










01-Hadoop-HA-概述:
HA
1)所谓HA(High Available),即高可用(7*24小时不中断服务)。
2)实现高可用最关键的策略是消除单点故障。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA。
3)Hadoop2.0之前,在HDFS集群中NameNode存在单点故障(SPOF)。通过双NameNode消除单点故障
4)NameNode主要在以下两个方面影响HDFS集群
NameNode机器发生意外,如宕机,集群将无法使用,直到管理员重启
NameNode机器需要升级,包括软件、硬件升级,此时集群也将无法使用
HDFS HA功能通过配置Active(活跃)/Standby(备用)两个NameNodes实现在集群中对NameNode的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
**HDFS-**HA工作要点
- 元数据管理方式需要改变
内存中各自保存一份元数据;
Edits日志只有Active状态的NameNode节点可以做写操作;
两个NameNode都可以读取Edits;
共享的Edits放在一个共享存储中管理(qjournal和NFS两个主流实现);
- 需要一个状态管理功能模块
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要防止brain split现象的发生。
-
必须保证两个NameNode之间能够ssh无密码登录
-
隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
HDFS-HA 集群配置
1 环境准备
-
修改 IP
-
修改主机名及主机名和 IP 地址的映射
-
关闭防火墙
-
ssh 免密登录
-
安装 JDK,配置环境变量等
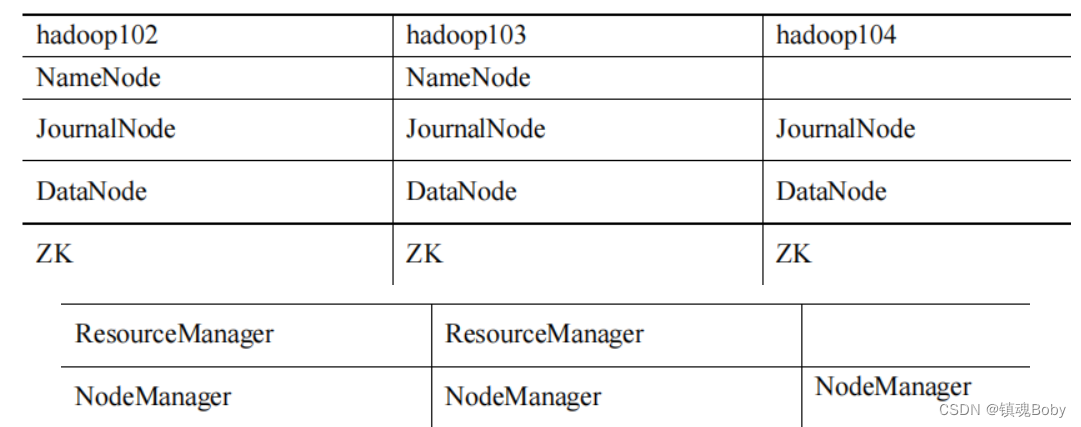
2 规划集群
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l45oCxrk-1669214516302)(png/1626233058611.png)]](https://img-blog.csdnimg.cn/a6661b79032d4d7fb20e589100bc44b1.png)
配置 Zookeeper 集群
- 集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上部署 Zookeeper。
- 解压安装
(1)解压 Zookeeper 安装包到/opt/module/目录下
[root@hadoop102 software]$ tar -zxvf zookeeper- 3.4.10.tar.gz -C /opt/module/
(2)在/opt/module/zookeeper-3.4.10/这个目录下创建 zkData mkdir -p zkData
(3)重命名/opt/module/zookeeper-3.4.10/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
mv zoo_sample.cfg zoo.cfg
- 配置 zoo.cfg 文件
(1)具体配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(2)配置参数解读
Server.A=B:C:D。
A 是一个数字,表示这个是第几号服务器;
B 是这个服务器的 IP 地址;
C 是这个服务器与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的
Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据
就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比
较从而判断到底是哪个 server。
- 集群操作
(1)在/opt/module/zookeeper-3.4.10/zkData 目录下创建一个 myid 的文件
touch myid
添加 myid 文件,注意一定要在 linux 里面创建,在 notepad++里面很可能乱码
(2)编辑 myid 文件
vi myid
在文件中添加与 server 对应的编号:如 2
(3)拷贝配置好的 zookeeper 到其他机器上 ,或者分发,看zk相关
scp -r zookeeper-3.4.10/ root@hadoop103.atguigu.com:/opt/app/
scp -r zookeeper-3.4.10/ root@hadoop104.atguigu.com:/opt/app/
并分别修改 myid 文件中内容为 3、4
(4)分别启动 zookeeper
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop104 zookeeper-3.4.10]# bin/zkServer.sh start
(5)查看状态
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status
[root@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
手动故障转移配置
修改hdfs-site.xml如下
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>192.168.1.102:9000</value>
</property>
<!-- nn2 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>192.168.1.103:9000</value>
</property>
<!-- nn1 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>192.168.1.102:50070</value>
</property>
<!-- nn2 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>192.168.1.103:50070</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.1.102:8485;192.168.1.103:8485;192.168.1.104:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要 ssh 无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明 journalnode 服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-3.1.4/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active 配置失败自动切换实现方
式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置core-site.xml
<configuration>
<!-- 把两个 NameNode)的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.4/data/tmp</value>
</property>
</configuration>
rm -rf data logs
分发 xsync HA/
手动故障转移测试
启用journalnode,因为namenode格式化后产生的image没有地方写。
启动 HDFS-HA 集群
-
在各个 JournalNode 节点上,输入以下命令启动 journalnode 服务
[root@hadoop102 hadoop-3.1.4]# bin/hdfs --daemon start journalnode
[root@hadoop103 hadoop-3.1.4]# bin/hdfs --daemon start journalnode
[root@hadoop104 hadoop-3.1.4]# bin/hdfs --daemon start journalnode
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V86SM8Kf-1669214516303)(png/1626178356190.png)]](https://img-blog.csdnimg.cn/332fd89517044856a0c46aec965d582a.png)
-
在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
- 在[nn2]上,同步 nn1 的元数据信息
bin/hdfs namenode -bootstrapStandby
- 启动[nn2]
sbin/hadoop-daemon.sh start namenode
5.查看 web 页面显示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wVE5CCMf-1669214516304)(png/1626233234569.png)]](https://img-blog.csdnimg.cn/4cf4868c8c9b49b984eeca543fae95d8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NLc86IkL-1669214516304)(png/1626233246328.png)]](https://img-blog.csdnimg.cn/ed393e9e69334e2292aee94f8bd93530.png)
-
在[nn1]上,启动所有 datanode
sbin/hadoop-daemons.sh start datanode
-
将[nn1]切换为 Active
bin/hdfs haadmin -transitionToActive nn1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5SLLP7t0-1669214516305)(png/1626233356911.png)]](https://img-blog.csdnimg.cn/0e1bf46d098248aea39c6c69d8c76261.png)
-
查看是否 Active
bin/hdfs haadmin -getServiceState nn1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yFIrhWns-1669214516305)(png/1626233403783.png)]](https://img-blog.csdnimg.cn/08ebf3fa12b641709bb4525c80abf2ab.png)
HDFS-HA 自动故障转移工作机制
前面使用命令 hdfs haadmin -failover 手动进行故障转移,在该模式下,即使现役 NameNode 已经失效,系统也不会自动从现役 NameNode 转移到待机 NameNode,
如何配置部署 HA 自动进行故障转移。自动故障转移为 HDFS 部署增加了两个新组件: ZooKeeper 和 ZKFailoverController(ZKFC)进程,如图 所示。ZooKeeper 是维护少量 协调数据,通知客户端这些数据的改变和监视客户端故障的高可用服务。HA 的自动故障转 移依赖于 ZooKeeper 的以下功能:
1)故障检测:集群中的每个 NameNode 在 ZooKeeper 中维护了一个持久会话,如果机器崩溃,ZooKeeper 中的会话将终止,ZooKeeper 通知另一个 NameNode 需要触发故障转 移。
2)现役 NameNode **选择:**ZooKeeper 提供了一个简单的机制用于唯一的选择一个节点为 active 状态。如果目前现役 NameNode 崩溃,另一个节点可能从 ZooKeeper 获得特殊的排外锁以表明它应该成为现役NameNode。
ZKFC(hadoop进程) 是自动故障转移中的另一个新组件,是 ZooKeeper 的客户端,也监视和管理 NameNode 的状态。每个运行 NameNode 的主机也运行了一个 ZKFC 进程,ZKFC 负责:
1)健康监测:ZKFC 使用一个健康检查命令定期地 ping 与之在相同主机的 NameNode, 只要该 NameNode 及时地回复健康状态,ZKFC 认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
2)ZooKeeper 会话管理:当本地 NameNode 是健康的,ZKFC 保持一个在 ZooKeeper中打开的会话。如果本地 NameNode 处于 active 状态,ZKFC 也保持一个特殊的 znode 锁, 该锁使用了 ZooKeeper 对短暂节点的支持,如果会话终止,锁节点将自动删除。
3)基于 ZooKeeper 的选择:如果本地 NameNode 是健康的,且 ZKFC 发现没有其它的 节点当前持有 znode 锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运 行故障转移进程以使它的本地 NameNode 为 Active。故障转移进程与前面描述的手动故障转 移相似,首先如果必要保护之前的现役 NameNode,然后本地 NameNode 转换为 Active 状态。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BMW7hwv8-1669214516305)(png/1626250193289.png)]](https://img-blog.csdnimg.cn/6fa46c91542e47958d2ffa9f909810b2.png)
配置 HDFS-HA 自动故障转移
- 具体配置
(1)在 hdfs-site.xml 中增加
<!--开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)在 core-site.xml 文件中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.1.102:2181,192.168.1.103:2181,192.168.1.104:2181</value>
</property>
分发
启动zk集群
启动
(1)关闭所有 HDFS 服务:
sbin/stop-dfs.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cgDd0nEI-1669214516306)(png/1626260752662.png)]](https://img-blog.csdnimg.cn/663fb6f943774bf290f225c508483bd0.png)
(2)启动 Zookeeper 集群:
bin/zkServer.sh start
(3)初始化 HA 在 Zookeeper 中状态,启动后查看的zk信息。(bin/zkCli.sh):
bin/hdfs zkfc -formatZK
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EJNJ73Z9-1669214516307)(png/1626261008816.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kBtcXw3s-1669214516308)(png/1626260923343.png)]
(4)启动 HDFS 服务:
sbin/start-dfs.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c6fDiqyG-1669214516308)(png/1626261079694.png)]](https://img-blog.csdnimg.cn/a0032f9f83e5472ca35c1b2509a4c754.png)
(5)在各个 NameNode 节点上启动 DFSZK Failover Controller,先在哪台机器启动,哪
个机器的 NameNode 就是 Active NameNode
sbin/hadoop-daemon.sh start zkfc
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pXRUwr2B-1669214516308)(png/1626267471484.png)]](https://img-blog.csdnimg.cn/b873f49083174923bc706ff0b7842cf0.png)
测试原始活跃和备份
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PmTgK62i-1669214516309)(png/1626267523032.png)]](https://img-blog.csdnimg.cn/b8405f8edfe24ce0a7b538bff4082108.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8CYypvVG-1669214516309)(png/1626267495513.png)]](https://img-blog.csdnimg.cn/c53ea51bd47f48dbb526e0d33f9da851.png)
干掉102上面的namenode,103变为active
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UxaVxehd-1669214516310)(png/1626267676317.png)]](https://img-blog.csdnimg.cn/8c0b56b133a54857ad878f4df21f58b0.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9lMCFDU4-1669214516310)(png/1626267664862.png)]](https://img-blog.csdnimg.cn/89669cfe29cb4cbe8316afecccf8cbd0.png)
YARN-HA 工作机制
- 官方文档:
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
配置 YARN-HA 集群
具体配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用 resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台 resourcemanager 的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>192.168.1.102</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>192.168.1.103</value>
</property>
<!--指定 zookeeper 集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>192.168.1.102:2181,192.168.1.103:2181,192.168.1.104:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定 resourcemanager 的状态信息存储在 zookeeper 集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
同步更新其他节点的配置信息
启动 hdfs (接上hadoop此处略过,第一次启动需要,非第一次不需要,格式化过程,第一次)
(1)在各个 JournalNode 节点上,输入以下命令启动 journalnode 服务:
sbin/hadoop-daemon.sh start journalnode
(2)在[nn1]上,对其进行格式化,并启动:
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
(3)在[nn2]上,同步 nn1 的元数据信息:
bin/hdfs namenode -bootstrapStandby
(4)启动[nn2]:
sbin/hadoop-daemon.sh start namenode
(5)启动所有 DataNode
sbin/hadoop-daemons.sh start datanode
(6)将[nn1]切换为 Active
bin/hdfs haadmin -transitionToActive nn1
启动 YARN
(1)在 hadoop102 中执行:
sbin/start-yarn.sh
(2)在 hadoop103 中执行:
sbin/yarn-daemon.sh start resourcemanager
(3)查看服务状态,如图 3-24 所示
bin/yarn rmadmin -getServiceState rm1
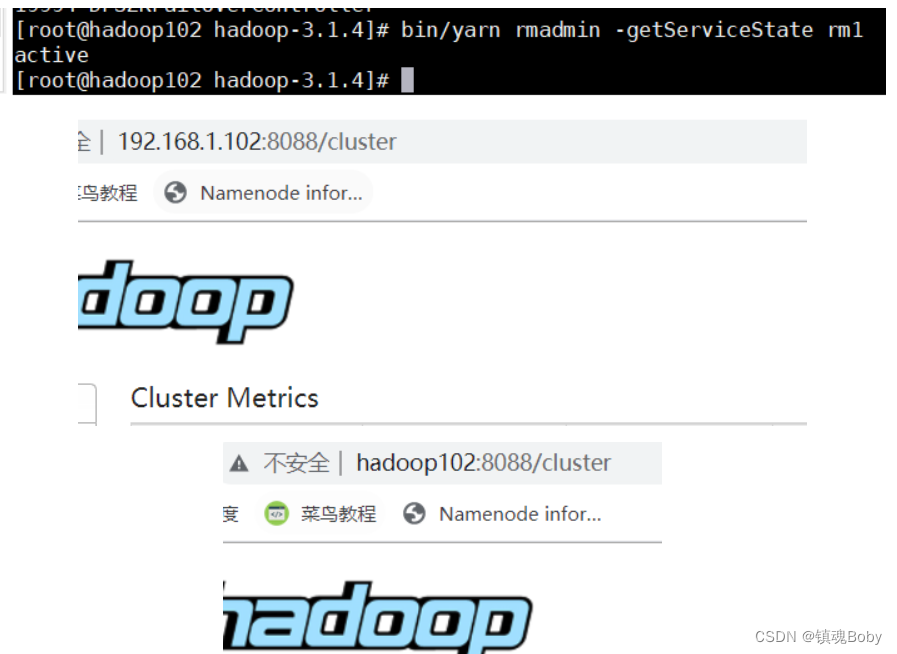
关闭yarn sbin/stop-yarn.sh
关闭hadoop myhadoop.sh stop
关闭zk myzk.sh stop
关闭journalnode
[root@hadoop102 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
[root@hadoop103 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
[root@hadoop104 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
关闭zkfc
h start resourcemanager
(3)查看服务状态,如图 3-24 所示
bin/yarn rmadmin -getServiceState rm1
[外链图片转存中…(img-zEjl14Rj-1669214516313)]
[外链图片转存中…(img-bC1auWrB-1669214516314)]
[外链图片转存中…(img-w1qJKsJC-1669214516314)]
关闭yarn sbin/stop-yarn.sh
关闭hadoop myhadoop.sh stop
关闭zk myzk.sh stop
关闭journalnode
[root@hadoop102 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
[root@hadoop103 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
[root@hadoop104 hadoop-3.1.4]# bin/hdfs --daemon stop journalnode
关闭zkfc
[root@hadoop104 hadoop-3.1.4]# sbin/hadoop-daemon.sh stop zkfc















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









