









前言:SpringBoot2.x默认使用的数据源为:Hikari,我们也可以通过配置使用dbcp等常用数据源,因为阿里的druid数据源还提供了监控统计等功能,所以我们通常在springboot项目中整合使用Druid数据源
一、项目创建
- 首先使用idea创建springboot-web项目,不会的请点击:使用idea创建springboot项目
- 创建项目后在pom.xml文件中导入Druid数据源
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<!--连接mysql数据库,如果新建项目时已经选中了该组件,则不再需要手动添加其依赖-->
<!--如果后面测试无法连接数据库,则很有可能是springboot自定义的jar包版本过高,需要你手动指定低版本来兼容本机低版本的mysql数据库-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--如果不添加此依赖,自定义Druid属性则会绑定失败-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version >1.2.17</version>
</dependency>
注意:SpringBoot2.x之后,springboot底层自动配置类只支持Hikari和dbcp数据源,所以需要我们手动导入Druid数据源,另外如果不添加对 log4j依赖,则下面自定义的Druid属性会绑定失败!!!
- 在application.yml(application.properties)文件中修改springboot默认数据源为Druid -【csdn编辑器貌似不支持yml文件尴尬】
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://localhost:3306/attend
driver-class-name: com.mysql.jdbc.Driver
#修改springboot默认数据源为Druid
type: com.alibaba.druid.pool.DruidDataSourceC3P0Adapter
#数据源其他配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500- 因为springboot底层默认不支持Druid,所以需要我们自定义Druid数据源自动配置类,让上述数据源的其他属性配置生效
package com.cyn.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.servlet.Filter;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* @author:cyn
* @create:2018/12/29 18:36
* @description:Druid数据源自动配置类
*/
@Configuration
public class DruidConfig {
//注册数据源,并绑定配置文件中以spring.datasource前缀开头的相关属性
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druid(){
return new DruidDataSource();
}
//配置Druid的监控
//1.配置一个管理后台的Servlet
@Bean
public ServletRegistrationBean staViewServlet(){
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
Map<String,String> initParams = new HashMap<>();
//设置servlet初始化参数
initParams.put("loginUsername","admin");//登陆名
initParams.put("loginPassword","123456");//密码
initParams.put("allow","");//默认就是允许所有访问
initParams.put("deny","192.168.15.21");//拒绝相对应的id访问
bean.setInitParameters(initParams);
//加载到容器中
return bean;
}
//2.配置一个web监控的filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean<Filter> bean = new FilterRegistrationBean<>();
bean.setFilter(new WebStatFilter());
Map<String,String> initParams = new HashMap<>();
//设置filter初始化参数、
initParams.put("exclusions","*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*");//排除静态资源和请求
bean.setInitParameters(initParams);
//拦截所有请求
bean.setUrlPatterns(Arrays.asList("/*"));
//加载到容器中
return bean;
}
}二、项目测试
- 启动项目后在url地址栏输入:http://localhost:8080/druid/
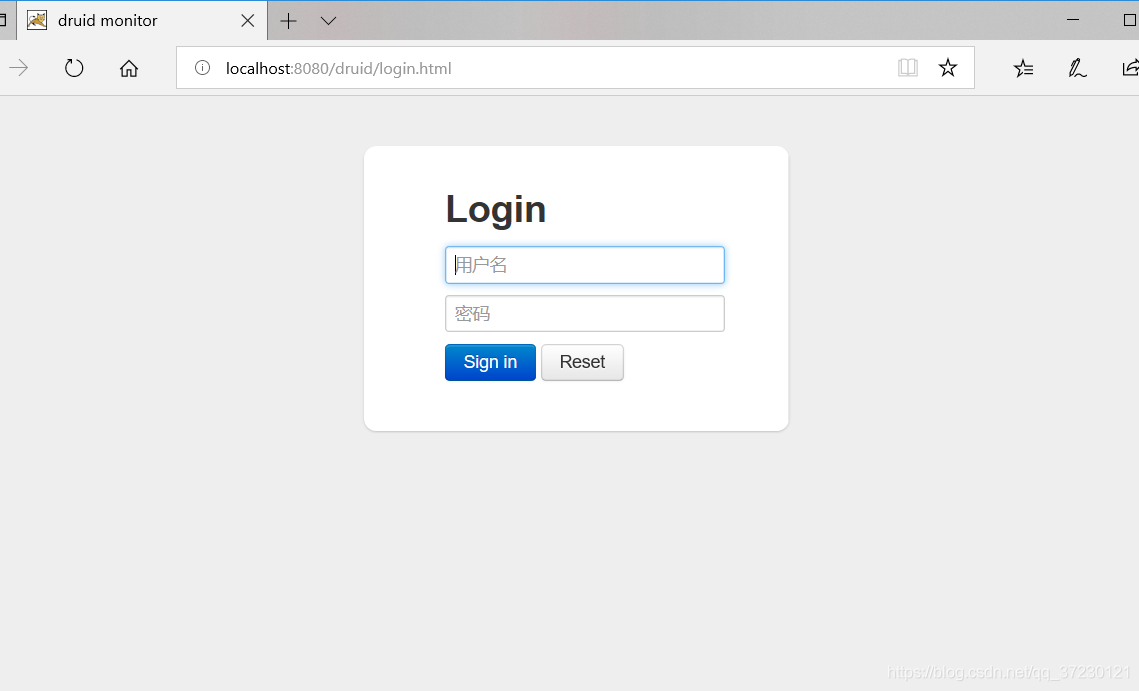
- 输入自动配置类中配置的用户名:admin和密码:123456
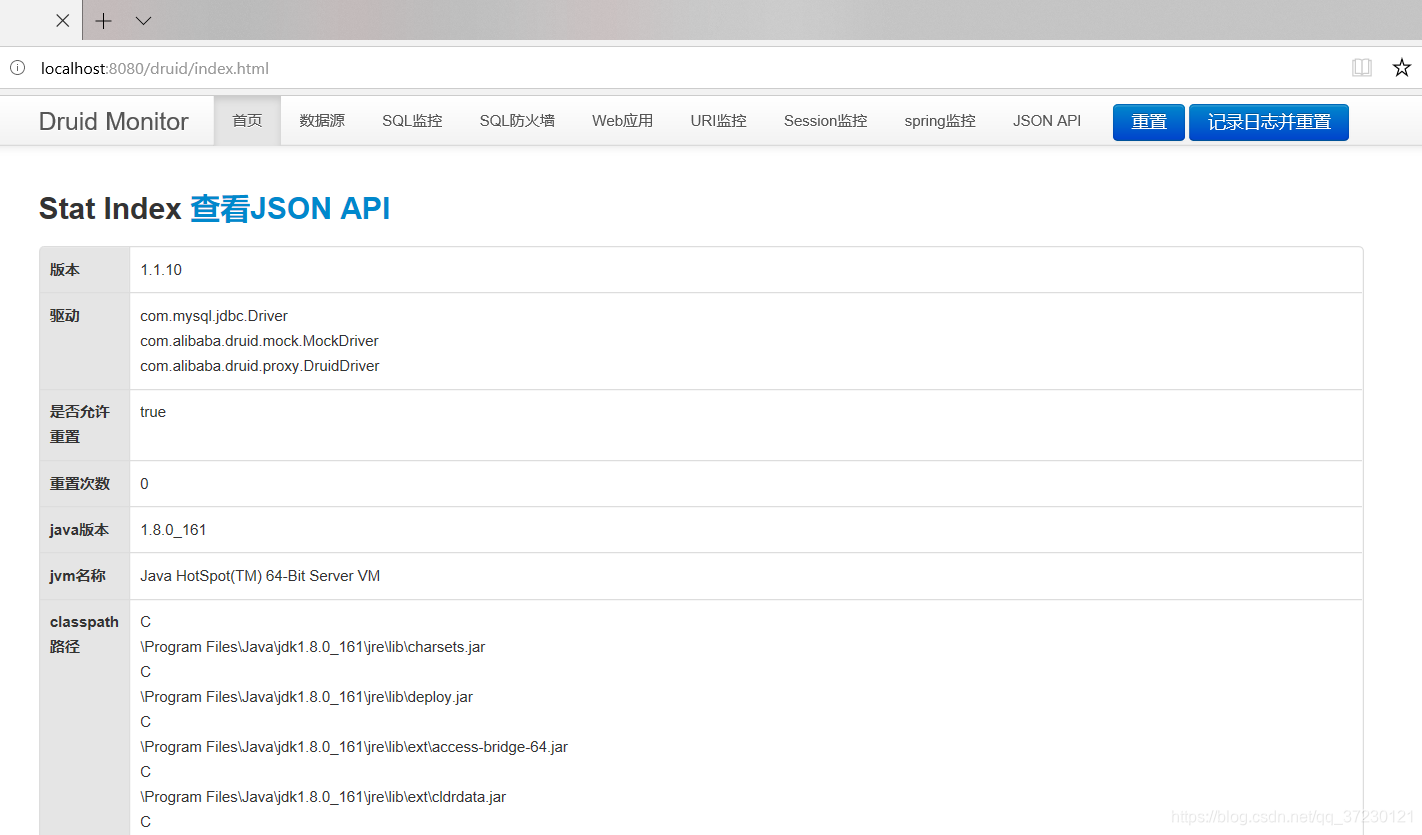
- 进入上述主页说明配置成功,如果失败,继续调试吧骚年
( ̄︶ ̄)↗[GO!]

















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









