









1.批处理流程
- 获取 Flink 批处理执行环境
- 构建 source
- 数据处理
- 构建 sink
2.wordcount入门案例
- IDEA 建立maven工程 工程目录如下
2.BatchWordCount
package hctang.tech.bacth.Bacth
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.reflect.ClassTag
object BatchWordCount{
def main(args: Array[String]): Unit = {
val env=ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val text=env.fromElements("flink kafka spark"," spark storm hadoop spark hive kafka")
val splitWords=text.flatMap(_.toUpperCase().split(" "))
val filterWords=splitWords.filter(x=>x.nonEmpty)
val wordAndOne=filterWords.map(x=>(x,1))
val groupWords=wordAndOne.groupBy(0)
val sumWords=groupWords.sum(1)
sumWords.print()
}
}
3.pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hctang.flink</groupId>
<artifactId>firstcode</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.0</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.0</version>
<!--<scope>provided</scope>-->
<!--指定包的作用域,集群中运行的话,很多东西并不需要,-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.9.0</version>
</dependency><!--flink kafka connector-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.9.0</version>
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.6</version>
<configuration>
<scalaCompatVersion>2.11</scalaCompatVersion>
<scalaVersion>2.11.8</scalaVersion>
<encoding>UTF-8</encoding>
</configuration>
<executions>
<execution>
<id>compile-scala</id>
<phase>compile</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>test-compile-scala</id>
<phase>test-compile</phase>
<goals>
<goal>add-source</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- 打jar包插件(会包含所有依赖) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- 可以设置jar包的入口类(可选)-->
<mainClass>hctang.tech.bacth.Bacth.BatchWordCount</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
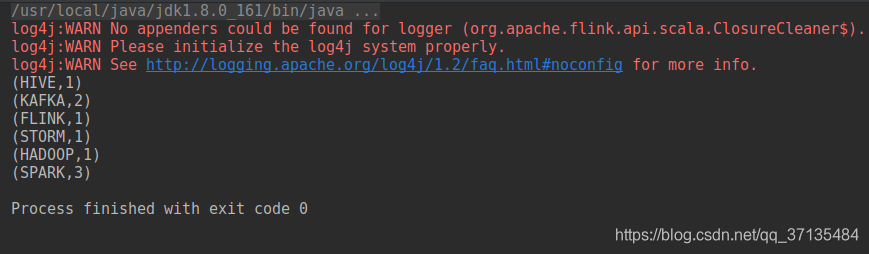
4:输出如下
3.Data Sources
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时的处理些实时数据流,实时的产生数据流结果,只要数据源源不断的过来,Flink 就能够一直计算下去,这个 Data Sources 就是数据的来源地。 flink 在批处理中常见的 source 主要有两大类。
6. 基于本地集合的 source(Collection-based-source)
7. 基于文件的 source(File-based-source)
3.1基于本地集合的 source(Collection-based-source)
在 flink 最常见的创建 DataSet 方式有三种。
-
使用 env.fromElements(),这种方式也支持 Tuple,自定义对象等复合形式。
-
使用 env.fromCollection(),这种方式支持多种 Collection 的具体类型
-
使用 env.generateSequence()方法创建基于 Sequence 的 DataSet
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.ExecutionEnvironment
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
object BatchFromCollection {
def main(args: Array[String]): Unit = { //获取 flink 执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
//0.用 element 创建 DataSet(fromElements)
val ds0: DataSet[String] = env.fromElements("spark", "flink")
ds0.print()
//1.用 Tuple 创建 DataSet(fromElements)
val ds1: DataSet[(Int, String)] = env.fromElements((1, "spark"), (2, "flink"))
ds1.print()
//2.用 Array 创建 DataSet
val ds2: DataSet[String] = env.fromCollection(Array("spark", "flink"))
ds2.print()
//3.用 ArrayBuffer 创建 DataSet
val ds3: DataSet[String] = env.fromCollection(ArrayBuffer("spark", "flink"))
ds3.print()
//4.用 List 创建 DataSet
val ds4: DataSet[String] = env.fromCollection(List("spark", "flink"))
ds4.print()
//5.用 List 创建 DataSet
val ds5: DataSet[String] = env.fromCollection(ListBuffer("spark", "flink"))
ds5.print()
//6.用 Vector 创建 DataSet
val ds6: DataSet[String] = env.fromCollection(Vector("spark", "flink"))
ds6.print()
//7.用 Queue 创建 DataSet
val ds7: DataSet[String] = env.fromCollection(mutable.Queue("spark", "flink"))
ds7.print()
//8.用 Stack 创建 DataSet
val ds8: DataSet[String] = env.fromCollection(mutable.Stack("spark", "flink"))
ds8.print()
//9.用 Stream 创建 DataSet(Stream 相当于 lazy List,避免在中间过程中生成不必要的集合)
val ds9: DataSet[String] = env.fromCollection(Stream("spark", "flink"))
ds9.print()
//10.用 Seq 创建 DataSet
val ds10: DataSet[String] = env.fromCollection(Seq("spark", "flink"))
ds10.print()
//11.用 Set 创建 DataSet
val ds11: DataSet[String] = env.fromCollection(Set("spark", "flink"))
ds11.print()
//12.用 Iterable 创建 DataSet
val ds12: DataSet[String] = env.fromCollection(Iterable("spark", "flink"))
ds12.print()
//13.用 ArraySeq 创建 DataSet
val ds13: DataSet[String] = env.fromCollection(mutable.ArraySeq("spark", "flink"))
ds13.print()
//14.用 ArrayStack 创建 DataSet
val ds14: DataSet[String] = env.fromCollection(mutable.ArrayStack("spark", "flink"))
ds14.print()
//15.用 Map 创建 DataSet
val ds15: DataSet[(Int, String)] = env.fromCollection(Map(1 -> "spark", 2 -> "flink"))
ds15.print()
//16.用 Range 创建 DataSet
val ds16: DataSet[Int] = env.fromCollection(Range(1, 9))
ds16.print()
//17.用 fromElements 创建 DataSet
val ds17: DataSet[Long] = env.generateSequence(1, 9)
ds17.print()
}
}
3.2基于文件的 source(File-based-source)
3.2.1 读取本地文件
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object BatchFromFile {
def main(args:Array[String]):Unit={
//使用readFile 读取本地文件
val environment:ExecutionEnvironment=ExecutionEnvironment.getExecutionEnvironment
val data:DataSet[String]=environment.readTextFile("data/data.txt")
//导入隐式转换
import org.apache.flink.api.scala._
//指定数据的转换
val flatmap_data:DataSet[String]=data.flatMap(Line=>Line.split("\\W+"))
val tuple_data:DataSet[(String,Int)]= flatmap_data.map(line=>(line,1))
tuple_data.print()
val groupData:GroupedDataSet[(String,Int)]=tuple_data.groupBy(line => line._1)
val result:DataSet[(String,Int)]=groupData.reduce((x,y)=>(x._1,x._2+y._2))//统计相同键下的数量
//触发程序执行
result.print()
}
}
3.2.2 读取HDFS文件
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object BatchfromHDFSFile {
def main(args: Array[String]): Unit = { //使用 readTextFile 读取本地文件
//初始化环境
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//加载数据
val datas: DataSet[String] = environment.readTextFile("hdfs://localhost:9000/words.txt")//hdfs地址
//导入隐式转换
import org.apache.flink.api.scala._
//指定数据的转化
val flatmap_data: DataSet[String] = datas.flatMap(line => line.split("\\W+"))
val tuple_data: DataSet[(String, Int)] = flatmap_data.map(line => (line , 1))
val groupData: GroupedDataSet[(String, Int)] = tuple_data.groupBy(line => line._1)
val result: DataSet[(String, Int)] = groupData.reduce((x, y) => (x._1 , x._2+y._2))
//触发程序执行
result.print()
}
}
3.2.3 读取CSV文件
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.ExecutionEnvironment
object BatchFromCsvFile {
def main(args: Array[String]): Unit = { //初始化环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//导入隐式转换
import org.apache.flink.api.scala._
//加载数据
val datas = env.readCsvFile[(Int,String,String, String,Int, String)](filePath = "/home/tanghc/桌面/hiteamteach/tieba.csv",
lineDelimiter = "\n", //分隔行的字符串,默认为换行。
fieldDelimiter=",", //分隔单个字段的字符串,默认值为“,”
lenient = true, //解析器是否应该忽略格式不正确的行。
ignoreFirstLine = false,//是否应忽略文件中的第一行。
includedFields=Array(0,1,2,3,4,5)
)
//触发程序执行
datas.print()
}
}
3.2.4 目录遍历读取
flink 支持对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式。
对于从文件中读取数据,当读取的数个文件夹的时候,嵌套的文件默认是不会被读取的,只
会读取第一个文件,其他的都会被忽略。所以需要使用 recursive.file.enumeration 进行
递归读取
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
object BatchFromFolder {
def main(args: Array[String]): Unit = {
//初始化环境
val env = ExecutionEnvironment.getExecutionEnvironment
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val result = env.readTextFile("data").withParameters(parameters)
//触发程序执行
result.print()
}
}
3.2.5 压缩文件读取
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.ExecutionEnvironment
object BatchFromCompressFile {
def main(args:Array[String]):Unit={
val env=ExecutionEnvironment.getExecutionEnvironment
//对于以下格式的压缩文件可以直接对去,不过不支持并行读取,只能顺序读取,会影响性能和作业的伸缩性
//.deflate; .gz;.gzip;.bz2;.xz
val result=env.readTextFile("")
result.print()
}
}
4.DateSet之Transformation
常用的一些transformmation
| Transformation | 描述 | 举例 |
|---|---|---|
| Map | 对集合元素,进行一一遍历处理 | data.map { x => x.toInt } |
| FlatMap | 一个数据元生成多个数据元(可以为 0) | data.flatMap { str => str.split(" ") } |
| MapPartition | 函数处理包含一个分区所有数据的“迭代器”,可以生成任意数量的结果值。每个分区中的元素数量取决于并行度和先前的算子操作。 | data.mapPartition { in => in map { (_, 1) } } |
| Filter | 对集合元素,进行一一遍历处理,只过滤满足条件的元素 | data.filter { _ > 1000 } |
| Reduce | 作用于整个 DataSet,合并该数据集的元素。 | data.reduce { _ + _ } |
| ReduceGroup | 通过将此数据集中的所有元素传递给函数,创建一个新的数据集。该函数可以使用收集器输出零个或多个元素。也可以作用与完整数据集,迭代器会返回完整数据集的元素 | data.reduceGroup { elements => elements.sum } |
| Distinct | 对数据集中的元素除重并返回新的数据集。 | data.distinct() |
| Aggregate | 对一组数据求聚合值,聚合可以应用于完整数据集或分组数据集。聚合转换只能应用于元组(Tuple)数据集,并且仅支持字段位置键进行分组。 | 有一些常用的聚合算子,提供以下内置聚合函数(): |
| val input: DataSet[(Int, String, Double)] = // […] | ||
| val output: DataSet[(Int, String, Doublr)] = input.aggregate(SUM, 0).aggregate(MIN, 2); |
5.数据输出data Sinks
flink在批处理中常见的Sink
- 基于本地集合的sink(Collection-based-sink)
- 基于文件的sink(File-based-sink)
package hctang.tech.bacth.Bacth
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.core.fs.FileSystem.WriteMode
import scala.reflect.ClassTag
object BatchWordCount{
def main(args: Array[String]): Unit = {
val env=ExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
val text=env.fromElements("flink kafka spark"," spark storm hadoop spark hive kafka")
print("1")
val splitWords=text.flatMap(_.toUpperCase().split(" "))
val filterWords=splitWords.filter(x=>x.nonEmpty)
val wordAndOne=filterWords.map(x=>(x,1))
val groupWords=wordAndOne.groupBy(0)
val sumWords=groupWords.sum(1)
//3.TODO sink 到标准输出
print("标准输出")
sumWords.print
//3.TODO sink 到标准 error 输出
print("错误输出")
sumWords.printToErr()
//4.TODO sink 到本地 Collection
print("到本地Collection")
print(sumWords.collect())
//0.主意:不论是本地还是 hdfs.若 Parallelism>1 将把 path 当成目录名称,若 Parallelism=1 将把 path 当成文件名。
//1.TODO 写入到本地,文本文档,NO_OVERWRITE 模式下如果文件已经存在,则报错,OVERWRITE 模式下如果文件已经存在,则覆盖
sumWords.setParallelism(1).writeAsText("data/out/aa", WriteMode.OVERWRITE)
env.execute()
//写入HDFS
sumWords.setParallelism(1).writeAsText("hdfs://localhost:9000/wc/wordcount.txt", WriteMode.OVERWRITE)
}
}
6.广播变量
Flink 支持广播变量,就是将数据广播到具体的 taskmanager 上,数据存储在内存中,这样可以减缓大量的 shuffle 操作;
比如在数据 join 阶段,不可避免的就是大量的 shuffle 操作,我们可以把其中一个 dataSet广播出去,一直加载到 taskManager 的内存中,可以直接在内存中拿数据,避免了大量的 shuffle,导致集群性能下降;
广播变量创建后,它可以运行在集群中的任何 function 上,而不需要多次传递给集群节点。另外需要记住,不应该修改广播变量,这样才能确保每个节点获取到的值都是一致的。
一句话解释,可以理解为是一个公共的共享变量,我们可以把一个 dataset 数据集广播出去,然后不同的 task 在节点上都能够获取到,这个数据在每个节点上只会存在一份。如果不使用broadcast,则在每个节点中的每个 task 中都需要拷贝一份 dataset 数据集,比较浪费内存(也就是一个节点中可能会存在多份 dataset 数据)。
注意:因为广播变量是要把 dataset 广播到内存中,所以广播的数据量不能太大,否则会出现 OOM (OutOfMemory内存溢出)这样的问题
- Broadcast:Broadcast 是通过 withBroadcastSet(dataset,string)来注册的
- Access:通过 getRuntimeContext().getBroadcastVariable(String)访问广播变量
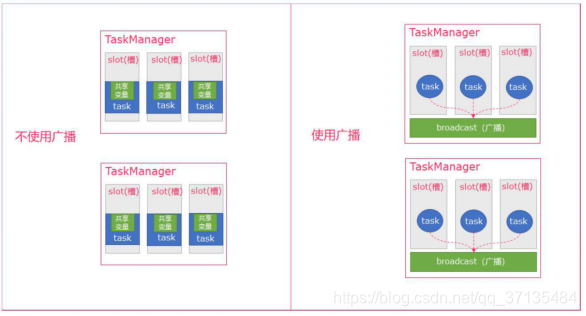
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的 Task 都可以在节点上获取到
- 每个节点 只存一份
- 如果不使用广播,每一个 Task 都会拷贝一份数据集,造成内存资源浪费
用法
在需要使用广播的操作后,使用 withBroadcastSet 创建广播,
在操作中,使用 getRuntimeContext.getBroadcastVariable [广播数据类型] ( 广播名 )获取广
播变量
示例
创建一个 学生 数据集,包含以下数据
| 学生 ID | 姓名 |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
List((1, “张三”), (2, “李四”), (3, “王五”))
将该数据,发布到广播。
再创建一个 成绩 数据集,
| 学生 ID | 学科 | 成绩 |
|---|---|---|
| 1 | 语文 | 50 |
| 2 | 数学 | 70 |
| 3 | 英文 | 86 |
List( (1, “语文”, 50),(2, “数学”, 70), (3, “英文”, 86))
通过广播获取到学生姓名,将数据转换为
List( (“张三”, “语文”, 50),(“李四”, “数学”, 70), (“王五”, “英文”, 86))
步骤
获取批处理运行环境
分别创建两个数据集
使用 RichMapFunction 对 成绩 数据集进行 map 转换
在数据集调用 map 方法后,调用 withBroadcastSet 将 学生 数据集创建广播
实现 RichMapFunction
将成绩数据(学生 ID,学科,成绩) -> (学生姓名,学科,成绩)
重写 open 方法中,获取广播数据
导入 scala.collection.JavaConverters._ 隐式转换
d. 将广播数据使用 asScala 转换为 Scala 集合,再使用 toList 转换为 scala List 集合
e. 在 map 方法中使用广播进行转换
打印测试
package hctang.tech.bacth.Bacth
import java.util
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
object BacthBroadcastDemo {
def main(args: Array[String]): Unit = { /**
*1. 获取批处理运行环境
*2. 分别创建两个数据集
* 3. 使用 RichMapFunction 对 成绩 数据集进行 map 转换
*4. 在数据集调用 map 方法后,调用 withBroadcastSet 将 学生 数据集创建广播
*5. 实现 RichMapFunction
*将成绩数据(学生 ID,学科,成绩) -> (学生姓名,学科,成绩)
*重写 open 方法中,获取广播数据
*导入 scala.collection.JavaConverters._ 隐式转换
* 将广播数据使用 asScala 转换为 Scala 集合,再使用 toList 转换为 scala List 集合
*在 map 方法中使用广播进行转换
*6. 打印测试
*/
//1. 获取批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2. 分别创建两个数据集
//创建学生数据集
val stuDataSet: DataSet[(Int, String)] = env.fromCollection(
List((1, "张三"), (2, "李四"), (3, "王五"))
)
//创建成绩数据集
val socreDataSet: DataSet[(Int, String, Int)] = env.fromCollection( List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
)
//3. 使用 RichMapFunction 对 成绩 数据集进行 map 转换
//返回值类型(学生名字,学科成名,成绩)
val result: DataSet[(String, String, Int)] = socreDataSet.map(new RichMapFunction[(Int, String, Int), (String, String, Int)] {
//定义获取学生数据集的集合
var studentMap:Map[Int, String] = null
//初始化的时候被执行一次,在对象的生命周期中只被执行一次
override def open(parameters: Configuration): Unit = {
//因为获取到的广播变量中的数据类型是 java 的集合类型,但是我们的代码是 scala 因此需要将 java 的集合转换成 scala 的集合
//我们这里将 list 转换成了 map 对象,之所以能够转换是因为 list 中的元素是对偶元祖,因此可以转换成 kv 键值对类型
//之所以要转换,是因为后面好用,传递一个学生 id,可以直接获取到学生的名字
import scala.collection.JavaConversions._
val studentList: util.List[(Int, String)] = getRuntimeContext.getBroadcastVariable[(Int, String)]("student")
studentMap = studentList.toMap
}
//要对集合中的每个元素执行 map 操作,也就是说集合中有多少元素,就被执行多少次
override def map(value: (Int, String, Int)): (String, String, Int) = {
//(Int, String, Int)=》(学生 id,学科名字,学生成绩)
//返回值类型(学生名字,学科成名,成绩)
val stuId = value._1
val stuName = studentMap.getOrElse(stuId, "")
//(学生名字,学科成名,成绩)
(stuName, value._2, value._3)
}
}).withBroadcastSet(stuDataSet, "student")
result.print()
}
}
package hctang.tech.bacth.BacthAPI
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.mutable.ListBuffer
/**
* broadcast 广播变量
* Created by xuwei.tech on 2018/10/30.
*/
object BatchDemoBroadcastScala {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
//1: 准备需要广播的数据
val broadData = ListBuffer[Tuple2[String,Int]]()
broadData.append(("zs",18))
broadData.append(("ls",20))
broadData.append(("ww",17))
//1.1处理需要广播的数据
import org.apache.flink.api.scala._
implicit val typeInfo = TypeInformation.of(classOf[(String,Int)])
val tupleData = env.fromCollection(broadData)
val toBroadcastData = tupleData.map(tup=>{
Map(tup._1->tup._2)
})
val text = env.fromElements("zs","ls","ww")
val result = text.map(new RichMapFunction[String,String] {
var listData: java.util.List[Map[String,Int]] = null
var allMap = Map[String,Int]()
override def open(parameters: Configuration): Unit = {
super.open(parameters)
this.listData = getRuntimeContext.getBroadcastVariable[Map[String,Int]]("broadcastMapName")
val it = listData.iterator()
while (it.hasNext){
val next = it.next()
allMap = allMap.++(next)
}
}
override def map(value: String) = {
val age = allMap.get(value).get
value+","+age
}
}).withBroadcastSet(toBroadcastData,"broadcastMapName")
result.print()
}
}














 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









