








项目2个版本的代差较大,。要把客户生成环境升级成高版本。要把高版本累加的表结构同步到客户低版本生产环境。又不能影响客户生产环境的原有数据。
方案:
1> 用多数据源把2个版本的表和列定义读出来。
2>在代码里进行分析低版本缺失的表和字段,并生成脚本。
简单的多数据源+查表元数据+代码分析应用。实用有效。逻辑部很很简单,简单的包含与不包含判断是否需要添加删除。
// 读取表的元数据
public class TableMaterial {
//低版本的表集合
private List<String> v4tableNames = new ArrayList<>();
//低版本的表与列的关系映射
private Map<String, List<GenTableColumn>> v4TableColumns = new HashMap<>();
//高版本表集合
private List<String> v41tableNames = new ArrayList<>();
//高版本表映射
private Map<String, List<GenTableColumn>> v41TableColumns = new HashMap<>();
}
//分析缺失的表
public class AddTableDropTableAnalyser implements VersionAnalyser {
public void analyser(TableMaterial tableMaterial) {
List<String> v4tableNames = tableMaterial.getV4tableNames();
List<String> v41tableNames = tableMaterial.getV41tableNames();
//低版本需要补建的表,这里只是在公司把要建的表弄到一个单独的库里,再从单独的库里导出详细的建表语句。所以用了like建表。
StringBuffer addTableMessages = new StringBuffer();
String createTableSql = "create table %s like xxx.%s;" + System.lineSeparator();
for (String v41tableName : v41tableNames) {
if (!v4tableNames.contains(v41tableName)) {
addTableMessages.append(String.format(createTableSql, v41tableName, v41tableName));
}
}
FileUtils.addContent("41版本比对40版本添加的表.sql", addTableMessages.toString());
// 删除的表,这部份脚本没必要在低版本执行。
StringBuffer delTableMessages = new StringBuffer();
String dropTableSql = "drop table %s;" + System.lineSeparator();
for (String v4tableName : v4tableNames) {
if (!v41tableNames.contains(v4tableName)) {
delTableMessages.append(String.format(dropTableSql, v4tableName));
}
}
FileUtils.addContent("41版本比对40版本删除的表.sql", delTableMessages.toString());
}
}
//分析缺失的字段
public class ColumnInfoAnalyser implements VersionAnalyser {
private StringBuffer addColumns = null;
private StringBuffer dropColumns = null;
@Override
public void analyser(TableMaterial tableMaterial) {
addColumns = new StringBuffer();
dropColumns = new StringBuffer();
// 低版本表和字段
Map<String, List<GenTableColumn>> v4TableColumns = tableMaterial.getV4TableColumns();
// 高版本表和字段
Map<String, List<GenTableColumn>> v41TableColumns = tableMaterial.getV41TableColumns();
v41TableColumns.forEach((tableName, v41Columns) -> {
if (v4TableColumns.containsKey(tableName)) {
List<GenTableColumn> v4Columns = v4TableColumns.get(tableName);
toAnalyserCloumn(tableName, v4Columns, v41Columns);
}
});
FileUtils.addContent("要添加的字段.sql", addColumns.toString());
// 实际没有执行该脚本。有少许脏数据。没啥影响。
FileUtils.addContent("要移除字段.sql", dropColumns.toString());
}
private void toAnalyserCloumn(String tableName, List<GenTableColumn> v4Columns, List<GenTableColumn> v41Columns) {
List<String> v4ColumnNames = new ArrayList<>();
List<String> v41ColumnNames = new ArrayList<>();
for (GenTableColumn v4Column : v4Columns) {
v4ColumnNames .add(v4Column.getColnmnName().toLowerCase());
}
for (GenTableColumn v41Column : v41Columns) {
v41ColumnNames.add(v41Column.getColnmnName().toLowerCase());
}
for (GenTableColumn v41Column : v41Columns) {
String columnName = v41Column.getColnmnName().toLowerCase();
if (!v4ColumnNames .contains(columnName)) {
String jdbcType = v41Column.getJdbcType();
String columnType = jdbcType.toLowerCase();
String sql = "alter table %s add %s %s;" + System.lineSeparator();
if (jdbcType.contains("char")) {
Long colnmnLength = v41Column.getColnmnLength();
jdbcType = jdbcType + "(" + colnmnLength + ")";
}
String format = String.format(sql, tableName, columnName, jdbcType);
addColumns.append(format);
}
}
for (GenTableColumn v41Column : v4Columns) {
String colnmnName = v41Column.getColnmnName().toLowerCase();
if (!v41ColumnNames.contains(colnmnName)) {
String sql = "alter table %s drop %s ;" + System.lineSeparator();
dropColumns.append(String.format(sql, tableName, colnmnName));
}
}
}
}
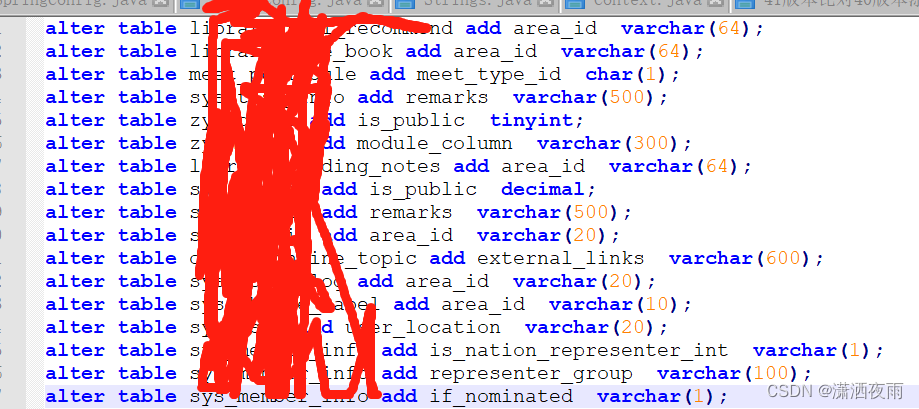
//文件生成效果:
















 652
652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









