0xe9,0xac,0x0,0x0,0x0,0x8b,0x85,0x5c,0xff,0xff,0xff,0x25,0x3,0x0,0x0,0x80,0x79,0x5,0x48,0x83,0xc8,0xfc,0x40,0x83,0xf8,0x1,0x75,0x22,0x8b,0x8d,0x5c,0xff,0xff,0xff,0x8b,0x94,0x8d,0x60,0xff,0xff,0xff,0x2b,0x95,0x5c,0xff,0xff,0xff,0x8b,0x85,0x5c,0xff,0xff,0xff,0x89,0x94,0x85,0x60,0xff,0xff,0xff,0xeb,0x73,0x8b,0x8d,0x5c,0xff,0xff,0xff,0x81,0xe1,0x3,0x0,0x0,0x80,0x79,0x5,0x49,0x83,0xc9,0xfc,0x41,0x83,0xf9,0x2,0x75,0x23,0x8b,0x95,0x5c,0xff,0xff,0xff,0x8b,0x84,0x95,0x60,0xff,0xff,0xff,0xf,0xaf,0x85,0x5c,0xff,0xff,0xff,0x8b,0x8d,0x5c,0xff,0xff,0xff,0x89,0x84,0x8d,0x60,0xff,0xff,0xff,0xeb,0x38,0x8b,0x95,0x5c,0xff,0xff,0xff,0x81,0xe2,0x3,0x0,0x0,0x80,0x79,0x5,0x4a,0x83,0xca,0xfc,0x42,0x83,0xfa,0x3,0x75,0x20,0x8b,0x85,0x5c,0xff,0xff,0xff,0x8b,0x8c,0x85,0x60,0xff,0xff,0xff,0x33,0x8d,0x5c,0xff,0xff,0xff,0x8b,0x95,0x5c,0xff,0xff,0xff,0x89,0x8c,0x95,0x60,0xff,0xff,0xff,0xe9,0xf7,0xfe,0xff,0xff,0x33,0xc0,0x8b,0x4d,0xfc,0x33,0xcd,0xe8,0x4,0x0,0x0,0x0,0x8b,0xe5,0x5d,0xc3]
machine_code = bytearray(hex_data)
with open('machine_code.bin', 'wb') as file:
file.write(machine_code)
然后把生成出来的.bin文件拖入IDA,我使用的是32模式(因为我尝试了只有32位模式成功了)。
对着00000000这个地址按p,然后ida就会从这里开始的区域分析为函数。
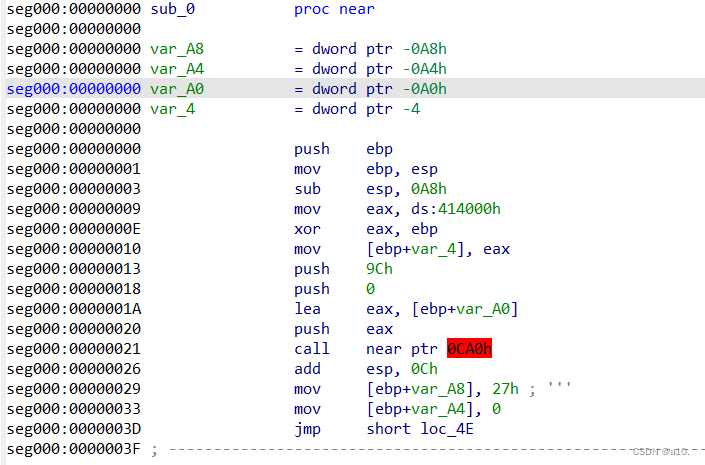 然后就可以按F5反汇编了。
然后就可以按F5反汇编了。
 这里就简单了,enc的数据就在这里解密,跟着反汇编的代码反着来就可以了,例如case 0我就-=i, case 1我就+=i,以此类推,就可以弄出flag了。
这里就简单了,enc的数据就在这里解密,跟着反汇编的代码反着来就可以了,例如case 0我就-=i, case 1我就+=i,以此类推,就可以弄出flag了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









