






在企业应用中,批处理很常见。但随着数据在互联网上变得越来越普遍,我们如何处理这些数据也变得很重要。有多种解决方案可用。Apache Storm或Apache Spark有助于以所需格式处理和转换数据。在这篇文章中,我们将更仔细地研究 Spring Batch。
什么是Spring Batch?
Spring Batch 是一个旨在促进批处理的轻量级框架。它允许开发人员创建批处理应用程序。反过来,这些批处理应用程序处理传入的数据并将其转换以供进一步使用。
使用Spring Batch的另一大优势是它允许对这些数据进行高性能处理。对于严重依赖数据的应用程序,数据即时可用至关重要。
Spring Batch 允许开发人员使用基于 POJO 的方法。在这种方法中,开发人员可以将批处理数据转换为数据模型,她可以进一步将其用于应用程序业务逻辑。
在这篇文章中,我将介绍一个示例,在该示例中,我们将批处理员工记录的数据密集型 CSV 文件,并转换、验证该数据以加载到我们的数据库中。
什么是批处理?
批处理是一种数据处理方式。它涉及使用所有数据、处理数据、转换数据,然后将其发送到另一个数据源。通常,这是通过自动化作业完成的。触发系统或用户触发作业,并且该作业处理作业定义。作业定义将是关于使用来自其源的数据。
批处理的主要优点是它可以处理大量数据。然而,这个操作可以是异步的。大多数应用程序独立于实时用户交互执行批处理。
接下来,我们将了解 Spring Batch 框架及其组成。
Spring Batch Framework
以下架构显示了 Spring Batch 框架的组件。
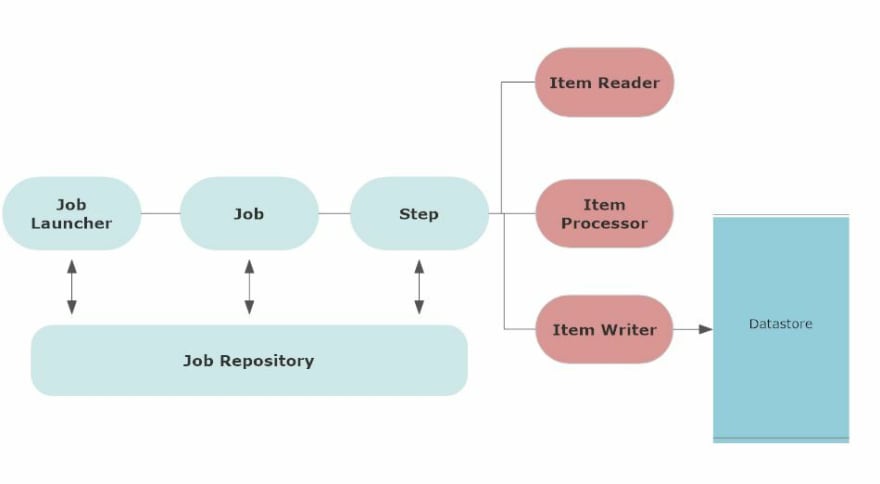
首先,批处理涉及一个作业。用户安排作业在特定时间或基于特定条件运行。这也可能涉及作业触发器。
Spring Batch 框架还包括
- 日志和追踪
- 交易管理
- job处理统计
- job重启
- 资源管理
通常,当您配置作业时,它会保存在作业存储库中。Job Repository 保存所有作业的元数据信息。触发器在预定时间启动这些作业。
A job launcher是在作业的预定时间到达时启动作业或运行作业的接口。
Job由作业参数定义。当作业开始时,作业实例会为该作业运行。作业实例的每次执行都有作业执行,它会跟踪作业的状态。一个作业可以有多个步骤。
Step是作业的一个独立阶段。一项工作可以由多个步骤组成。与作业类似,每个步骤都有执行步骤的步骤执行并跟踪步骤的状态。
每个步骤都有一个item reader基本上读取输入数据的步骤,一个item processor处理数据并转换它的步骤,以及一个item writer获取处理后的数据并将其输出的步骤。
现在,让我们在演示中查看所有这些组件。
一个简单的 Spring Batch 教程
作为演示的一部分,我们将通过 Spring Batch Framework 上传一个 csv 文件。因此,首先,创建 spring 项目并添加以下依赖项:
implementation 'org.springframework.boot:spring-boot-starter-batch'
这是我们项目的主要依赖。主应用程序也如下所示:
``` package com.betterjavacode.springbatchdemo;
import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication public class SpringbatchdemoApplication {
public static void main(String[] args)
{
SpringApplication.run(SpringbatchdemoApplication.class, args);
}} ```
创建 DTO 对象
我将通过 CSV 文件上传员工数据,因此我将为员工创建 DTO 对象,如下所示:
``` package com.betterjavacode.springbatchdemo.dtos;
import com.betterjavacode.springbatchdemo.models.Company; import com.betterjavacode.springbatchdemo.models.Employee; import com.betterjavacode.springbatchdemo.repositories.CompanyRepository; import org.springframework.beans.factory.annotation.Autowired;
import java.io.Serializable;
public class EmployeeDto implements Serializable { private static final long serialVersionUID = 710566148641281929L;
@Autowired
public CompanyRepository companyRepository;
private int employeeId;
private int companyId;
private String firstName;
private String lastName;
private String email;
private String jobTitle;
public EmployeeDto()
{
}
public EmployeeDto(int employeeId, String firstName, String lastName, String email,
String jobTitle, int companyId)
{
this.employeeId = employeeId;
this.firstName = firstName;
this.lastName = lastName;
this.email = email;
this.jobTitle = jobTitle;
this.companyId = companyId;
}
public Employee employeeDtoToEmployee()
{
Employee employee = new Employee();
employee.setEmployeeId(this.employeeId);
employee.setFirstName(this.firstName);
employee.setLastName(this.lastName);
employee.setEmail(this.email);
Company company = companyRepository.findById(this.companyId).get();
employee.setCompany(company);
employee.setJobTitle(this.jobTitle);
return employee;
}
public int getEmployeeId ()
{
return employeeId;
}
public void setEmployeeId (int employeeId)
{
this.employeeId = employeeId;
}
public int getCompanyId ()
{
return companyId;
}
public void setCompanyId (int companyId)
{
this.companyId = companyId;
}
public String getFirstName ()
{
return firstName;
}
public void setFirstName (String firstName)
{
this.firstName = firstName;
}
public String getLastName ()
{
return lastName;
}
public void setLastName (String lastName)
{
this.lastName = lastName;
}
public String getEmail ()
{
return email;
}
public void setEmail (String email)
{
this.email = email;
}
public String getJobTitle ()
{
return jobTitle;
}
public void setJobTitle (String jobTitle)
{
this.jobTitle = jobTitle;
}} ```
此 DTO 类还使用存储库CompanyRepository来获取公司对象并将 DTO 转换为数据库对象。
设置 Spring Batch 配置
现在,我们将为我们的作业设置批处理配置,该作业将运行以将 CSV 文件上传到数据库中。我们的类BatchConfig包含一个注解@EnableBatchProcessing。此注释启用 Spring Batch 功能并提供基本配置以在类中设置批处理作业@Configuration。
``` @Configuration @EnableBatchProcessing public class BatchConfig {
} ```
此批处理配置将包括我们作业的定义、作业中涉及的步骤。它还将包括我们希望如何读取文件数据并进一步处理它。
``` @Bean public Job processJob(Step step) { return jobBuilderFactory.get("processJob") .incrementer(new RunIdIncrementer()) .listener(listener()) .flow(step).end().build(); }
@Bean
public Step orderStep1(JdbcBatchItemWriter writer)
{
return stepBuilderFactory.get("orderStep1").<EmployeeDto, EmployeeDto> chunk(10)
.reader(flatFileItemReader())
.processor(employeeItemProcessor())
.writer(writer).build();
}```
上面的 bean 声明作业processJob.incrementer添加作业参数。listener将听取工作并处理工作状态。侦听器的 bean 将处理作业完成或作业失败通知。正如 Spring Batch 架构中所讨论的,每个作业都包含多个步骤。
@Beanfor step 用于stepBuilderFactory创建一个步骤。此步骤处理大小为 10 的数据块。它有一个 Flat File Reader flatFileItemReader()。处理器employeeItemReader将处理 Flat File Item Reader 读取的数据。
``` @Bean public FlatFileItemReader flatFileItemReader() { return new FlatFileItemReaderBuilder() .name("flatFileItemReader") .resource(new ClassPathResource("input/employeedata.csv")) .delimited() .names(format) .linesToSkip(1) .lineMapper(lineMapper()) .fieldSetMapper(new BeanWrapperFieldSetMapper(){{ setTargetType(EmployeeDto.class); }}) .build(); }
@Bean
public LineMapper lineMapper()
{
final DefaultLineMapper defaultLineMapper = new DefaultLineMapper<>();
final DelimitedLineTokenizer delimitedLineTokenizer = new DelimitedLineTokenizer();
delimitedLineTokenizer.setDelimiter(",");
delimitedLineTokenizer.setStrict(false);
delimitedLineTokenizer.setNames(format);
defaultLineMapper.setLineTokenizer(delimitedLineTokenizer);
defaultLineMapper.setFieldSetMapper(employeeDtoFieldSetMapper);
return defaultLineMapper;
}
@Bean
public EmployeeItemProcessor employeeItemProcessor()
{
return new EmployeeItemProcessor();
}
@Bean
public JobExecutionListener listener()
{
return new JobCompletionListener();
}
@Bean
public JdbcBatchItemWriter writer(final DataSource dataSource)
{
return new JdbcBatchItemWriterBuilder()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO employee(employeeId, firstName, lastName, jobTitle, email, " +
"companyId) VALUES(:employeeId, :firstName, :lastName, :jobTitle, :email," +
" " +
":companyId)")
.dataSource(dataSource)
.build();
}```
我们现在将看看这些 bean 中的每一个。
FlatFileItemReader将从平面文件中读取数据。我们正在使用 FlatFileItemReaderBuilder 创建一个 EmployeeDto 类型的 FlatFileItemReader。
resource指示文件的位置。
delimited– 这构建了一个带分隔符的分词器。
names– 将显示文件中字段的顺序。
lineMapper是将行从文件映射到域对象的接口。
fieldSetMapper将数据从 fieldset 映射到一个对象。
lineMapperbean 需要 tokenizer 和 fieldsetmapper。
employeeDtoFieldSetMapper是我们在这个类中自动装配的另一个 bean。
```
package com.betterjavacode.springbatchdemo.configurations.processor;
import com.betterjavacode.springbatchdemo.dtos.EmployeeDto; import org.springframework.batch.item.file.mapping.FieldSetMapper; import org.springframework.batch.item.file.transform.FieldSet; import org.springframework.stereotype.Component; import org.springframework.validation.BindException;
@Component public class EmployeeDtoFieldSetMapper implements FieldSetMapper {
@Override
public EmployeeDto mapFieldSet (FieldSet fieldSet) throws BindException
{
int employeeId = fieldSet.readInt("employeeId");
String firstName = fieldSet.readRawString("firstName");
String lastName = fieldSet.readRawString("lastName");
String jobTitle = fieldSet.readRawString("jobTitle");
String email = fieldSet.readRawString("email");
int companyId = fieldSet.readInt("companyId");
return new EmployeeDto(employeeId, firstName, lastName, jobTitle, email, companyId);
}} ```
如您所见,此 FieldSetMapper 将字段映射到各个对象以创建一个EmployeeDto.
EmployeeItemProcessor实现接口 ItemProcessor。基本上在这个类中,我们验证 EmployeeDto 数据以验证员工所属的公司是否存在。
JobCompletionListener检查作业完成状态。
@Override public void afterJob(JobExecution jobExecution) { if (jobExecution.getStatus() == BatchStatus.COMPLETED) { // Log statement System.out.println("BATCH JOB COMPLETED SUCCESSFULLY"); } }
现在,让我们来看看ItemWriter。这个bean基本上使用JdbcBatchItemWriter。JdbcBatchItemWriter使用 INSERT sql 语句将处理后的 EmployeeDto 数据插入到配置的数据源中。
配置应用程序属性
在我们运行我们的应用程序来处理文件之前,让我们看一下application.properties.
```
spring.datasource.url=jdbc:mysql://127.0.0.1/springbatchdemo?autoReconnect=true&useSSL=false spring.datasource.username = root spring.datasource.password=* spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.jpa.show-sql=true spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect spring.datasource.hikari.connection-test-query=SELECT 1 spring.batch.initialize-schema=ALWAYS ```
除了常规的数据源属性,我们还应该了解 property spring.batch.initialize-schema=ALWAYS。如果我们不使用这个属性并启动应用程序,应用程序就会报错Table batch_job_instance doesn't exist。
为避免此错误,我们基本上告诉您在启动期间创建与批处理作业相关的元数据。此属性将在您的数据库中创建其他数据库表batch_job_execution,如batch_job_execution_context、batch_job_execution_params、batch_job_instance等。
演示
现在,如果我执行我的 Spring Boot 应用程序,它将运行并执行作业。有多种方法可以触发作业。在企业应用程序中,您将在某种存储位置(S3 或 Amazon SNS-SQS)中收到文件或数据,您将有一个作业将监视此位置以触发文件加载 Spring Batch 作业。

您可以在执行中看到有关作业完成的消息 – “BATCH JOB COMPLETED SUCCESSFULLY“ 。如果我们检查我们的数据库表,我们将看到加载的数据。

更多功能
我在这里介绍了 Spring Batch 教程,但这还不是全部。Spring Batch 的内容远不止这个介绍性部分。您可以有不同的输入数据源,也可以使用各种数据处理规则将数据从一个文件加载到另一个文件。
还有一些方法可以使这些作业自动化并以高效的方式处理大量数据。
结论
在这篇文章中,我逐步展示了 Spring Batch 教程。有很多方法可以处理批处理作业,但 Spring Batch 使这变得非常简单。
















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











