







 本文详细解释了字节对齐的原理,包括为何存在对齐、CPU一次读取内存数量、编码时手动设置对齐方式(预编译标识和__attribute__((packed)))以及对性能的影响。
本文详细解释了字节对齐的原理,包括为何存在对齐、CPU一次读取内存数量、编码时手动设置对齐方式(预编译标识和__attribute__((packed)))以及对性能的影响。
1. 默认字节对齐
- 在所有结构体成员的字节长度都没有超出操作系统基本字节单位(32位操作系统是4,64位操作系统是8)的情况下
按照结构体中字节最大的变量长度来对齐; - 若结构体中某个变量字节超出操作系统基本字节单位
那么就按照系统字节单位来对齐。
注意:
并不是32位就直接按照4个字节对齐,64位就按照8个字节对齐。
2. 为什么存在字节对齐
2.1 了解 CPU 一次读取内存数
CPU 一次能读取多少内存要看数据总线是多少位
- 如果是16位,则一次只能读取 2 个字节
- 如果是32位,则可以读取 4 个字节,并且
CPU 不能跨内存区间访问。
例子:
假设有这样一个结构体如下:
struct st3
{
char a;
int b;
};
//在32位系统下,它就应该是8个字节的。
假设地址空间是类似下面这样的:

-
在没有字节对齐的情况下,
- 变量 a 就是占用了 0x00000001 这一个字节,而变量b则是占用了 0x00000002~0x000000005 这四个字节
- 此时 cpu 如果想从内存中读取变量 b,首先要从变量 b 的开始地址 0x00000002读到 0x0000004,然后再读取一次 0x00000005 这个字节,相当于读一个 int,cpu 从内存读取了两次。
-
如果进行字节对齐的话
- 变量 a 还是占用了 0x00000001 这一个字节,而变量 b 则是占用了 0x00000005~0x00000008 这四个字节
- 此时 cpu 要读取变量 b 的话,就直接一次性从 0x00000005 读到 0x00000008 ,就一次全部读取出来了。
总结:
字节对齐的根本原因其实在于 cpu 读取内存的效率问题,对齐以后,cpu读取内存的效率会更快。- 对齐的时候 0x00000002~0x00000004 这三个字节是浪费的,所以字节对齐实际上也有那么点以空间换时间的意思,具体写代码的时候怎么选择,其实是看个人的。
3. 编码时手动设置对齐
两种。
3.1 代码里添加预编译标识 pragma pack(n)
3.1.1 用法
- 使用预编译指令 #pragma pack (n) 来告诉编译器,使用我们指定的对齐值来取代缺省的。
- 对齐的算法: 随编译器变化
//用法如下
#pragma pack(n)//表示它后面的代码都按照n个字节对齐
struct st3
{
char a;
int b;
};
#pragma pack()//取消按照n个字节对齐,是对#pragma pack(n)的一个反向操作
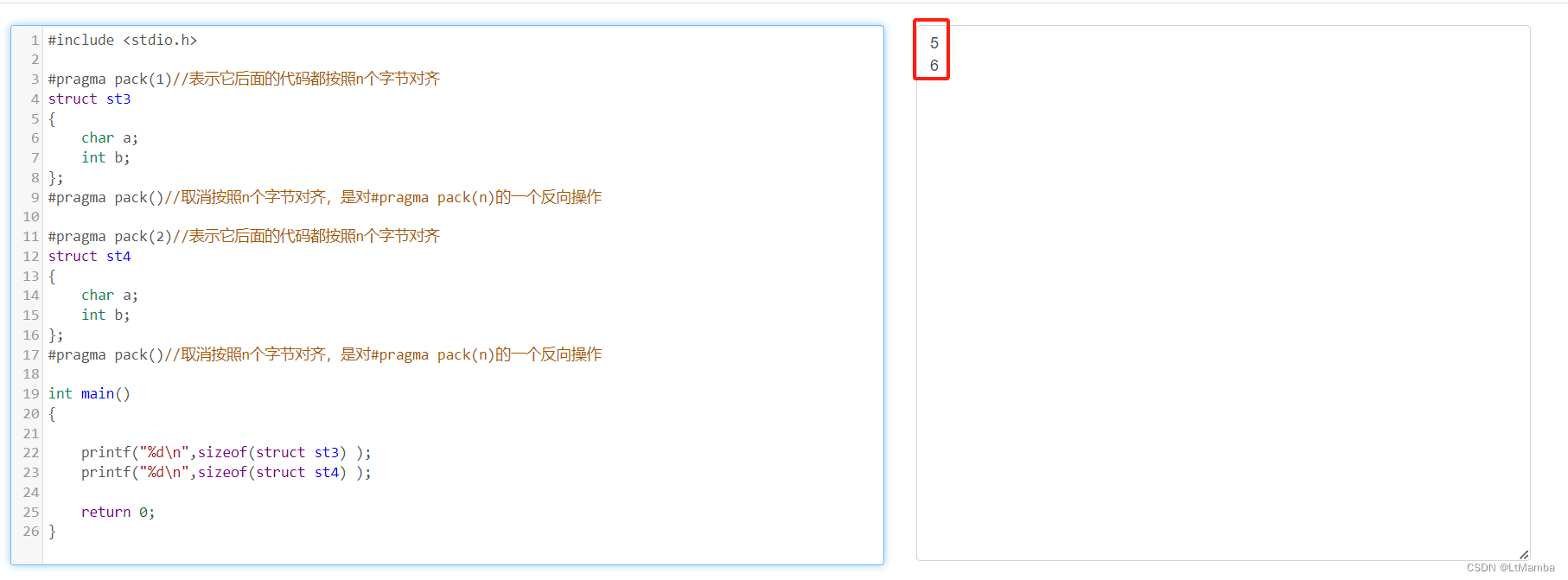
3.1.2 例子
#include <stdio.h>
#pragma pack(1)//表示它后面的代码都按照n个字节对齐
struct st3
{
char a;
int b;
};
#pragma pack()//取消按照n个字节对齐,是对#pragma pack(n)的一个反向操作
#pragma pack(2)//表示它后面的代码都按照n个字节对齐
struct st4
{
char a;
int b;
};
#pragma pack()//取消按照n个字节对齐,是对#pragma pack(n)的一个反向操作
int main()
{
printf("%d\n",sizeof(struct st3) );
printf("%d\n",sizeof(struct st4) );
return 0;
}
3.2 定义结构体时指定__attribute__((packed))
3.2.1 用法
__attribute__ ((packed))的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。这个功能是跟操作系统没关系,跟编译器有关.
//用法如下
struct bbb
{
char a;
int b;
}__attribute__((packed));//直接按照实际占用字节来对齐,其实就是相当于按照1个字节对齐了
//这里计算sizeof(st3)=5
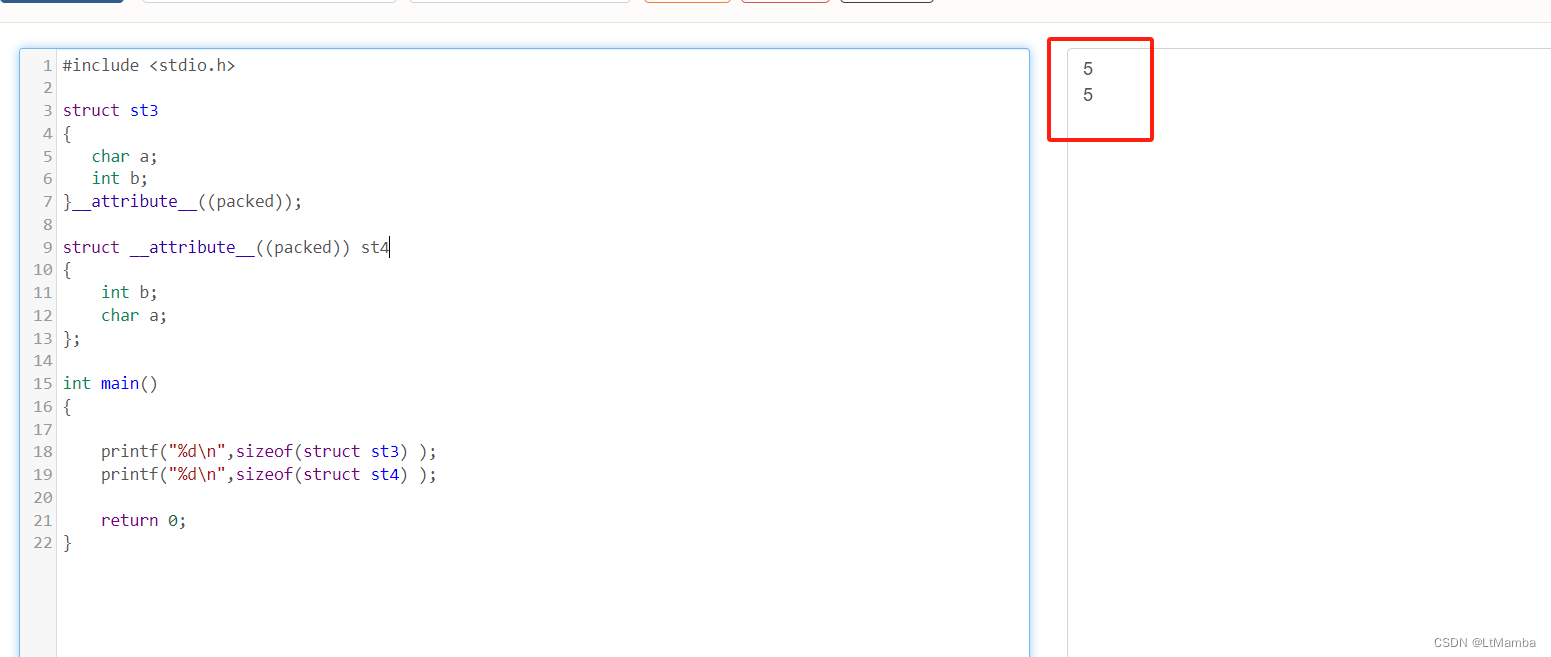
3.2.2 例子
#include <stdio.h>
struct st3
{
char a;
int b;
}__attribute__((packed));
struct __attribute__((packed)) st4
{
int b;
char a;
};
int main()
{
printf("%d\n",sizeof(struct st3) );
printf("%d\n",sizeof(struct st4) );
return 0;
}

















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









