







这边文章是Spring源码深度解析读书笔记的读书笔记
BeanFactory bf = new XmlBeanFactory(new ClassPathResource("org/springframework/beans/application-context.xml"));
解析该行代码调用全过程
- ClassPathResource将文件加载为Resource文件,通过ClassUtils获取默认的DefaultClassLoader
XmlBeanFactory - 通过调用父类DefaultListableBeanFactory,同时DefaultListableBeanFactory在调用其父类
AbstractAutowireCapableBeanFactory的构造器,实现上述几个类的初始化,以及通过
ignoreDependencyInterface(BeanNameAware.class);
ignoreDependencyInterface(BeanFactoryAware.class);
ignoreDependencyInterface(BeanClassLoaderAware.class);
实现忽略给定接口的自动装配功能(具体原因查阅spring源码P30)
- 调用XmlBeanFactory中的XmlBeanDefinitionReader的loadBeanDefinition方法来对Xml文件进行解析
XmlBeanDefinitionReader - 首先将Resource文件转换成EncodedResource文件,EncodedResource类主要用于对资源文件的编码
进行处理,其主要的逻辑在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为
输入流的编码。 - 在loadBeanDefinitions方法中
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
该代码主要通过属性来记录已经加载的资源
InputStream inputStream = encodedResource.getResource().getInputStream();
该代码主要从EncodedResource的文件中获取Resource的InputStream
- 在doLoadBeanDefinitions方法中继续调用doLoadDocument方法,方法内部如下:
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws
Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(),
this.errorHandler,getValidationModeForResource(resource), isNamespaceAware());
}
- 在这里首先调用了getValidationModeForResource(resource)方法去获取XML文件的验证模式(DTD/XSD),主要通过是否存在DOCTYPE来判读(true为DTD),非自动验证的模式可以通过调 用XmlBeanDefinitionReader的setValidationMode方法实现,下面是该方法的实现
protected int getValidationModeForResource(Resource resource) {
int validationModeToUse = getValidationMode();
if (validationModeToUse != VALIDATION_AUTO) {
return validationModeToUse;
}
int detectedMode = detectValidationMode(resource);
if (detectedMode != VALIDATION_AUTO) {
return detectedMode;
}
// Hmm, we didn't get a clear indication... Let's assume XSD,
// since apparently no DTD declaration has been found up until
// detection stopped (before finding the document's root tag).
return VALIDATION_XSD;
}
这块儿注释的意思是反正我们没得到指示,就假装是XSD吧
int detectedMode = detectValidationMode(resource);
这行代码调用了XmlValidationModeDetector的detectValidationMode方法去对自动验证模式下的验证方
式做了判断
DocumentLoader:
- 通过6进入到DocumentLoader的实现类DefaultDocumentLoader中进行Document的加载,该方法
中主要就是先创建DocumentBuilderFactory,再通过其创建DocumentBuilder
public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws
Exception {
DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode,
namespaceAware);
if (logger.isDebugEnabled()) {
logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver,
errorHandler);
return builder.parse(inputSource);
}
DocumentBuilder builder = createDocumentBuilder(factory, entityResolver,errorHandler);
该行代码会调用下列方法
PluggableSchemaResolver:
-
因为这次用到的是XSD验证模式,所以我们进入了EntityResolver的其中一个实现
类PluggableSchemaResolver中调用其resolveEntity方法来下载相应的定义,以便对文档进行一个
验证。DTD是通过BeansDtdResolver的resolveEntity来下载相应的DTD声明。 -
6-9都是将文件转换为Document,回到6的下一行,XmlBeanDefinitionReader的
registerBeanDefinitions方法负责提取以及注册BeanDefinition
public int registerBeanDefinitions(Document doc, Resource resource) throws
BeanDefinitionStoreException {
//使用DefaultBeanDefinitionDocumentReader去实例化BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//记录统计前BeanDefinition的加载个数
int countBefore = getRegistry().getBeanDefinitionCount();
//在实例化BeanDefinitionDocumentReader时候会将BeanDefinitionRegistry传入,默认使用继承自
DefaultBeanDefinitionDocumentReader的子类
//加载及注册bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//记录本次加载的BeanDefinition个数
return getRegistry().getBeanDefinitionCount() - countBefore;
}
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
在该方法中,会去调用DefaultBeanDefinitionDocumentReader
的documentReader.registerBeanDefinitions方法,
DefaultBeanDefinitionDocumentReader:
- 之前都算是XML加载解析的准备阶段, registerBeanDefinitions方法中的doRegisterBeanDefinitions
方法才算是真正地开始解析XML
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
pre和pos方法用于如果继承自DefaultBeanDefinitionDocumentReader的子类需要在Bean解析前后做
一些处理的话,只需要重写这两个方法就好了。par方法里通过if else 判断走默认还是自定义进行解析,代码如下:
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
补一下容器加载的相关类图
DefaultListableBeanFactory
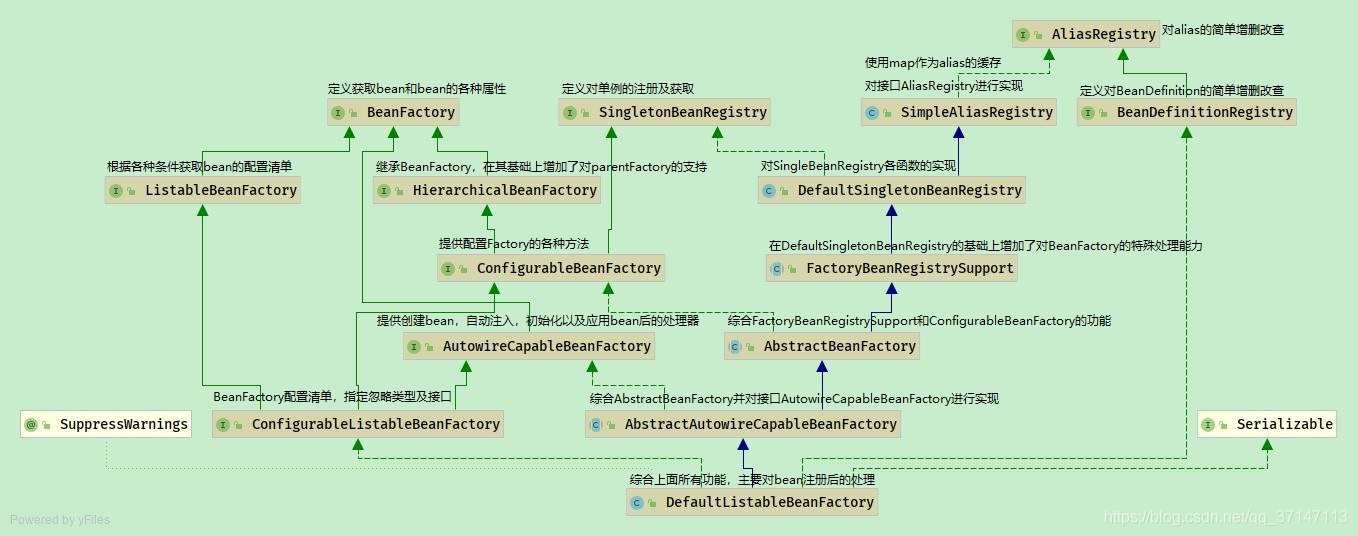
图未完待续…
综上,xml的解析就算是完成了,默认和自定义标签的解析下次再写读书笔记吧














 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









