







变分推断:用“简单线条”勾勒“复杂风景”的核心公式与代码实战
一、核心结论:变分推断是概率世界的高效素描术
“就像用简笔画替代写实油画,变分推断用简单分布捕捉复杂分布的关键特征”
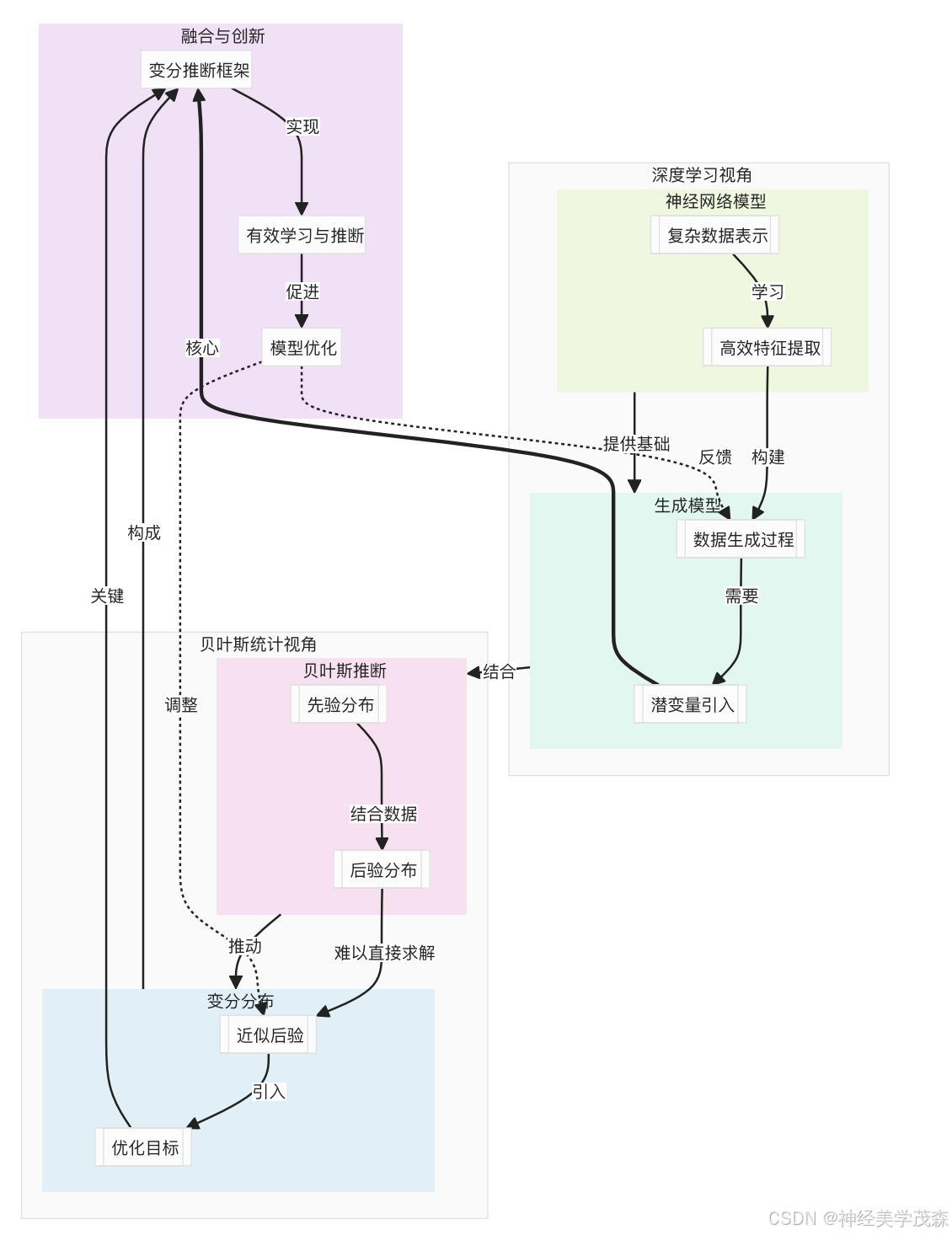
二、公式推演与类比解释
1. 核心公式对比表
| 公式名称 | 数学表达式 | 通俗解释 | 类比场景 |
|---|---|---|---|
| KL散度 | D K L ( q ∣ ∣ p ) = E q [ log q ( z ) p ( z ∣ x ) ] D_{KL}(q||p) = \mathbb{E}_q[\log \frac{q(z)}{p(z|x)}] DKL(q∣∣p)=Eq[logp(z∣x)q(z)] | 两幅画的差异程度 | 比较简笔画与原画的失真度 |
| ELBO目标 | log p ( x ) ≥ E q [ log p ( x , z ) ] − D K L ( q ∣ ∣ p ) \log p(x) \geq \mathbb{E}_q[\log p(x,z)] - D_{KL}(q||p) logp(x)≥Eq[logp(x,z)]−DKL(q∣∣p) | 寻宝指南针 | 导航仪显示的可行路径下限 |
| 变分分布 | q ( z ; λ ) = ∏ i q ( z i ; λ i ) q(z;\lambda) = \prod_{i} q(z_i;\lambda_i) q(z;λ)=∏iq(zi;λi) | 素描工具包 | 画家携带的铅笔/橡皮等工具组合 |
2. 核心公式详解
公式1:证据下界(ELBO)
L = E q [ log p ( x ∥ z ) ] ⏟ 重建精度 − D K L ( q ( z ) ∥ ∥ p ( z ) ) ⏟ 分布偏差 \mathcal{L} = \underbrace{\mathbb{E}_q[\log p(x\|z)]}_{\text{重建精度}} - \underbrace{D_{KL}(q(z)\|\|p(z))}_{\text{分布偏差}} L=重建精度 Eq[logp(x∥z)]−分布偏差 DKL(q(z)∥∥p(z))
| 参数 | 数学符号 | 类比解释 | 取值范围 |
|---|---|---|---|
| 观测数据 | x x x | 待临摹的复杂风景画 | 原始数据维度 |
| 隐变量 | z z z | 画家的素描草稿 | 潜在空间维度 |
| 近似分布 | q ( z ) q(z) q(z) | 简笔画技法 | 参数化分布族 |
| 先验分布 | p ( z ) p(z) p(z) | 绘画的基本构图规则 | 预设分布类型 |
案例应用:在VAE中,ELBO第一项确保重建图像逼真,第二项防止简笔画过度偏离原画风格
公式2:KL散度分解
D K L ( q ∥ ∥ p ) = E q [ log q ] − E q [ log p ] D_{KL}(q\|\|p) = \mathbb{E}_q[\log q] - \mathbb{E}_q[\log p] DKL(q∥∥p)=Eq[logq]−Eq[logp]
| 项 | 物理意义 | 类比解释 |
|---|---|---|
| E q [ log q ] \mathbb{E}_q[\log q] Eq[logq] | 简笔画的复杂度 | 素描使用的线条数量 |
| E q [ log p ] \mathbb{E}_q[\log p] Eq[logp] | 符合原画的程度 | 素描与原画的相似度 |
3. 进阶公式推导
均值场变分推断:
q
(
z
)
=
∏
i
=
1
d
q
i
(
z
i
)
q(z) = \prod_{i=1}^d q_i(z_i)
q(z)=i=1∏dqi(zi)
log
q
j
∗
(
z
j
)
=
E
i
≠
j
[
log
p
(
x
,
z
)
]
+
const
\log q_j^*(z_j) = \mathbb{E}_{i\neq j}[\log p(x,z)] + \text{const}
logqj∗(zj)=Ei=j[logp(x,z)]+const
随机梯度变分推断(SGVI):
∇
λ
L
≈
1
L
∑
l
=
1
L
∇
λ
log
q
(
z
(
l
)
;
λ
)
(
log
p
(
x
,
z
(
l
)
)
−
log
q
(
z
(
l
)
;
λ
)
)
\nabla_\lambda \mathcal{L} \approx \frac{1}{L}\sum_{l=1}^L \nabla_\lambda \log q(z^{(l)};\lambda)(\log p(x,z^{(l)}) - \log q(z^{(l)};\lambda))
∇λL≈L1l=1∑L∇λlogq(z(l);λ)(logp(x,z(l))−logq(z(l);λ))
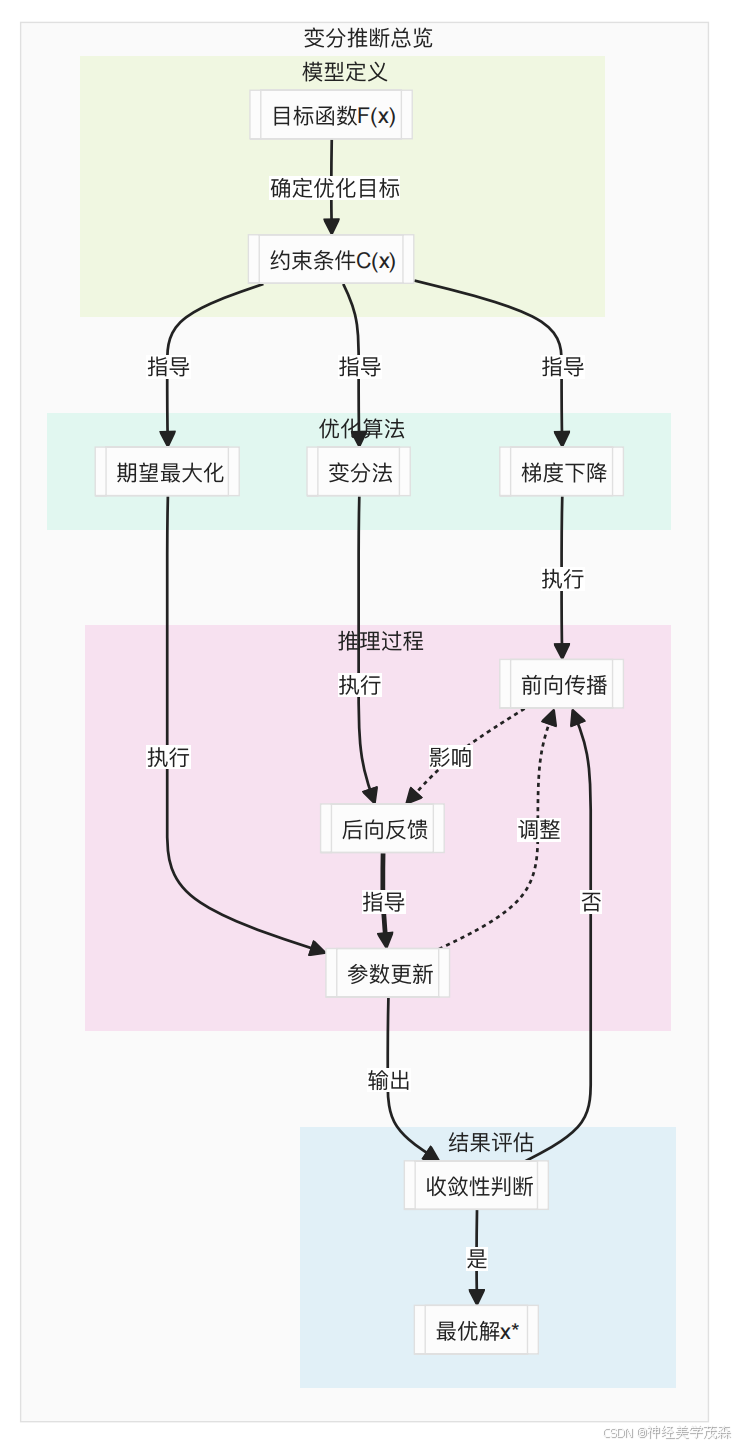
三、代码实战:高斯混合分布的变分近似
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
# 生成双峰分布数据
np.random.seed(42)
true_data = np.concatenate([np.random.normal(-3,1,500),
np.random.normal(3,1,500)])
# 变分参数初始化
mu_q = 0.0 # 初始均值
sigma_q = 4.0 # 初始标准差
lr = 0.01 # 学习率
# ELBO优化过程
elbo_history = []
for epoch in range(500):
# 采样隐变量
z_samples = np.random.normal(mu_q, sigma_q, 100)
# 计算梯度
grad_mu = np.mean(z_samples - mu_q + (true_data[np.random.randint(1000)] - z_samples))
grad_sigma = np.mean(1/sigma_q - (z_samples - mu_q)**2/sigma_q**3 + 1/sigma_q)
# 参数更新
mu_q += lr * grad_mu
sigma_q = np.clip(sigma_q + lr * grad_sigma, 0.1, 10)
# 计算ELBO
elbo = np.mean(norm.logpdf(z_samples, mu_q, sigma_q)) \
- 0.5*np.log(2*np.pi) - 0.5*np.mean((true_data[np.random.choice(1000,100)] - z_samples)**2)
elbo_history.append(elbo)
# 可视化
plt.figure(figsize=(12,6))
sns.kdeplot(true_data, label="True Distribution", linewidth=3)
x = np.linspace(-8,8,500)
plt.plot(x, norm.pdf(x, mu_q, sigma_q), 'r--', label="Variational Approximation")
plt.title(f'Variational Fit: μ={mu_q:.2f}, σ={sigma_q:.2f}')
plt.legend()
plt.show()
# ELBO收敛曲线
plt.figure(figsize=(10,5))
plt.plot(elbo_history, color='darkorange')
plt.xlabel('Iteration'), plt.ylabel('ELBO')
plt.title('Evidence Lower Bound Optimization')
plt.grid(True)
plt.show()
四、可视化解析
- 分布对比图:红色虚线逐渐逼近真实双峰分布,显示变分分布的学习过程
- ELBO曲线:橙色曲线显示目标函数单调上升,验证优化有效性
五、公式体系总览
| 公式类型 | 典型代表 | 应用场景 |
|---|---|---|
| 基础公式 | ELBO分解式 | VAE等生成模型 |
| 优化公式 | 自然梯度更新式 | 复杂后验近似 |
| 随机化公式 | 重参数化技巧 | 连续隐变量优化 |
| 非参数化公式 | 核密度变分推断 | 高维数据分析 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











