







flink 编程模型及核心概念
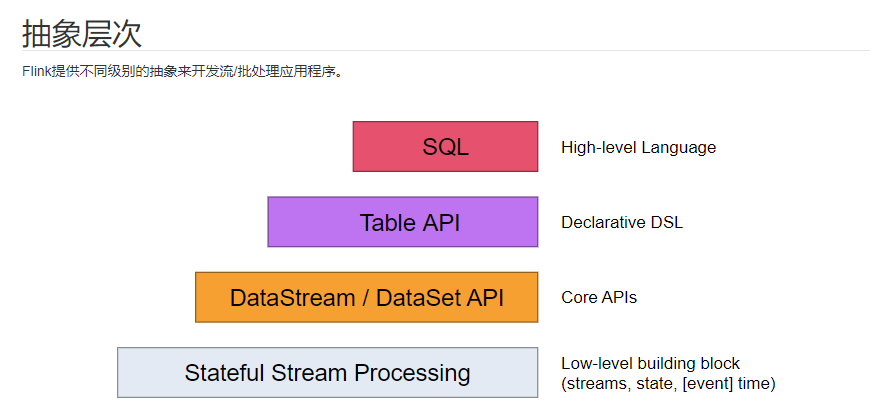
抽象层级:
各种分布式处理框架处理流程比较:

DataSet and DataStream
批处理:DataSet
流处理:DataStream
flink编程模型:
Flink程序看起来像是转换数据集合的常规程序。每个程序包含相同的基本部分:
-
获得一个
execution environment。getExecutionEnvironment() createLocalEnvironment() createRemoteEnvironment(String host, int port, String... jarFiles) -
加载/创建初始数据。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> text = env.readTextFile("file:///path/to/file"); -
指定此数据的转换。
val input: DataSet[String] = ... val mapped = input.map { x => x.toInt } -
指定放置计算结果的位置。
writeAsText(path: String) print() -
触发程序执行。(流处理)
execute()一、数据key值指定:
使用场景:
某些转换(join,coGroup,keyBy,groupBy)要求在元素集合上定义键。其他转换(Reduce,GroupReduce,Aggregate,Windows)允许数据在应用之前在key上分组。
DataSet(groupBy)
DataSet<...> input = // [...] DataSet<...> reduced = input .groupBy(/*define key here*/) .reduceGroup(/*do something*/);DataStream(keyBy)
DataStream<...> input = // [...] DataStream<...> windowed = input .keyBy(/*define key here*/) .window(/*window specification*/);(1)元组的键创建
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VTDwOlm9-1634026908876)(https://raw.githubusercontent.com/dingzhenying/MDGif/master/img/20190704153640.png)]
(2)使用Field Expressions定义键
您可以使用基于字符串的字段表达式来引用嵌套字段,并定义用于分组,排序,连接或coGrouping的键。
字段表达式可以非常轻松地选择(嵌套)复合类型中的字段,例如Tuple和POJO类型。
// some ordinary POJO (Plain old Java Object) class WC(var word: String, var count: Int) { def this() { this("", 0L) } } val words: DataStream[WC] = // [...] val wordCounts = words.keyBy("word").window(/*window specification*/) // or, as a case class, which is less typing case class WC(word: String, count: Int) val words: DataStream[WC] = // [...] val wordCounts = words.keyBy("word").window(/*window specification*/)字段表达式语法:
- 按字段名称选择POJO字段。例如,
"user"指POJO类型的“user”字段。 - 通过1偏移字段名称或0偏移字段索引选择元组字段。例如
"_1",分别"5"引用Scala Tuple类型的第一个和第六个字段。 - 您可以在POJO和Tuples中选择嵌套字段。例如,
"user.zip"指POJO的“zip”字段,其存储在POJO类型的“user”字段中。支持POJO和元组的任意嵌套和混合,例如"_2.user.zip"或"user._4.1.zip"。 - 您可以使用
"_"通配符表达式选择完整类型。这也适用于非Tuple或POJO类型的类型。
class WC(var complex: ComplexNestedClass, var count: Int) { def this() { this(null, 0) } } class ComplexNestedClass( var someNumber: Int, someFloat: Float, word: (Long, Long, String), hadoopCitizen: IntWritable) { def this() { this(0, 0, (0, 0, ""), new IntWritable(0)) } }这些是上面示例代码的有效字段表达式:
"count":类中的count字段WC。"complex":递归选择POJO类型的字段复合体的所有字段ComplexNestedClass。"complex.word._3":选择嵌套的最后一个字段Tuple3。"complex.hadoopCitizen":选择HadoopIntWritable类型。
- 按字段名称选择POJO字段。例如,
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









