









14-hbase-高级-详细架构:
读写,合并切分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-buEM5oJb-1669555327275)(png/1618845299093.png)]](https://img-blog.csdnimg.cn/be87f1518a4d40ba813a09c6cc04c605.png)
1)StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有
一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
2)MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好
序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
3)WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的
概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件
中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重
建。
写流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uBHDQCTV-1669555327276)(png/1618846348625.png)]](https://img-blog.csdnimg.cn/87826475d7184946aac2ea58ca61b7da.png)
写流程:
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
读流程
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将
查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不
同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到
Block Cache。
6)将合并后的最终结果返回给客户端。
查看zk下面的hbase信息
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r59MfhcL-1669555327277)(png/1618927216925.png)]](https://img-blog.csdnimg.cn/b2724f625e1a47228da270cc7c36e1c1.png)
其中系统表meta有104服务器管理,stu表同理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ERaL6ODC-1669555327278)(png/1618927228908.png)]](https://img-blog.csdnimg.cn/97c09245cd1a4407872b3d905be4b9a0.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vNuTlw3s-1669555327278)(png/1618927254848.png)]](https://img-blog.csdnimg.cn/8b0a679da4d244569dcf6ee7ae8d385d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1w9QIfrh-1669555327279)(png/1618927281856.png)]](https://img-blog.csdnimg.cn/72a17bb112ac4252bdebdc1a54a8198e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uYaOtWpD-1669555327279)(png/1618930470408.png)]](https://img-blog.csdnimg.cn/6cb441898ab140bf8a073c76c8bad13b.png)
Flush
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NuXJs77f-1669555327280)(png/1619014552181.png)]](https://img-blog.csdnimg.cn/9db3acff998d42169ae131b853a18aa3.png)
MemStore 刷写时机:
1.当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),
其所在 region 的所有 memstore 都会刷写。
当 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M)
hbase.hregion.memstore.block.multiplier(默认值 4)
时,会阻止继续往该 memstore 写数据。
2.当 region server 中 memstore 的总大小达到
java_heapsize
hbase.regionserver.global.memstore.size(默认值 0.4)
hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server
中所有 memstore 的总大小减小到上述值以下。
当 region server 中 memstore 的总大小达到
java_heapsize\hbase.regionserver.global.memstore.size(默认值 0.4)
时,会阻止继续往所有的 memstore 写数据。
- 到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行
配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
4.当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进
行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,
现无需手动设置,最大值为 32)
创建表以及数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hsL6zo0u-1669555327281)(png/1619016256511.png)]](https://img-blog.csdnimg.cn/89186b57b0be40a88d6027eb925a9de9.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pUdSRqNf-1669555327281)(png/1619016263709.png)]](https://img-blog.csdnimg.cn/8899b506c2ad48dc9c2d311a456408bc.png)
手动刷新
hbase(main):006:0> flush ‘stu3’
0 row(s) in 2.4690 seconds
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ajgRTY2t-1669555327282)(png/1619016305348.png)]](https://img-blog.csdnimg.cn/112b592f97d34f0fac08e267fcfc0a94.png)
合并
StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)
和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。
为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction
会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期
和删除的数据。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nBNIKQWI-1669555327283)(png/1619098651331.png)]](https://img-blog.csdnimg.cn/5de3b529fe2d4c748129f5eb39e1c601.png)
数据删除时间
1、flush和大合并的时候回删除无用数据
hbase(main):002:0> create 'stu4','info'
0 row(s) in 35.0850 seconds
=> Hbase::Table - stu4
hbase(main):003:0> put 'stu4','1001','info:name','yangyang'
0 row(s) in 2.0410 seconds
hbase(main):004:0> put 'stu4','1001','info:name','yangyang02'
0 row(s) in 0.0650 seconds
hbase(main):006:0> scan 'stu4'
ROW COLUMN+CELL
1001 column=info:name, timestamp=1619099165889, value=yangyang02
1 row(s) in 0.0250 seconds
hbase(main):007:0> scan 'stu4',{RAW=>true,VERSIONS=>10}
ROW COLUMN+CELL
1001 column=info:name, timestamp=1619099165889, value=yangyang02
1001 column=info:name, timestamp=1619099159127, value=yangyang
1 row(s) in 0.0200 seconds
hbase(main):008:0> flush 'stu4'
0 row(s) in 6.9270 seconds
hbase(main):009:0> scan 'stu4',{RAW=>true,VERSIONS=>10}
ROW COLUMN+CELL
1001 column=info:name, timestamp=1619099165889, value=yangyang02
1 row(s) in 0.0550 seconds
compact前hbase(main):018:0> compact ‘stu4’
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jxxpKxXv-1669555327283)(png/1619099598192.png)]](https://img-blog.csdnimg.cn/0027294e055b45d78148832c474ced44.png)
后
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFRZ4iJ1-1669555327284)(png/1619099617842.png)]](https://img-blog.csdnimg.cn/f0c317a150854212bcaf9399d8ab381a.png)
hbase(main):019:0> scan ‘stu4’,{RAW=>true,VERSIONS=>10}
ROW COLUMN+CELL
1001 column=info:name, timestamp=1619099552532, value=yangyang06
1 row(s) in 0.0830 seconds
删除数据时间点:flush或者大合并majorcompact
1、flush:删除的是内存的,无法删除磁盘中的数据。局限在同一个内存
2、compact:内存和磁盘的都会合并,旧数据删除。
3、delete,标记的。flush标记的不会删,compact会删除。(旧数据诈尸)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hoMOIR7k-1669555327284)(png/1619100664148.png)]](https://img-blog.csdnimg.cn/ca238e8b10544b6188b9678e3e2040f4.png)
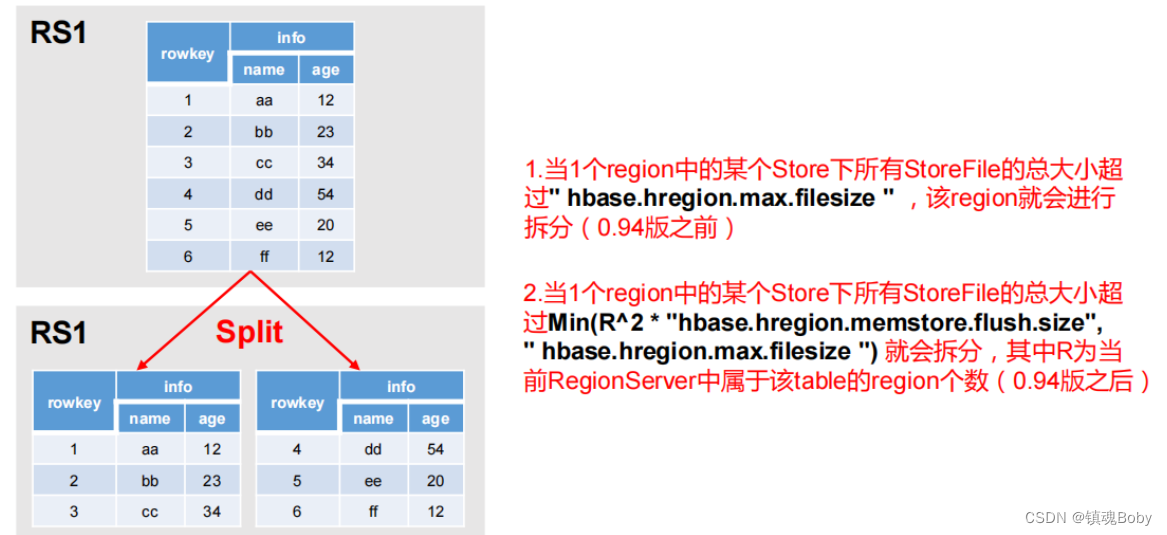
切分Region split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进
行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,
HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize, 该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下所有 StoreFile 的 总 大 小 超 过 Min(R^2 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize"),该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。















 4760
4760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









