







一、概述
之前的博客写了搭建hadoop集群环境,今天写一写搭建高可用(HA)环境。Hadoop-HA模式大致分为两个(个人在学习中的理解):
- namenode 高可用
- yarn 高可用
1、Namenode HA
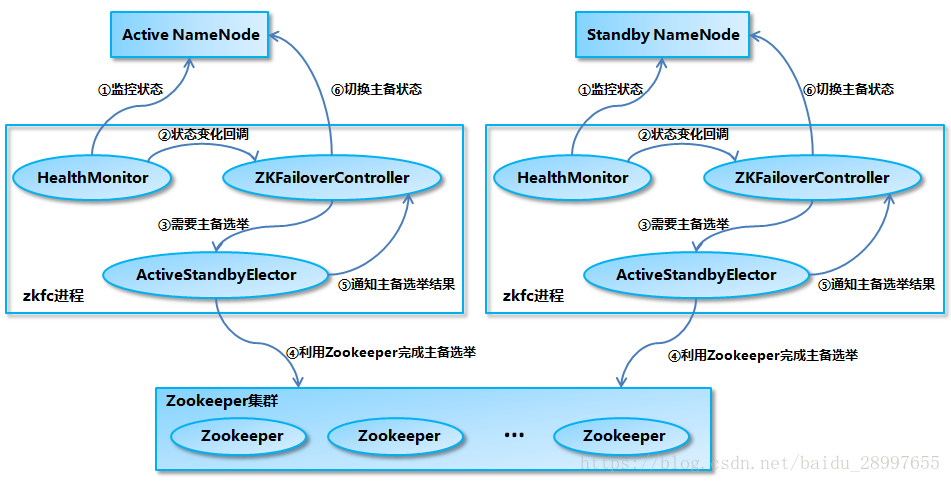
Namenode在HDFS中是一个非常重要的组件,相当于HDFS文件系统的心脏,在显示分布式集群环境中,还是会有可能出现Namenode的崩溃或各种意外。所以,高可用模式就体现出作用了。
namenode HA配置大概流程(个人理解):
- 在启动namenode之前,需要启动hadoop2.x中新引入的(QJM)Quorum Journal Manager,QJM主要用来管理namenode之间的数据同步,当active namenode数据更新时会传递给QJM,QJM在所有的namenode之间同步,最后QJM将active namenode 更新的数据同步到了standby namenode中。
- 启动多个namenode时,并配置namenode的主机地址,还要配置隔离机制,因为容易出现SB(split-brain)状况,所谓的sb状况意思就是当多个namenode正常状态时,一台active,多台standby。如果某段时间因为网络等非namenode自身关系导致namenode间交流阻断了,这样容易出现多台active的设备,容易抢占资源等。
- 引入zookeeper来对namenode进行监听,因为在一般情况下,active 的namenode崩溃了的话,需要人工切换standby Namenode为active。非常不人性化。通过zookeeper可以监听多个namenode,当active namenode崩溃的话,zookeeper监听到后马上通知zookeeper的leader进行主备选举,在standby namenode中选举出一台,并将它置为active模式替换崩溃的namenode。
2、Yarn HA
Yarn HA 的作用我认为和Namenode HA差不多,都是用来防止心脏组件出意外导致整个集群崩溃。
Yarn HA 配置大概流程(个人理解):
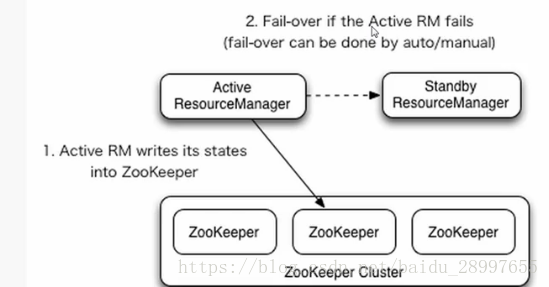
- 通过在yarn-site.xml中配置对zookeeper的支持后,在ResourceManager启动的时候,Active ResourceManager会将自己的状态信息写入到zookeeper集群中。
- 启动其他的ResourceManager后,都会在standby状态。
- 当active ResourceManager 意外停止时,zookeeper就会选举出一个standby 状态的ResourceManager,然后将原来ResourceManager的状态信息写入到standby ResourceManager中,最后将standby ResourceManager置为active状态,完成了主备切换。
二、Namenode HA 搭建
在之前的博客中,Hadoop分布式环境搭建有教程,zookeeper集群搭建也有教程,这里是在这两个要求的前提下进行的。
1、配置文件的修改
观看官方文档的说明:点击
QJM(Quorum Journal Manager)配置
修改hdfs-site.xml:
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点名称 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>machine1.example.com:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>machine2.example.com:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>machine2.example.com:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>machine2.example.com:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1.example.com:8485;node2.example.com:8485;node3.example.com:8485/mycluster</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/exampleuser/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/path/to/journal/node/local/data</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
修改core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.6.5/data</value>
</property>
Automatic Failover(自动主备切换)配置
hdfs-site.xml添加:
!<--开启Automatic Failover模式-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
core-site.xml添加:
!<--zookeeper集群地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181</value>
</property>
将配置文件分发到三台设备上!
2、启动测试
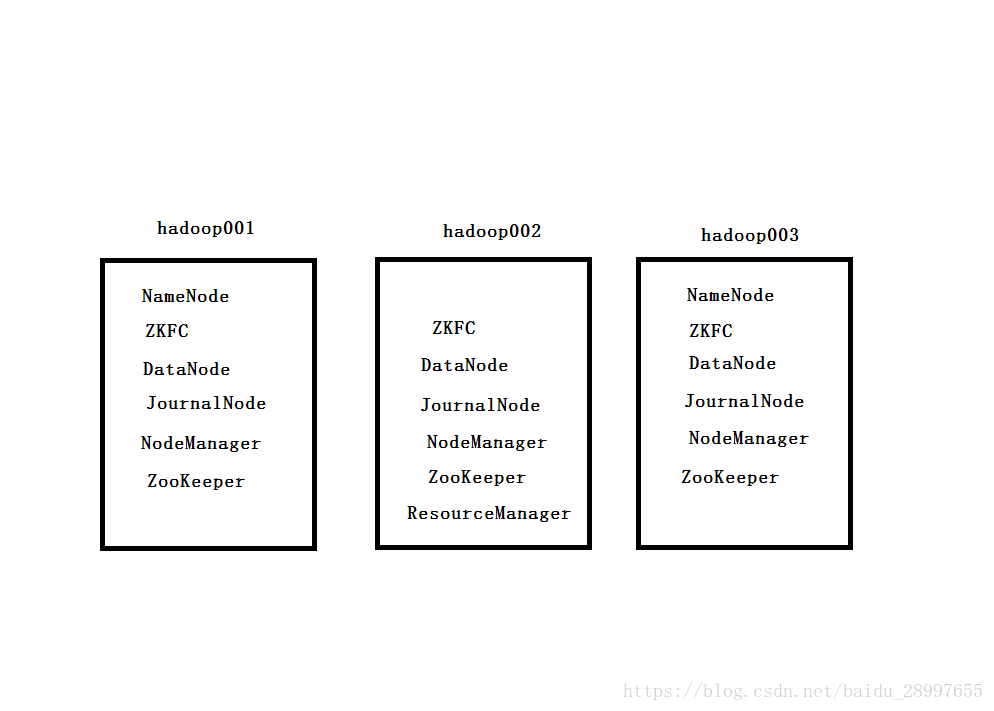
集群框架如图:
上面是看官网修改的配置,我先贴出自己的和之前写的博客不同配置的几个文件:
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.6.5/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>2</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop001:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop003:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop001:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop003:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop001:8485;hadoop002:8485;hadoop003:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-2.6.5/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- automatic failover-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
启动步骤:
-
首先启动zookeeper集群。
#先启动三台zookeeper集群:
[root@hadoop001 bin]# pwd
/opt/module/zookeeper-3.4.10/bin
[root@hadoop001 bin]# ./zkServer.sh start[root@hadoop002 bin]# pwd
/opt/module/zookeeper-3.4.10/bin
[root@hadoop002 bin]# ./zkServer.sh start[root@hadoop003 bin]# pwd
/opt/module/zookeeper-3.4.10/bin
[root@hadoop003 bin]# ./zkServer.sh start#分别查看三台状态
[root@hadoop001 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower[root@hadoop002 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: leader[root@hadoop003 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/…/conf/zoo.cfg
Mode: follower启动成功
-
启动QJM,
[root@hadoop001 hadoop-2.6.5]# sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-journalnode-hadoop001.out
[root@hadoop001 hadoop-2.6.5]# jps
5873 JournalNode
5511 QuorumPeerMain
5911 Jps[root@hadoop003 hadoop-2.6.5]# sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-journalnode-hadoop003.out
[root@hadoop003 hadoop-2.6.5]# jps
5344 JournalNode
5382 Jps
5021 QuorumPeerMain -
格式化NameNode并启动,也是只需要启动hadoop001和hadoop003(注意:先格式化一台namenode,然后另一台namenode同步第一台namenode,如果两台都格式化就会有问题)
第一个namenode格式化
[root@hadoop001 hadoop-2.6.5]# bin/hdfs namenode -format
格式化之后启动namenode
[root@hadoop001 hadoop-2.6.5]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-namenode-hadoop001.out
[root@hadoop001 hadoop-2.6.5]# jps
5511 QuorumPeerMain
7000 Jps
6591 JournalNode
6895 NameNode第二个namenode同步第一个
[root@hadoop003 hadoop-2.6.5]# bin/hdfs namenode -bootstrapStandby
启动第二个namenode
[root@hadoop003 hadoop-2.6.5]# sbin/hadoop-daemon.sh start namenode
-
查看namenode(如下图,都启动成功,只是都在standby状态)
-
手动切换nn1为激活状态
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -transitionToActive nn1
Automatic failover is enabled for NameNode at hadoop003/192.168.170.133:8020
Refusing to manually manage HA state, since it may cause
a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the forcemanual flag.这里需要强制切换
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -transitionToActive --forcemanual nn1
You have specified the forcemanual flag. This flag is dangerous, as it can induce a split-brain scenario that WILL CORRUPT your HDFS namespace, possibly irrecoverably.It is recommended not to use this flag, but instead to shut down the cluster and disable automatic failover if you prefer to manually manage your HA state.
You may abort safely by answering ‘n’ or hitting ^C now.
Are you sure you want to continue? (Y or N) y
18/08/21 16:12:59 WARN ha.HAAdmin: Proceeding with manual HA state management even though
automatic failover is enabled for NameNode at hadoop003/192.168.170.133:8020
18/08/21 16:13:00 WARN ha.HAAdmin: Proceeding with manual HA state management even though
automatic failover is enabled for NameNode at hadoop001/192.168.170.131:8020可以看到nn2已经激活,nn1在standby状态
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn1
standby
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn2
active -
在zookeeper上配置故障自动转移节点
[root@hadoop001 hadoop-2.6.5]# bin/hdfs zkfc -formatZK
[zk: localhost:2181(CONNECTED) 5] ls /
[zookeeper, hadoop-ha]可以看到zookeeper上已经有了hadoop-ha节点了
-
启动集群
[root@hadoop001 hadoop-2.6.5]# sbin/start-dfs.sh
Starting namenodes on [hadoop001 hadoop003]
hadoop001: namenode running as process 6895. Stop it first.
hadoop003: namenode running as process 6103. Stop it first.
hadoop003: starting datanode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-datanode-hadoop003.out
hadoop001: starting datanode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-datanode-hadoop001.out
hadoop002: starting datanode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-datanode-hadoop002.out
Starting journal nodes [hadoop001 hadoop002 hadoop003]
hadoop001: journalnode running as process 6591. Stop it first.
hadoop003: journalnode running as process 5814. Stop it first.
hadoop002: journalnode running as process 5450. Stop it first.
Starting ZK Failover Controllers on NN hosts [hadoop001 hadoop003]
hadoop001: starting zkfc, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-zkfc-hadoop001.out
hadoop003: starting zkfc, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-zkfc-hadoop003.out
[root@hadoop001 hadoop-2.6.5]# jps
8114 DFSZKFailoverController
7478 ZooKeeperMain
5511 QuorumPeerMain
8169 Jps
7803 DataNode
6591 JournalNode
6895 NameNode在三台设备上分别jps一下,都启动了
-
接下来kill掉一个nn1,看看zookeeper是否会自动切换nn2
[root@hadoop003 hadoop-2.6.5]# jps
6708 DFSZKFailoverController
6549 DataNode
5814 JournalNode
6103 NameNode
6825 Jps
5021 QuorumPeerMain杀掉namenode进程
[root@hadoop003 hadoop-2.6.5]# kill -9 6103
#查看nn2状态,连接不上了
[root@hadoop003 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn2
18/08/21 16:28:52 INFO ipc.Client: Retrying connect to server: hadoop003/192.168.170.133:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hadoop003/192.168.170.133 to hadoop003:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused查看nn1状态,已经激活了
[root@hadoop003 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn1
active#重新启动同步nn1,并启动nn2
[root@hadoop003 hadoop-2.6.5]# bin/hdfs namenode -bootstrapStandby
[root@hadoop003 hadoop-2.6.5]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.6.5/logs/hadoop-root-namenode-hadoop003.out
[root@hadoop003 hadoop-2.6.5]# jps
7169 Jps
6708 DFSZKFailoverController
6549 DataNode
5814 JournalNode
7084 NameNode
5021 QuorumPeerMain接下来杀掉nn1,看看会不会自动激活nn2
[root@hadoop001 hadoop-2.6.5]# jps
8114 DFSZKFailoverController
8418 Jps
7478 ZooKeeperMain
5511 QuorumPeerMain
7803 DataNode
6591 JournalNode
6895 NameNode
[root@hadoop001 hadoop-2.6.5]# kill -9 6895
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn1
18/08/21 16:32:11 INFO ipc.Client: Retrying connect to server: hadoop001/192.168.170.131:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hadoop001/192.168.170.131 to hadoop001:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@hadoop001 hadoop-2.6.5]# bin/hdfs haadmin -getServiceState nn2
active
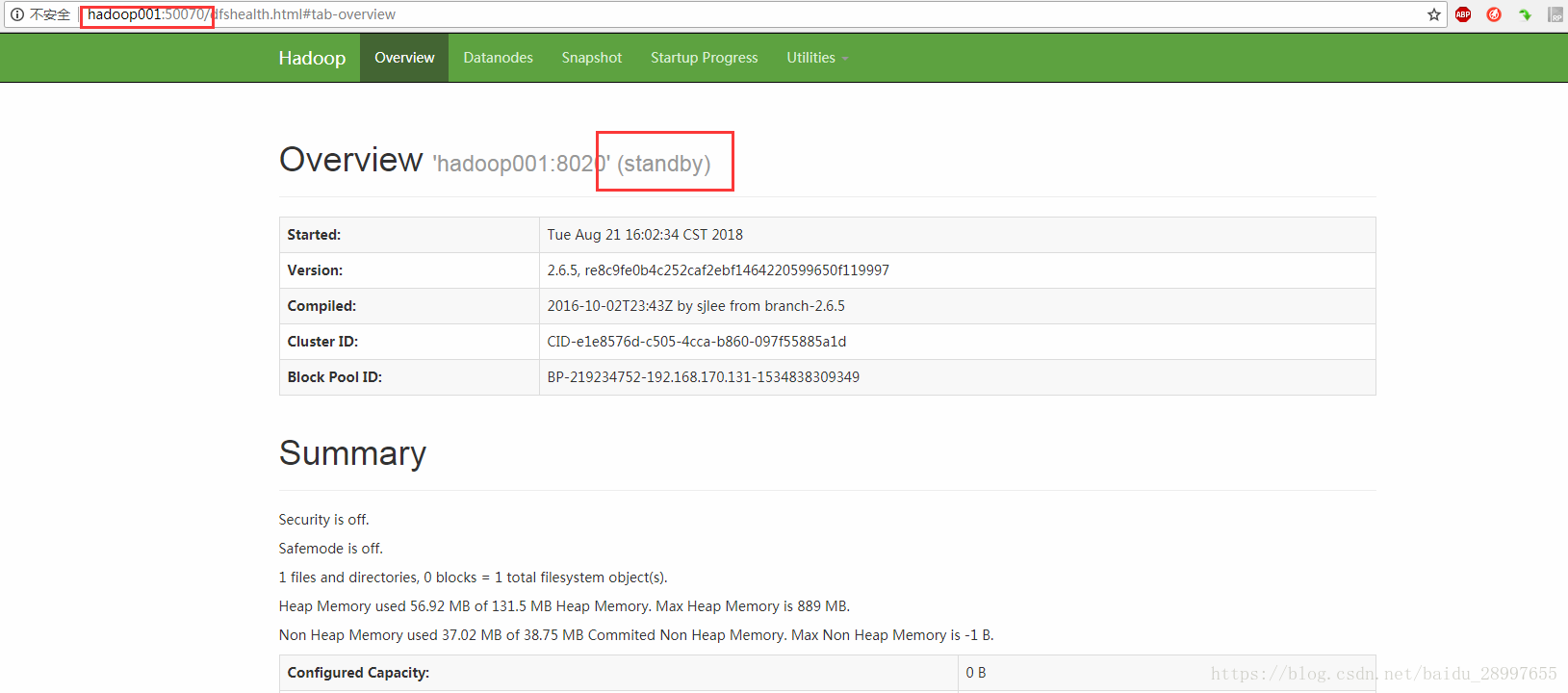
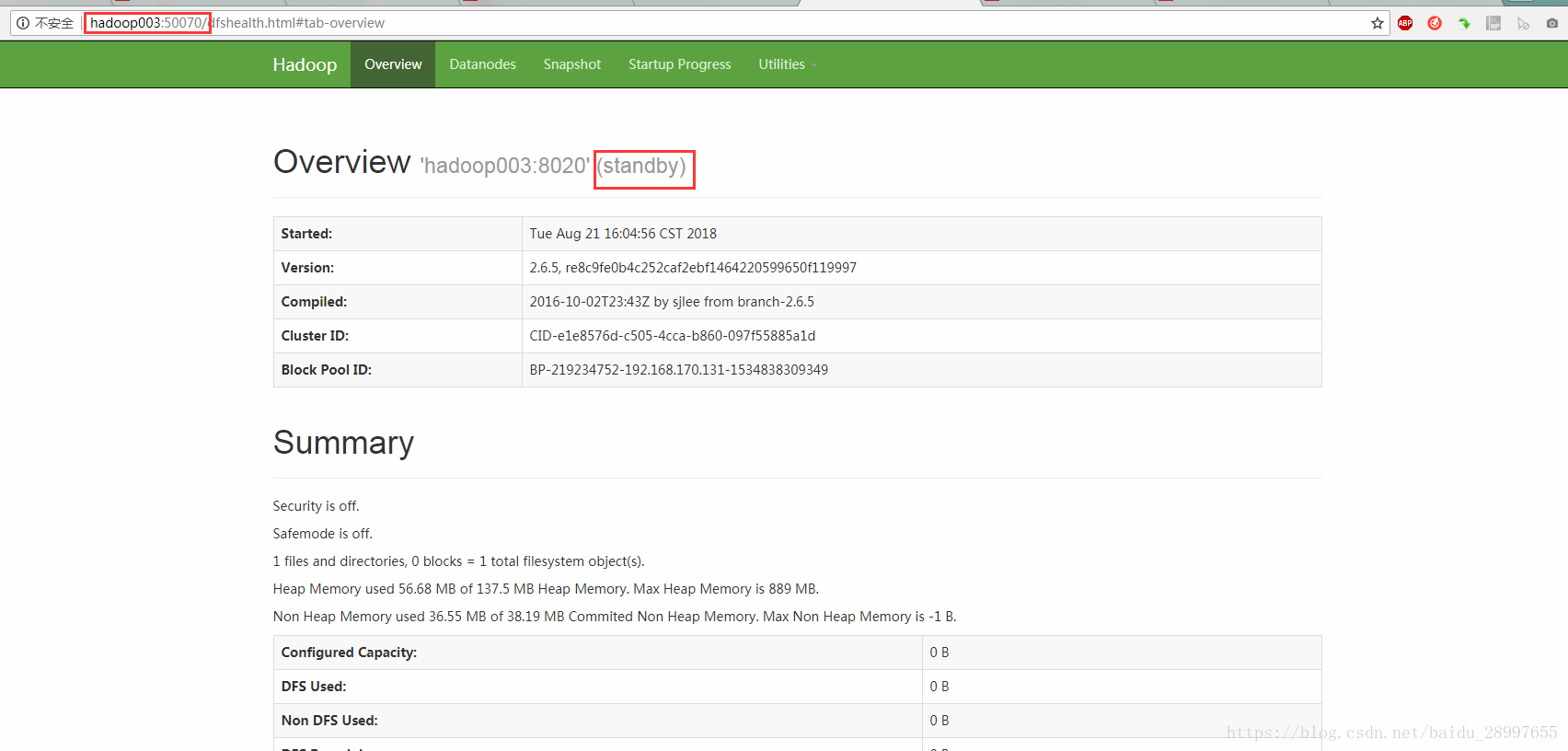
NameNode-HA搭建完成!
三、Yarn HA 搭建
查看apache官方文档:
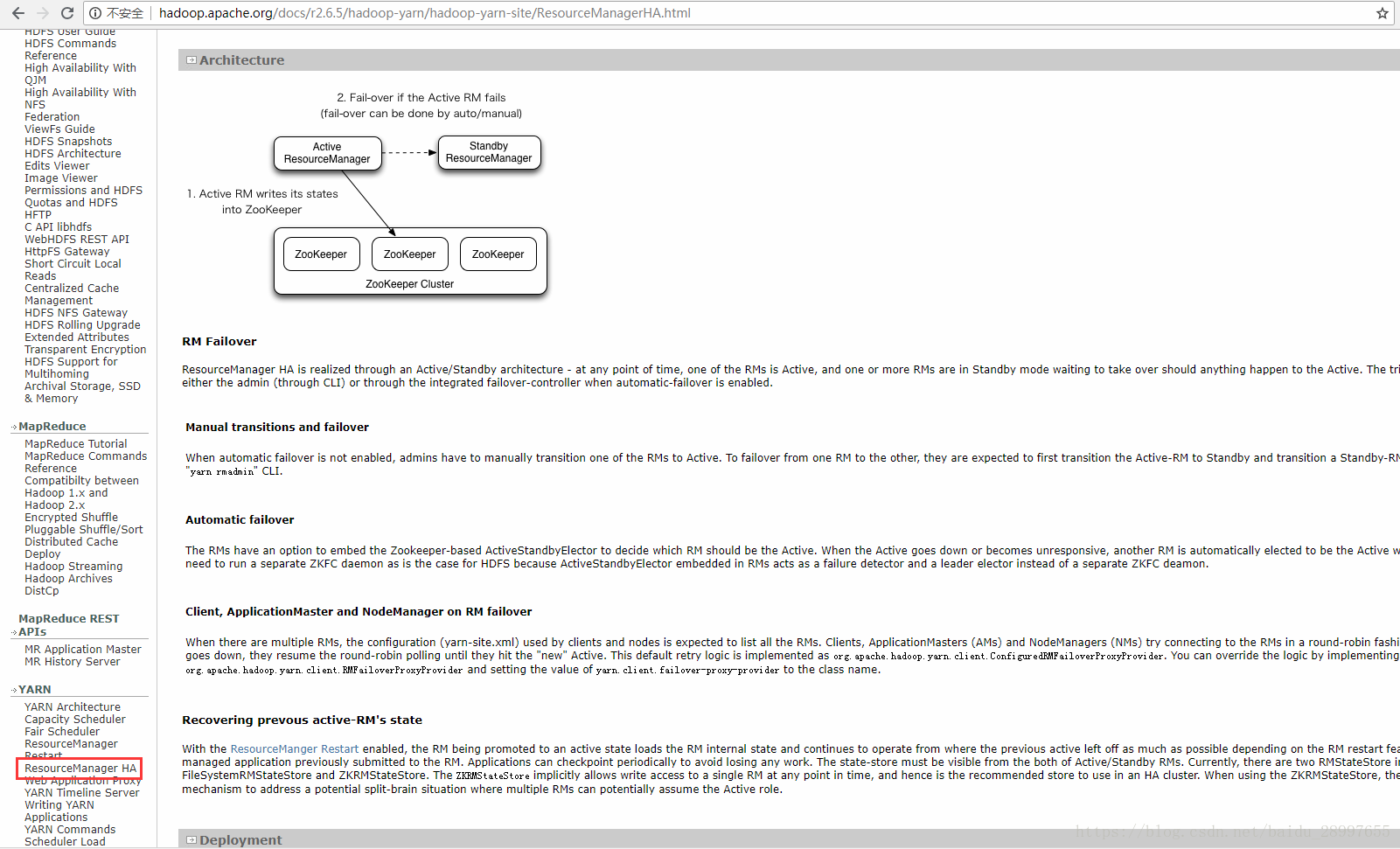
1、配置文件的修改
修改yarn-site.xml:
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
将配置文件分发到3台服务器上!
2.启动测试
我把我这次修改的yarn-site.xml发出来:
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--任务历史服务-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop002</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop003</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
-
启动yarn,由于hadoop002是resourceManager,所以在hadoop002上启动
[root@hadoop002 hadoop-2.6.5]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-resourcemanager-hadoop002.out
hadoop002: starting nodemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-nodemanager-hadoop002.out
hadoop001: starting nodemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-nodemanager-hadoop001.out
hadoop003: starting nodemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-nodemanager-hadoop003.out
[root@hadoop002 hadoop-2.6.5]# jps
4898 QuorumPeerMain
7352 ResourceManager
5801 DataNode
7449 NodeManager
5450 JournalNode
7482 Jps[root@hadoop001 hadoop-2.6.5]# jps
8114 DFSZKFailoverController
9508 Jps
7478 ZooKeeperMain
5511 QuorumPeerMain
7803 DataNode
9389 NodeManager
6591 JournalNode[root@hadoop003 hadoop-2.6.5]# jps
6708 DFSZKFailoverController
6549 DataNode
5814 JournalNode
7961 Jps
7084 NameNode
7932 NodeManager
5021 QuorumPeerMain -
在hadoop003上启动resourceManager
[root@hadoop003 hadoop-2.6.5]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-resourcemanager-hadoop003.out
[root@hadoop003 hadoop-2.6.5]# jps
6708 DFSZKFailoverController
6549 DataNode
5814 JournalNode
8105 ResourceManager
7084 NameNode
7932 NodeManager
8140 Jps
5021 QuorumPeerMain -
查看两个resourceManager的状态
[root@hadoop003 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm1
active
[root@hadoop003 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm2
standby -
杀掉rm1,看看是否会自动切换rm2
[root@hadoop002 hadoop-2.6.5]# jps
4898 QuorumPeerMain
7352 ResourceManager
5801 DataNode
7449 NodeManager
5450 JournalNode
7854 Jpskill掉rm1
[root@hadoop002 hadoop-2.6.5]# kill -9 7352
查看rm1状态,已经离线了
[root@hadoop002 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm1
18/08/21 17:22:31 INFO ipc.Client: Retrying connect to server: hadoop002/192.168.170.132:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hadoop002/192.168.170.132 to hadoop002:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused查看rm2状态,激活了
[root@hadoop002 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm2
active接下来重启rm1,kill掉rm2,看看是否会切换
启动hadoop002的rm1
[root@hadoop002 hadoop-2.6.5]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/hadoop-2.6.5/logs/yarn-root-resourcemanager-hadoop002.out
[root@hadoop002 hadoop-2.6.5]# jps
4898 QuorumPeerMain
5801 DataNode
7449 NodeManager
5450 JournalNode
8091 Jps
8046 ResourceManagerkill hadoop003的rm2
[root@hadoop003 hadoop-2.6.5]# jps
6708 DFSZKFailoverController
6549 DataNode
5814 JournalNode
8503 Jps
8105 ResourceManager
7084 NameNode
7932 NodeManager
5021 QuorumPeerMain
[root@hadoop003 hadoop-2.6.5]# kill 8105查看rm1和rm2的状态
[root@hadoop003 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm1
active
[root@hadoop003 hadoop-2.6.5]# bin/yarn rmadmin -getServiceState rm2
18/08/21 17:26:23 INFO ipc.Client: Retrying connect to server: hadoop003/192.168.170.133:8033. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From hadoop003/192.168.170.133 to hadoop003:8033 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused可以看到,已经切换成功了
Yarn-HA搭建成功!

















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











