






爬取彼岸图网图片和图片名字,非4K,将爬取的图片放在文件夹中;
import requests
import re
from bs4 import BeautifulSoup
def get_Html(url):
html = requests.get(url)
html.encoding = 'gbk'
return html.text
def get_Img(url):
html = get_Html(url)
# 得到图片
imglist = re.findall('img src="(.*?)</b></a>',html)
print(len(imglist))
i=0
for imgurl in imglist:
#得到链接
imgurl = imglist[i].split("\" alt")
#得到img名字
imgname = imglist[i].split("<b>")
print(imgname[1])
imgurls = "https://pic.netbian.com"+imgurl[0]
img = requests.get(imgurls)
dir = "D:\\cc\\111\\"+"_"+imgname[1].replace("*"," ").replace("?"," ").replace(":"," ").replace("\""," ").replace("<"," ").replace(">"," ").replace("\\"," ").replace("/"," ").replace("|"," ")+".jpg"
with open(dir, "wb+") as f:
f.write(img.content)
i+=1
def img_page(url):
html = get_Html(url)
imgpagel = re.findall('</span><a (.*?)下一页',html)
imgpage = re.findall('">(.*)</a>',imgpagel[0])
print("共"+imgpage[0]+"页")
print("-------------------")
return imgpage[0]
#循环遍历页码
for j in range(1,2):
if j == 1:
url = "https://pic.netbian.com/4kdongman/"
# url = "https://pic.netbian.com/4kmeinv/"
# url = "https://pic.netbian.com/4kfengjing/"
imgpage = img_page(url)
else:
url = "https://pic.netbian.com/4kdongman/index_"+str(j)+".html"
# url = "https://pic.netbian.com/4kmeinv/index_"+str(j)+".html"
# url = "https://pic.netbian.com/4kfengjing/index_"+str(j)+".html"
if int(j) <= int(imgpage):
print("第"+str(j)+"页")
get_Img(url)
else:
print("下载完了")
break
爬取多少页,可以自行修改range,以上程序是爬取第一页图片
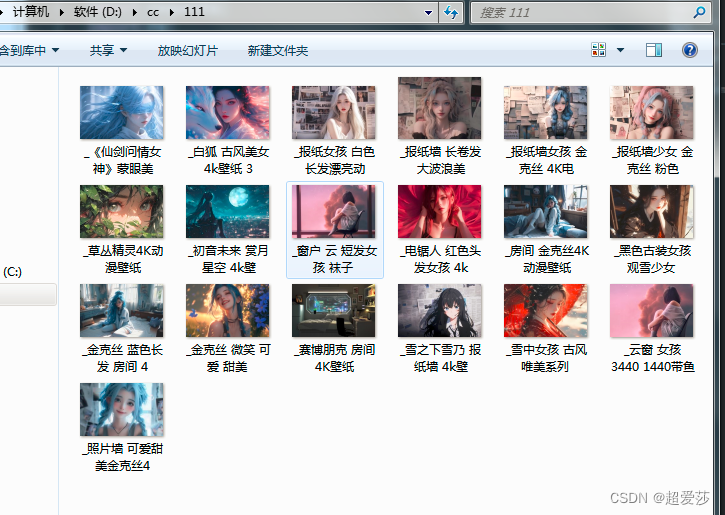
ps:仅供学习可用















 2663
2663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









