







Spark概述
1.1 什么是Spark
回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Hadoop与Spark历史
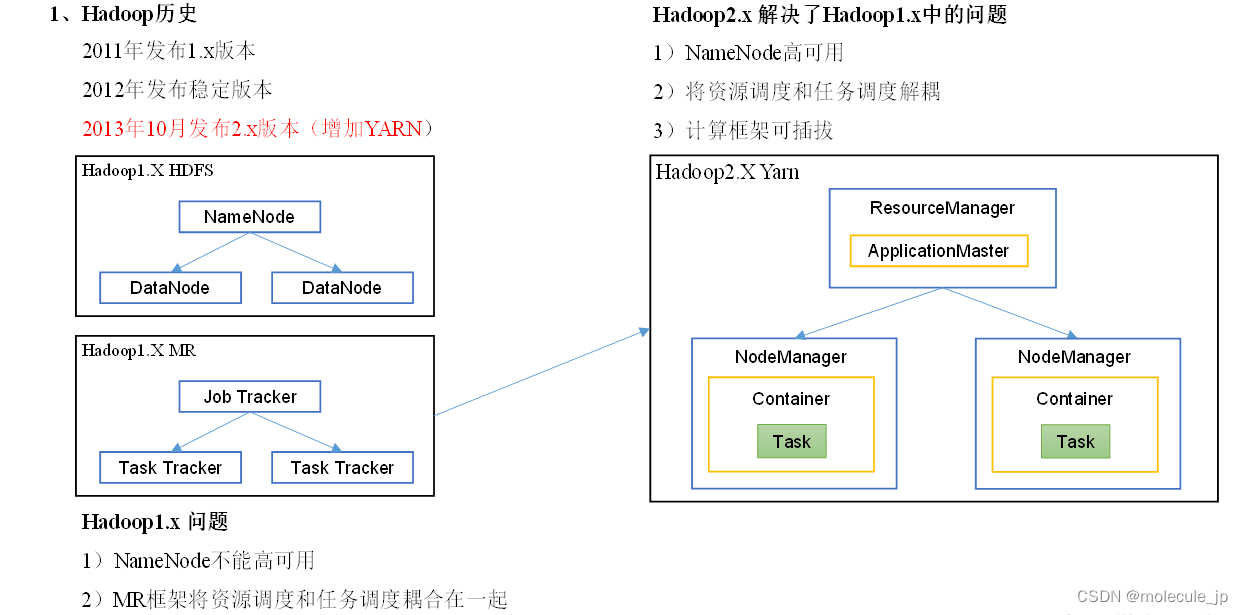
MR是进程模型,ResourceManager NodeManager都是进程!MapTask、ReduceTask也是进程。进程成本相比线程更高!
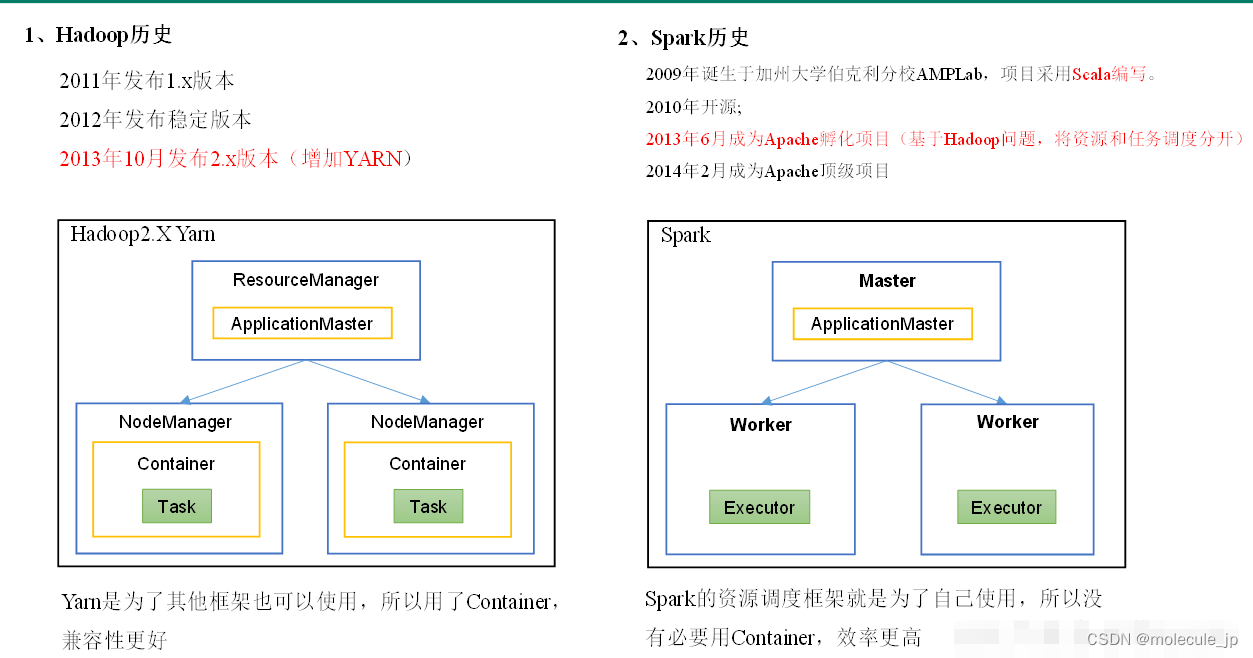
Hadoop的Yarn框架比Spark框架诞生的晚,所以Spark自己也设计了一套资源调度框架。Master 和Worker是常驻后台进程!线程模型ApplicationMaster和Executor是线程!
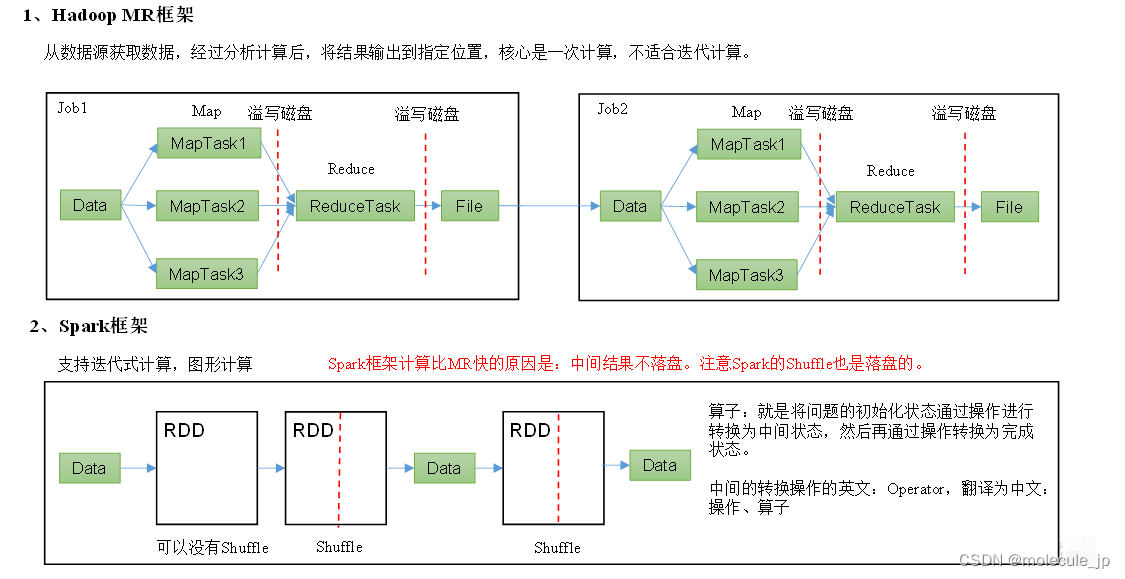
1.3 Hadoop与Spark框架对比
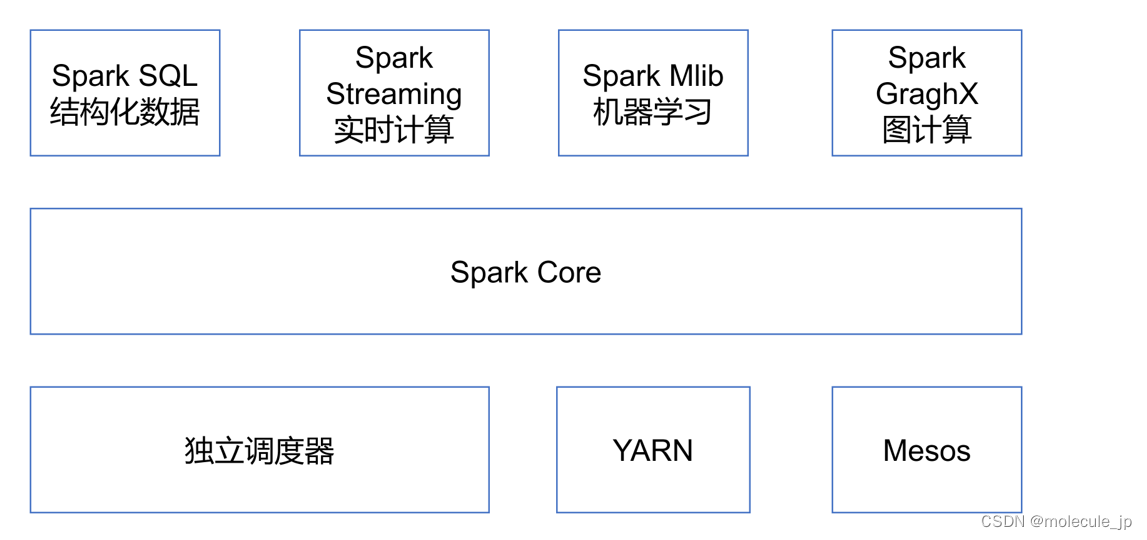
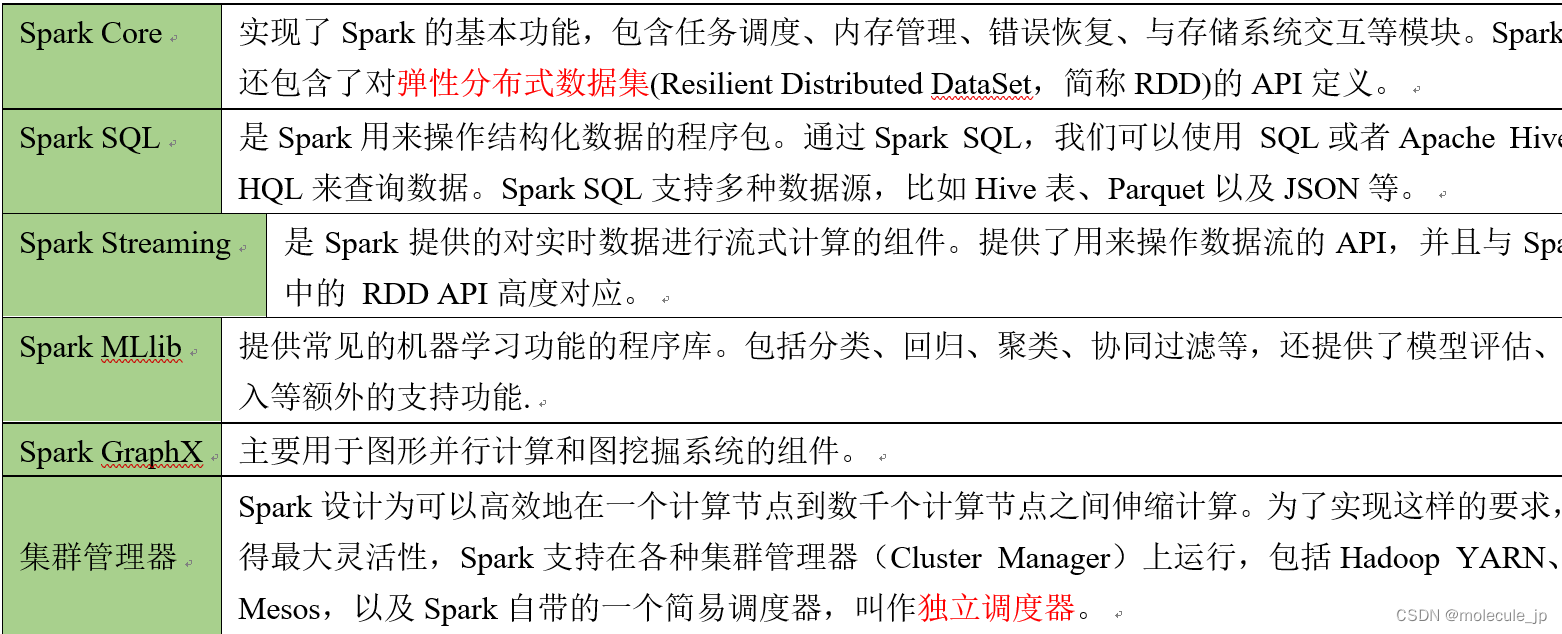
1.4 Spark内置模块
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
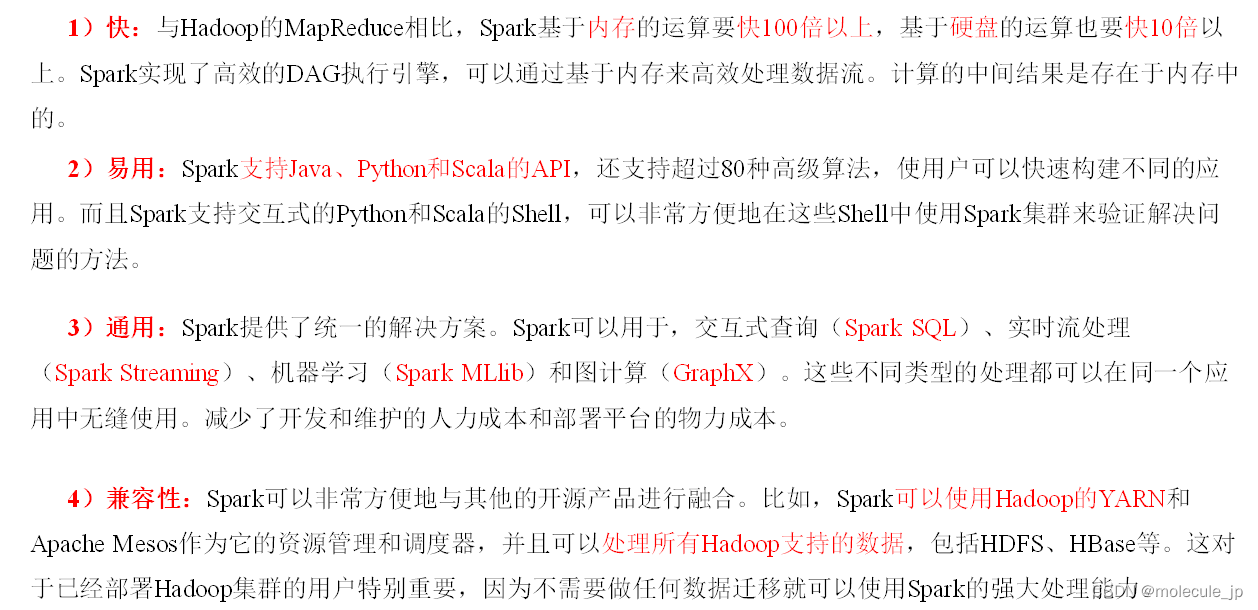
1.5 Spark特点
第2章 Spark运行模式
部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
(1)Local模式: 在本地部署单个Spark服务
(2)Standalone模式:Spark自带的任务调度模式。(国内常用)
(3)YARN模式: Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用)
(4)Mesos模式: Spark使用Mesos平台进行资源与任务的调度。(国内很少用)
2.1 Spark安装地址
1)官网地址:http://spark.apache.org/
2)文档查看地址:https://spark.apache.org/docs/3.3.0/
3)下载地址:https://spark.apache.org/downloads.html https://archive.apache.org/dist/spark/
2.2 Local模式
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。
2.2.1 安装使用
1)上传并解压Spark安装包
[aa@hadoop102 sorfware]$ tar -zxvf spark-3.3.0-bin-hadoop3.2.tgz -C /opt/module/
[aa@hadoop102 module]$ mv spark-3.3.0-bin-hadoop3.2 spark-local
2)官方求PI案例
[aa@hadoop102 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
可以查看spark-submit所有参数:
[aa@hadoop102 spark-local]$ bin/spark-submit
① --class:表示要执行程序的主类;
② --master local[2]
·local: 没有指定线程数,则所有计算都运行在一个线程当中,没有任何并行计算
·local[K]:指定使用K个Core来运行计算,比如local[2]就是运行2个Core来执行
效果:
20/09/20 09:30:53 INFO TaskSetManager:
20/09/15 10:15:00 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
20/09/15 10:15:00 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
· local[*]:默认模式。自动帮你按照CPU最多核来设置线程数。如CPU有8核,Spark会自动设置8个线程计算。 效果:
20/09/20 09:30:53 INFO TaskSetManager:
20/09/15 10:15:58 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
20/09/15 10:15:58 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/09/15 10:15:58 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
20/09/15 10:15:58 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
20/09/15 10:15:58 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
20/09/15 10:15:58 INFO Executor: Running task 5.0 in stage 0.0 (TID 5)
20/09/15 10:15:59 INFO Executor: Running task 7.0 in stage 0.0 (TID 7)
20/09/15 10:15:59 INFO Executor: Running task 6.0 in stage 0.0 (TID 6)
③ spark-examples_2.12-3.3.0.jar:要运行的程序;
④ 10:要运行程序的输入参数(计算圆周率π的次数,计算次数越多,准确率越高);
3)结果展示
该算法是利用蒙特·卡罗算法求PI。

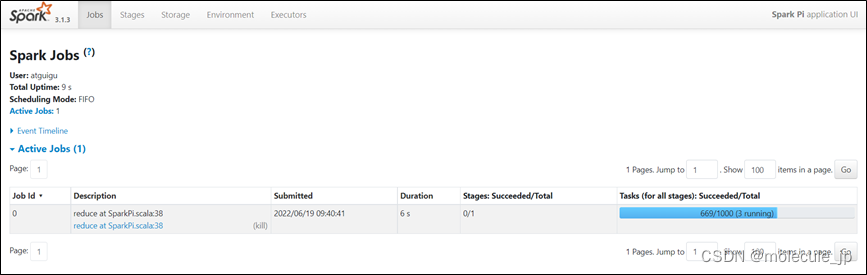
2.2.2 查看任务运行详情
再次运行求PI任务,增加任务次数
[aa@hadoop102 spark-local]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.3.0.jar \
1000
在任务运行还没有完成时,可登录hadoop102:4040查看程序运行结果
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









