







1.索引设计依据
要估算每个数据表全部的查询sql语句类型
分析、统计每个sql语句的特点(where/order by/or等等)
原则:
① 被频繁执行的sql语句要设置
② 执行时间比较长的sql语句(可以统计)
③ 业务逻辑比较重要的sql语句(例如支付宝2小时内答应返现的业务逻辑)
2.前缀索引
设计索引的字段,不使用全部内容,而只使用该字段前边一部分内容。
如果字段的前边N位的信息已经可以足够标识当前记录信息,就可以把前边N位信息设置为索引内容,好处:索引占据的物理空间小、运行速度就非常快。
举个例子:
石清清
李德升
许成宝
王伟聪
以上4条记录信息,通过前边一个字就可以唯一标识当前记录信息,创建索引的时候就使用前边第一个字即可,节省空间、运行速度快。
具体实现:
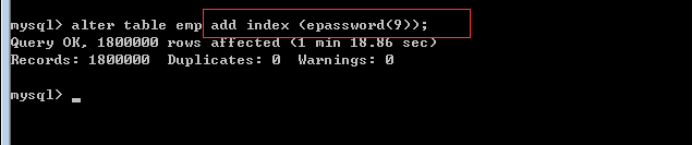
① 操作 alter table 表名 add index (字段(位数)) //只取字段前面几位数
② 前边到底取得多少位,才是记录的唯一标识
总记录数目/前n位记录数目 = 比值;
select count(*) from 表名;
mysql字符串截取:substring(字段,开始位置1开始,长度) //mysql中substring函数开始位置从1开始


从结果可以看出,密码的前9位就可以唯一标识当前记录信息:

现在给epassword创建索引,就可以只取得前9位即可:

3.索引设计原则
字段内容需要足够花样
性别字段不适合做索引
4. 全文索引
Mysql5.5 Myisam存储引擎 支持全文索引
Mysql5.6 Myisam和Innodb存储引擎 都支持全文索引

目前中文不支持全文索引。
全文索引可以应用在 like ‘%XXX%’ 的操作上边。

创建articles数据表,并设置一个单列全文索引:


需要变形为match() against()才可以使用全文索引:


复合全文索引的使用:


5. 索引结构(了解)
索引内部有算法,算法可以保证查询速度比较快速。
算法的基础 是 数据结构。
索引的直接称谓就是“数据结构”
在Mysql数据库中,索引是存储引擎层面的技术。
不同的存储引擎使用的数据结构是不一样的。
两种索引结构
① 非聚集索引结构(Myisam)
② 聚集索引结构(Innodb)
5.1 Myisam非聚集索引结构
称为:B+Tree索引结构

Myisam存储引擎的索引结构为B+Tree:

上图为B+Tree索引结构,索引结构内部分为索引节点
节点从左到右 是节点的“宽度”
节点从上到下的层数 是 结构 的“高度”
宽度或高度太大都不适合快速索引查找
宽度 和 高度 的设计会根据数据量的大小做适当的选择(mysql底层的算法)
该索引结构“叶子节点” 存储关键字和物理地址,非叶子节点存储关键字和指针,指针用于数据的比较、判断、向下个节点查找。
5.2 Innodb聚集索引结构
索引结构名称:B+Tree
1)主键索引结构
重要一点:叶子节点 的关键字(主键id值)对应整条记录信息
2)非主键索引结构(唯一、普通等)
叶子节点 的关键字 对应 主键id值

非主键索引-------------innodb的主键索引-------------整条记录
这样我们可以看到:索引 和 数据 是在一起的
innodb表物理文件的 索引 和 数据 确实在一起:
(*.ibd集中存储order2数据表的 索引和 数据)

概念问题:
B-Tree、B+Tree、 Binary Tree
B+Tree是B-Tree的一个变形
B-Tree与B+Tree的明显区别是:B-Tree的每个节点的关键字都与“物理地址对应”
Binary Tree二进制树结构
三.查询缓存设置
一条查询sql语句有可能获得很多数据,并且有一定的时间消耗
如果该sql语句被频繁执行获得数据(这些数据还不经常发生变化),为了使得每次获得的信息速度较快,就可以把“执行结果”给缓存起来,供后续的每次使用。
1.查看并开启查询缓存
缓存大小为0,不能缓存

没有设置缓存之前,每次查询都消耗2多秒时间:
现在就开启缓存,设置缓存空间大小为64M:
开启缓存后,查询速度有明显的提升:
2.缓存失效
数据表或数据有变动(增加、减少、修改),会引起缓存失效。
2.什么情况下不会使用缓存
sql语句有变动的信息,就不使用缓存
例如:时间信息、随机数
有时间信息的不给缓存:
有随机数的也不给缓存:
3. 生成多个缓存
注意:获得相同结果的sql语句,如果有空格、大小写等内容不同,也会分别进行缓存
相同结果不同样子的sql语句会分别缓存:
4. 不进行缓存
针对特殊语句不需要缓存:
5. 查看缓存空间状态
缓存被使用后,空间有变小:























 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









