







在介绍模拟退火算法之前,我们先认识一下爬山算法。
在爬山法寻找最优值的过程中,先随机生成一个点,计算其适应度值f(x),然后再其左领域和右领域中依照步长各选取一个点计算其适应度值f(xleft),f(xright),比较其三者,将适应度最大值点作为下一次迭代的初始点,直至寻找到最大值点。
爬山算法是一种典型的贪婪算法是一种狭隘的没有顾及全局的算法,如图所示在使用爬山算法寻找最大值时容易陷入局部最优。
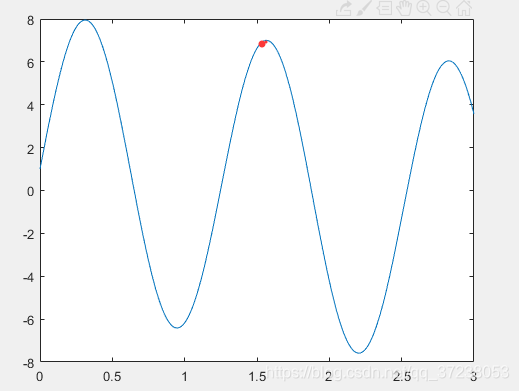
模拟退火算法原理
本文力求通俗易懂,故不在讲述物理层次的原理,我们回到爬山算法,爬山算法有一个非常重大的缺陷是容易陷入局部最优,并且陷入局部最优之后不能跳出。造成这样一种现象的原因是在每一次迭代中,我们采用贪婪的思想,只采用了最大值。
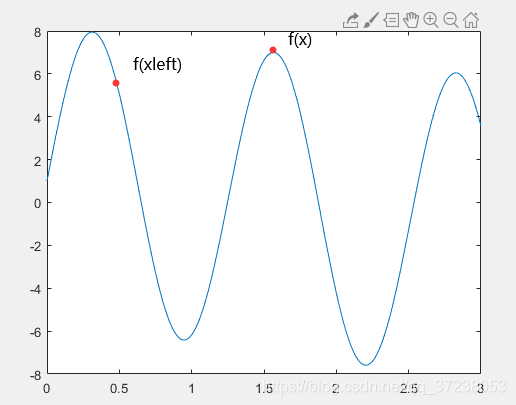
如图所示:按照爬山法的原理f(x)>f(xleft),所以将f(x)作为下一次迭代初值,而舍弃了可能更靠近全局最优值的f(xleft)。
所以引申出了一个议题:当左领域或者右领域的适应度值小于本身的适应度值,我们是否应该尝试去以一定的概率接受它来做下一次迭代的初值。
那么这个一定概率(p)到底是怎么计算的呢,按照咱们一般人的思维,当然是差距越小,咱们越容易去接受它。差距在函数寻找最优
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









