







 超级会员免费看
超级会员免费看
Flink出现的背景
目前流处理主要的计算引擎有:Storm,SparkStreaming。但是这个两个计算引擎都有自己的局限性。Storm实现了低延迟,但是目前还没有实现高吞吐,也不能在故障发生的时候准确的处理计算状态,同时也不能实现exactly-once。SparkStreaming通过微批处理方法实现了高吞吐和容错性,但是牺牲了低延迟和实时处理的能力,也不能使用窗口与自然时间相匹配。Flink的出现完美的解决了以上问题,这也是Flink出现的原因,Flink不仅能提供同时支持高吞吐和exactly-once语义的实时计算,还能够提供批量数据的处理,并且和其他的计算引擎相比,Flink能够区分出不同类型的时间并支持状态计算。
Flink 简介
Flink 的前身已经是柏林理工大学一个研究性项目, 在 2014 被 Apache 孵化器所接受,然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。Flink 是一个针对流数据和批数据的分布式处理引擎。主要是由 Java 代码实现。其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。就框架本身与应用场景来说,Flink 更相似与 Storm。下面让我们先来看下 Flink 的架构图。
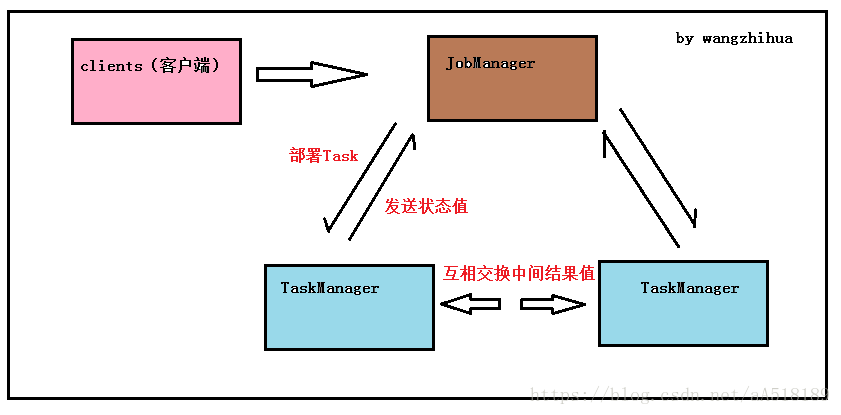
如图 所示,我们可以了解到 Flink 几个最基础的概
Client、JobManager 和 TaskManager:
Client 用来提交任务给 JobManager,JobManager 分发任务给 TaskManager 去执行,然后 TaskManager 会心跳的汇报任务状态。从架构图去看,JobManager 很像当年的 JobTracker,TaskManager 也很像当年的 TaskTracker。然而有一个最重要的区别就是 TaskManager 之间是是流(Stream)。其次,Hadoop 一代中,只有 Map 和 Reduce 之间的 Shuffle,而对 Flink 而言,可能是很多级而不像 Hadoop,是固定的 Map 到 Reduce。
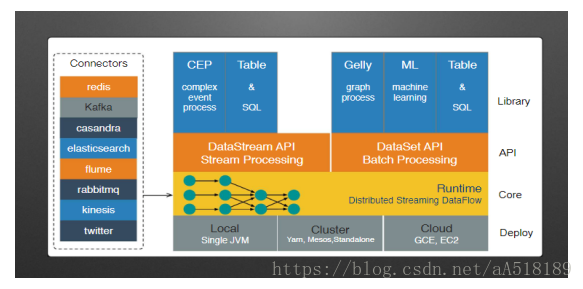
Flink 的生态圈(技术栈)
Flink 首先支持了 Scala 和 Java 的 API,Python 也正在测试中。Flink 通过 Gelly 支持了图操作,还有机器学习的 FlinkML。Table 是一种接口化的 SQL 支持,也就是 API 支持,而不是文本化的 SQL 解析和执行。值的一提的是flink分别提供了面向流处理接口(DataStream API)和面向批处理的接口(DataSet API),同时flink支持拓展库设计机器学习,FlinkML,复杂时间处理(CEP)以及图计算,还有分别针对流处理和批处理的Table API
执行配置
flink执行环境包括批处理和流出,所以要分两种情况进行执行配置
Flink 批处理环境
val env = ExecutionEnvironment.getExecutionEnvironmentFlink 流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment值得注意:在Flink 1.12已经实现了流批的大统一,作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
在 Flink 1.12 中,默认执行模式为 STREAMING,要将作业配置为以 BATCH 模式运行,可以在提交作业的时候,设置参数 execution.runtime-mode:
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar或者通过编程的方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeMode.BATCH);
接下来我可以在env进行相关的设置
StreamExecutionEnvironment包含ExecutionConfig允许为运行时设置工作的具体配置值。要更改影响所有作业的默认值。
val env = StreamExecutionEnvironment.getExecutionEnvironment
var executionConfig = env.getConfig可以使用以下配置选项:
enableClosureCleaner()/ disableClosureCleaner()。
默认情况下启用闭包清理器。闭包清理器删除Flink程序中对周围类匿名函数的不需要的引用。禁用闭包清除程序后,可能会发生匿名用户函数引用周围的类(通常不是Serializable)。这将导致序列化程序出现异常。
getParallelism()/ setParallelism(int parallelism)
设置作业的默认并行度。
getMaxParallelism()/ setMaxParallelism(int parallelism)
设置作业的默认最大并行度。此设置确定最大并行度并指定动态缩放的上限
还有其他的配置项可以配置,就不一一列举,可以参考flink官方网站
Apache Flink: What is Apache Flink? — Architecture
PS:最大并行度=container个数 * 每个container上最大slot数
设置并行性
Flink程序由多个任务(转换/运算符,数据源和接收器)组成。任务被分成几个并行实例以供执行,每个并行实例处理任务输入数据的子集。任务的并行实例数称为并行性。如果要使用保存点,还应考虑设置最大并行度(或max parallelism)。从保存点恢复时,您可以更改特定运算符或整个程序的并行度,此设置指定并行度的上限。这是必需的,因为Flink在内部将状态划分为密钥组,并且我们不能拥有+Inf多个密钥组,因为这会对性能产生不利影响。
操作级别
可以通过调用其setParallelism()方法来定义单个运算符,数据源或数据接收器的并行性 。例如
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = [...]DataStream<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1).setParallelism(5);wordCounts.print();env.execute("Word Count Example");执行环境级别
Flink程序在执行环境的上下文中执行。执行环境为其执行的所有操作符,数据源和数据接收器定义默认并行性。可以通过显式配置运算符的并行性来覆盖执行环境并行性。可以通过调用setParallelism()方法来指定执行环境的默认并行性 。要以并行方式执行所有运算符,数据源和数据接收器,请3按如下方式设置执行环境的默认并行度:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStream<String> text = [...]DataStream<Tuple2<String, Integer>> wordCounts = [...]
wordCounts.print();
env.execute("Word Count Example");客户级别
在向Flink提交作业时,可以在客户端设置并行性。客户端可以是Java或Scala程序。这种客户端的一个例子是Flink的命令行界面(CLI)。对于CLI客户端,可以使用指定parallelism参数-p。例如:
./bin/flink run -p 10 ../examples/*WordCount-java*.jar
基本API(流处理和批处理)
批处理是流处理的一种非常特殊的情况。Flink的特殊之处就在于既可以把数据当做流进行处理也可以把数据当作有限流进行批处理。可以理解为:
DataSet API用于批处理:相当于spark core
DataStream API用于流式处理:相当于 spark streaming
流处理与批处理的底层区别
Apache Flink 在网络传输层面有两种数据传输模式:
- PIPELINED模式 :即一条数据被处理完成以后,立刻传输到下一个节点进行处理。
- BATCH 模式 :即一条数据被处理完成后,并不会立刻传输到下一个节点进行处理,而是写入到缓存区,如果缓存写满就持久化到本地硬盘上,最后当所有数据都被处理完成后,才将数据传输到下一个节点进行处理。
Flink的基本数据模型
flink的基本数据类型是数据流(dataSet和dataStream)和事件(流中的数据)的序列,对比spark的基本数据模型是Rdd 。在flink中流可以是无界的(dataStream)也可以是有界(dataSet)。flink使用数据流上的变换(算子)来描述数据的处理,每个算子生成一个新的数据流,在算子,DAG,上下游算子链接(chaining)这些方面和saprk差不多。flink的节点(vertex)大致相当于spark的阶段(stage)。
DAG执行和spark的区别
flink在执行时,一个事件在一个节点处理完后的输出就可以发送到下一个节点立即处理。这样执行引擎不会带来额外的延迟。与之相应的,所有节点需要同时运行。而spark的micro batch和一般的batch执行一样,处理完上游的stage得到输出才开始处理下游的stage。
DataSet和DataStream
Flink具有特殊类DataSet和DataStream在程序中表示数据。您可以将它们视为可以包含重复项的不可变数据集合。在DataSet数据有限,对于一个DataStream元素的数量可以是无界的。这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。你也不能简单地检查里面的元素。集合最初通过在flink程序添加源创建和新的集合从这些通过将它们使用API方法如衍生map,filter等等。
Flink计划的剖析
Flink程序看起来像是转换数据集合的常规程序。每个程序包含相同的基本部分:
- 获得一个execution environment,
- 加载/创建初始数据,
- 指定此数据的转换,
- 指定放置计算结果的位置,
- 触发程序执行
我们现在将概述每个步骤,请参阅相应部分以获取更多详细信息。请注意,Scala DataSet API的所有核心类都可以在org.apache.flink.api.scala包中找到, 而Scala DataStream API的类可以在org.apache.flink.streaming.api.scala中找到 。
这StreamExecutionEnvironment是所有Flink计划的基础。您可以使用以下静态方法获取一个StreamExecutionEnvironment:
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(host: String, port: Int, jarFiles: String*)通常,您只需要使用getExecutionEnvironment(),因为这将根据上下文做正确的事情:如果您在IDE中执行程序或作为常规Java程序,它将创建一个本地环境,将在本地计算机上执行您的程序。如果您从程序中创建了一个JAR文件,并通过命令行调用它 ,则Flink集群管理器将执行您的main方法并getExecutionEnvironment()返回一个执行环境,以便在集群上执行您的程序。
读取数据
对于指定数据源,执行环境有几种方法可以使用各种方法从文件中读取:您可以逐行读取它们,CSV文件或使用完全自定义数据输入格式。要将文本文件作为一系列行读取,您可以使用:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val text: DataStream[String] = env.readTextFile("file:///path/to/file")这将为您提供一个DataStream,然后您可以在其上应用转换来创建新的派生DataStream。
您可以通过使用转换函数调用DataSet上的方法来应用转换。
例如,map转换如下所示:
val input: DataSet[String] = ...val mapped = input.map { x => x.toInt }
这将通过将原始集合中的每个String转换为Integer来创建新的DataStream。
数据输出
一旦有了包含最终结果的DataStream,就可以通过创建接收器将其写入外部系统。这些只是创建接收器的一些示例方法:
writeAsText(path: String)print()
一旦您指定的完整程序,你需要触发执行程序调用 execute()上StreamExecutionEnvironment。根据执行的类型,ExecutionEnvironment将在本地计算机上触发执行或提交程序以在群集上执行。
该execute()方法返回一个JobExecutionResult,包含执行时间和累加器结果。
Flink编程模型
flink处理数据的几个注意点
每来一条数据都能够触发计算
Apache Flink是基于上一次的计算结果进行增量计算的
Apache Flink 会利用State存储计算结果
DataSet和DataStream相关算子太多就不一一列举了,使用时可以参考官方文档。在这举两个例子进行展示flink的编程模型
案例一:基于文件(本地,hdfs)的wordcount
public class FunctionTest {
public static void main(String[] args) throws Exception {
//创建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取文本文件中的数据
DataStreamSource<String> streamSource = env.readTextFile("C:/flink_data/1.txt");
//进行逻辑计算
SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream = streamSource
.flatMap(new Splitter())
.keyBy(0)
.sum(1);
dataStream.print();
//设置程序名称
env.execute("Window WordCount");
}
}实现 FlatMapFunction
public class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}案例二:读取kafak中的数据保存到hdfs中
添加maven依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.10</artifactId>
<version>1.1.3</version>
</dependency>程序代码
object DataFkafka {
def main(args: Array[String]): Unit = {
//设置kafka连接参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "ip:9092");
properties.setProperty("zookeeper.connect", "ip:2181");
properties.setProperty("group.id", "res");
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置检查点时间间隔
env.enableCheckpointing(1000)
//设置检查点模式
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//创建kafak消费者,获取kafak中的数据
val myConsumer: FlinkKafkaConsumer010[String] = new FlinkKafkaConsumer010[String]("flink", new SimpleStringSchema(), properties)
val kafkaData: DataStream[String] = env.addSource(myConsumer)
kafkaData.print()
//数据保存到hdfs
kafkaData.writeAsText("hdfs://ip:9000/output/flink.txt")
print("kafka")
//设置程序名称
env.execute("data_from_kafak_wangzh")
}
}java和scala对比可以看出 还是scala比较简洁。
检查点 checkpoint
Flink的检查点特性在流处理器中是独一无二的,程序运行时有flink自动生成,它使得flink可以准确的维持状态,实现数据的一致性(exactly-once),并且高效的重新处理数据。
检查点介绍
Flink的检查点机制实现了标准的Chandy-Lamport算法,并用来实现分布式快照。在分布式快照当中,有一个核心的元素:Barrier。屏障作为数据流的一部分随着记录被注入到数据流中。屏障永远不会赶超通常的流记录,它会严格遵循顺序。屏障将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每一个屏障携带着快照的ID,快照记录着ID并且将其放在快照数据的前面。屏障不会中断流处理,因此非常轻量级。来自不同快照的多个屏障可能同时出现在流中,这意味着多个快照可能并发地发生。
举例说明:就像多个人一起数一串项链的珠子数量,几个人在说话,可能某一时刻,忘记数量是多少了,此时如果我们每五个珠子就栓一条不同的颜色,并且提前设置好规则。比如红的代表数五个,黄色的代表数了10珠子,以次类推,那么当我们忘记数了个珠子的时候多少时,就可以看一下绳子的颜色,就知道最新的绳子代表的珠子说,重新从绳子哪里继续数珠子的个数。
下图是checkpoint的整体逻辑图,其中ckpt是检查点屏障。在数据流中,每一天数据都会严格按照检查点前和检查点后的规定,被处理。检查点屏障也会像数据一样在算子之前流动。当flink算子遇到检查点屏障时,它会将检查点在数据流的位置记录下来,如果数据来自kafak那么位置就是偏移量。
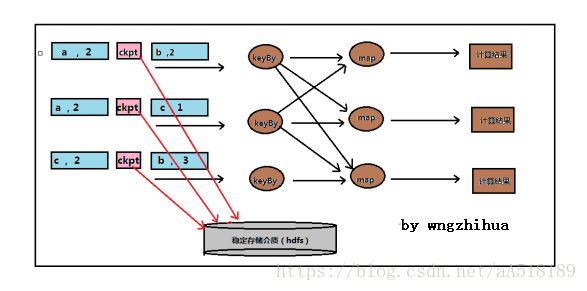
当检查点操作完成,结果状态和位置会备份到稳定的存储介质中如下图。需要注意的是:如果检查点操作失败了,flink会丢弃该检查点继续正常执行,因为之后的某一个检查点很大程度会成功,虽然这样恢复时间有点长,但是对状态的保障依旧很有力,只有在一系列连的检查点操作失败flink才会报错。
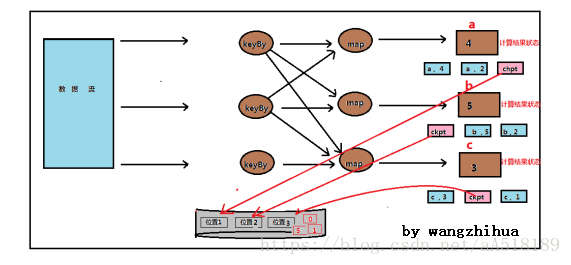
Checkpoint 的执行流程
每一个 Flink 作业都会有一个 JobManager ,JobManager 里面的 checkpoint coordinator 管理整个作业的 checkpoint 过程。用户通过 env 设置 checkpoint 的时间间隔,使得 checkpoint coordinator 定时将 checkpoint 的 barrier 发送给每个 source subtask。当 source 算子实例收到一个 barrier 时,它会暂停自身的数据处理,然后将自己的当前 缓存数据 state 保存为快照 snapshot,并且持久化到指定的存储,最后算子实例向 checkpoint coordinator 异步发送一个确认信号 ack,同时向所有下游算子广播该 barrier 和恢复自身的数据处理。以此类推,每个算子不断制作 snapshot 并向下游广播 barrier,直到 barrier 传递到 sink 算子实例,此时确定全局快照完成。
具体流程
JobManager 向 Source 算子发送 Barrier ,初始化
Checkpoint,即JM向Source发起Trigger操作;
各个Source 算子一旦收到 Barrier 之后,开始Init自身的State,并同时向下游发送 Barrier;
下游算子收到 Barrier 后,进行 Barrier Alignment
处理,且若有多个input时并且收到所有的input的Barrier才会开始做Init
State,同时继续往下游发送Bassier,直到sink算子
(1.10之前需要Barrier对齐,1.11以后可以选择UnAlignment);
算子做自身的CP时,分为同步和异步,
同步阶段的 Snapshot操作:
a.对state做深拷贝。
b.将写操作封装在异步的FutureTask中;
异步阶段的 Snapshot:
a.执行同步阶段创建的FutureTask
b.向Checkpoint Coordinator发送ACK响应;
各个算子(或者说Task) 做完 Checkpoint 之后,再上报 JobManager,JM收到所有算子的ACK,则认为这次CP完成了。

① Acknowledged 表示有多少个 subtask 对这个 Checkpoint 进行了 ack,从图中可知,共50个 subtask,这50个 subtask 都完成 ack。
② Latest Acknowledgement 表示所有 subtask 的最后 ack 的时间;
③ End to End Duration 表示所有 subtask 中完成 snapshot 的最长时间;
④ State Size 表示当前 Checkpoint 的 state 大小(如果是增量 checkpoint,则表示增量大小);
⑤ Buffered During Alignment 表示在 barrier 对齐阶段累计多少数据(如果这个数据过大,则间接表示对齐比较慢)
检查点的设置
1. checkpoint 保留策略
默认情况下,checkpoint 不会被保留,取消程序时即会删除他们,但是可以通过配置保留定期检查点,根据配置 当作业失败或者取消的时候 ,不会自动清除这些保留的检查点 。
java :
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);ExternalizedCheckpointCleanup 可选项如下:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作业时保留检查点。请注意,在这种情况下,您必须在取消后手动清理检查点状态。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作业时删除检查点。只有在作业失败时,检查点状态才可用。
需要注意
即使使用了RETAIN_ON_CANCELLATION命令,当使用flink stop命令来停止任务时也会删除Checkpoint 目录,这是因为这个机制是适用于使用cancel命令取消的任务的。
2. Checkpoint 配置
与SavePoint 类似 ,checkpoint 保留的是元数据文件和一些数据文件
默认情况下checkpoint 只保留 一份最新数据,如果需要进行checkpoint数据恢复 ,可以通过全局设置的方式设置该集群默认的checkpoint 保留数,以保证后期可以从checkpoint 点进行恢复 。 同时为了 及时保存checkpoint状态 还需要在服务级别设置 checkpoint 检查点的 备份速度 。
全局配置:
flink-conf.yaml
// 设置 checkpoint全局设置保存点
state.checkpoints.dir: hdfs:///checkpoints/
// 设置checkpoint 默认保留 数量
state.checkpoints.num-retained: 20
注意 如果将 checkpoint保存在hdfs 系统中 , 需要设置 hdfs 元数据信息
: fs.default-scheme:
服务级别设置:
java:
// 设置 checkpoint 保存目录
env.setStateBackend(new RocksDBStateBackend("hdfs:///checkpoints-data/");
// 设置checkpoint 检查点间隔时间
env.enableCheckpointing(5000);
// 默认checkpoint功能是disabled的,想要使用的时候需要先启用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
// ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
env.getCheckpointConfig().setPreferCheckpointForRecovery,恢复任务时,是否从最近一个比较新的 savepoint 处恢复,默认是 false;
env.getCheckpointConfig().enableUnalignedCheckpoints,是否开启试验性的非对齐的 checkpoint,可以在反压情况下极大减少 checkpoint 的次数;env.getCheckpointConfig().setTolerableCheckpointFailureNumber()
设置,容忍度,检查点创建失败的容忍度,就是说,这个值默认的是0,就是不容忍检查点失败,如果检查点失败了,那么就代表任务也挂了,这个时候就执行重启,按照配置的重启策略进行job粒度重启
flink-conf.yaml中配置
execution.checkpointing.interval: 5000
execution.checkpointing.mode: EXACTLY_ONCE
state.backend: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/checkpoints
execution.checkpointing.timeout: 600000
execution.checkpointing.min-pause: 500
execution.checkpointing.max-concurrent-checkpoints: 1
state.checkpoints.num-retained: 3
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
增量检查点
Flink程序容错机制的核心是检查点。检查点是一个全局的、异步的程序快照,它周期性的生成并送到持久化存储。 当发生故障时,Flink使用最新的检查点进行重启。一些Flink的用户在程序“状态”中保存了GB甚至TB的数据。在大状态下,创建检查点通常很慢并且耗资源,因此Flink1.3版本开始引入“增量式的检查点”。https://ververica.cn/developers/manage-large-state-incremental-checkpoint/。在引入“增量式的检查点”之前,每一个Flink的检查点都保存了程序完整的状态。在大部分情况下这是不必要的,因为上一次和这次的检查点之前 ,状态发生了很大的变化,所以我们创建了“增量式的检查点”。增量式的检查点仅保存过去和现在状态的差异部分。增量式的检查点可以为拥有大量状态的程序带来很大的提升。
如何使用
现在只能通过RocksDB state back-end来获取增量式检查点的功能,这是由RocksDB本身的特性决定的。RocksDB是一个基于日志结构合并树(LSM树)的键值式存储引擎,有兴趣的同学可以自行调研了解一下。Flink使用RocksDB内置的备份机制来合并检查点数据。Flink 增量式检查点的数据不会无限制的增大,它会自动合并老的检查点数据并清理掉。
要启用这个机制,添加如下设置:
|
项目中加入rocksdb的maven依赖
|
flink增量检查点,flink会自动删除旧的检查点文件吗?
flink中的增量检查点目前仅由rocksdb状态后端支持,后者完成了大部分繁重的工作。rocksdb基于日志结构的合并树,它自然地支持增量检查点。 有关rocksdb的介绍,请参阅https://github.com/facebook/rocksdb/wiki/rocksdb-basics. 数据链的长度由rocksdb中使用的层数限制。由于每个级别的大小通常是前一级别大小的几倍,因此不需要很长的链来存储大量数据。“原始检查点”不是一个整体——它由lsm树的多个级别中保存的状态组成,并存储在一组sst文件中——一旦压缩开始,原始检查点就不再以任何可识别的方式存在。 压实只是rocksdb工作原理的一部分;它不是由flink实现的,也不是为flink实现的。压实是在背景中或多或少连续发生的。 flink会注意自动删除不再有用的sst文件(检查点由一组sst文件组成)
RocksDB增量模式checkpoint大小持续增长的问题及解决
原因总结
在增量checkpoint过程中,虽然sst文件所保存的状态数据大小保持动态平衡,但是LOG日志和MANIFEST文件仍然会当向持续增长,所以checkpoint会越来越大,越来越慢。
解决办法
1. 在生产环境关闭Rocksdb日志(保持state.backend.rocksdb.log.level的默认配置即可);
2. 设置manifest文件的滚动阈值,我设置的是10485760byte;
非对齐检查点Unaligned Checkpoint
对其检查点(aligned ck)的缺点
-
反压时无法做出 Checkpoint :在反压时候 barrier 无法随着数据往下游流动,造成反压的时候无法做出 Checkpoint。但是其实在发生反压情况的时候,我们更加需要去做出对数据的 Checkpoint,因为这个时候性能遇到了瓶颈,是更加容易出问题的阶段;
-
Barrier 对齐阻塞数据处理 :阻塞对齐对于性能上存在一定的影响;
-
恢复性能受限于 Checkpoint 间隔 :在做恢复的时候,延迟受到多大的影响很多时候是取决于 Checkpoint 的间隔,间隔越大,需要 replay 的数据就会越多,从而造成中断的影响也就会越大。但是目前 Checkpoint 间隔受制于持久化操作的时间,所以没办法做的很快。
针对这些痛点,Flink 在最近几个版本一直在持续的优化,Unaligned Checkpoint 就是其中一个机制。barrier 算子在到达 input buffer 最前面的时候,就会开始触发 Checkpoint 操作。它会立刻把 barrier 传到算子的 OutPut Buffer 的最前面,相当于它会立刻被下游的算子所读取到。通过这种方式可以使得 barrier 不受到数据阻塞,解决反压时候无法进行 Checkpoint 的问题。
当我们把 barrier 发下去后,需要做一个短暂的暂停,暂停的时候会把算子的 State 和 input output buffer 中的数据进行一个标记,以方便后续随时准备上传。对于多路情况会一直等到另外一路 barrier 到达之前数据,全部进行标注。
通过这种方式整个在做 Checkpoint 的时候,也不需要对 barrier 进行对齐,唯一需要做的停顿就是在整个过程中对所有 buffer 和 state 标注。这种方式可以很好的解决反压时无法做出 Checkpoint ,和 Barrier 对齐阻塞数据影响性能处理的问题
如何开启非对齐检查点
env.getCheckpointConfig().enableUnalignedCheckpoints(Boolean.TRUE);
Flink状态压缩
Checkpoint 和 Savepoint 具有压缩功能(默认值:关闭),使用 snappy 压缩工具。
//状态压缩适合大状态任务
env.getConfig().setUseSnapshotCompression(true);Flink状态管理之State Backend(状态的后端存储)
1、默认情况下,state会保存在taskmanager的内存中,checkpoint会存储在JobManager的内存中。
2、state 的store和checkpoint的位置取决于State Backend的配置(env.setStateBackend(…))
3、一共有三种State Backend:MemoryStateBackend、FsStateBackend、RocksDBStateBackend
(1)MemoryStateBackend:state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中,基于内存的state backend在生产环境下不建议使用
(2)FsStateBackend:state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中,可以使用hdfs等分布式文件系统
(3)RocksDBStateBackend:RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地。RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用
State Backend的两种使用方式
第一种:单任务调整
修改当前任务代码
env.setStateBackend(new FsStateBackend("hdfs://namenode:9000/flink/checkpoints"));
或者new MemoryStateBackend()
或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依赖】
注:如果代码里面没有设置检查的类型配置默认是MemoryStateBackend,节点重启状态就丢失了
第二种:全局调整
修改flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
注意:state.backend的值可以是下面几种:jobmanager(MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)代码中配置时依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.0</version>
</dependency>故障紧跟检查点的情况
当检查点操作已经完成,但是故障紧随其后。这种情况下,flink会重新拓扑,将输入流倒回到上一个检查点,然后恢复状态值并从该出重新继续计算,可以保证在剩下的记录被处理后,得到的map算子的状态与没有发生故障的状态一致,值得注意的是有些数据会重复计算,也就是数据可能会出现局部的重复。但是我们可以将数据流写入到特殊的系统中(比如文件系统,数据库)来解决这个问题。
启用和配置检查点
默认情况下,禁用检查点。为了使检查点在StreamExecutionEnvironment上,调用
enableCheckpointing(n),其中Ñ是以毫秒为单位的检查点间隔。
检查点的其他参数包括:
完全一次与至少一次:您可以选择将模式传递给enableCheckpointing(n)方法,以在两个保证级别之间进行选择。对于大多数应用来说,恰好一次是优选的。至少一次可能与某些超低延迟(始终为几毫秒)的应用程序相关。
checkpoint timeout(检查点超时):如果当前检查点未完成,则中止检查点的时间。
minimum time between checkpoints检查点之间的最短时间:为确保流应用程序在检查点之间取得一定进展,可以定义检查点之间需要经过多长时间。如果将此值设置为例如5000,则无论检查点持续时间和检查点间隔如何,下一个检查点将在上一个检查点完成后不迟于5秒启动。请注意,这意味着检查点间隔永远不会小于此参数。
通过定义“检查点之间的时间”而不是检查点间隔来配置应用程序通常更容易,因为“检查点之间的时间”不易受检查点有时需要比平均时间更长的事实的影响(例如,如果目标存储系统暂时很慢)。
请注意,此值还表示并发检查点的数量为一。
number of concurrent checkpoints并发检查点数:默认情况下,当一个检查点仍处于运行状态时,系统不会触发另一个检查点。这可确保拓扑不会在检查点上花费太多时间,也不会在处理流方面取得进展。可以允许多个重叠检查点,这对于具有特定处理延迟的管道(例如,因为函数调用需要一些时间来响应的外部服务)而感兴趣,但是仍然希望执行非常频繁的检查点(100毫秒) )在失败时重新处理很少。
当定义检查点之间的最短时间时,不能使用此选项。
externalized checkpoints外部化检查点:您可以将外围检查点配置为外部持久化。外部化检查点将其元数据写入持久存储,并且在作业失败时不会自动清除。这样,如果您的工作失败,您将有一个检查点可以从中恢复。有关外部化检查点的部署说明中有更多详细信息。
env.getConfig().isFailTaskOnCheckpointError();fail/continue task on checkpoint errors关于检查点错误的失败/继续任务:这确定如果在执行任务的检查点过程中发生错误,任务是否将失败。这是默认行为。或者,当禁用此选项时,任务将简单地拒绝检查点协调器的检查点并继续运行
检查点监控
- Checkpoint Counts
- Triggered:自作业开始以来触发的 checkpoint 总数。
- In Progress:当前正在进行的 checkpoint 数量。
- Completed:自作业开始以来成功完成的 checkpoint 总数。
- Failed:自作业开始以来失败的 checkpoint 总数。
- Restored:自作业开始以来进行的恢复操作的次数。这还表示自 提交以来已重新启动多少次。请注意,带有 savepoint 的初始提交也算作一次恢复,如果 JobManager 在此操作过程中丢失,则该统计将重新计数。
- Latest Completed Checkpoint:最新(最近)成功完成的 checkpoint。点击
More details可以得到 subtask 级别的详细统计信息。 - Latest Failed Checkpoint:最新失败的 checkpoint。点击
More details可以得到 subtask 级别的详细统计信息。 - Latest Savepoint:最新触发的 savepoint 及其外部路径。点击
More details可以得到 subtask 级别的详细统计信息。 - Latest Restore:有两种类型的恢复操作。
- Restore from Checkpoint:从 checkpoint 恢复。
- Restore from Savepoint:从 savepoint 恢复。
检查点的历史记录
检查点历史记录保留有关最近触发的检查点的统计信息,包括当前正在进行的检查点。
- ID:触发的检查点的ID。每个检查点的ID都会增加,从1开始。
- Status:检查点的当前状态,正在进行中(),完成(),或失败()。如果触发的检查点是保存点,您将看到一个 符号。
- Trigger Time::在JobManager中触发检查点的时间。
- Latest Acknowledgement:在JobManager上收到最新确认的任何子任务的时间(如果尚未收到确认,则为n / a)。
- End to End Duration:从触发时间戳到最近确认的持续时间(如果尚未收到确认,则为n / a)。完整检查点的端到端持续时间由确认检查点的最后一个子任务确定。这个时间通常比单个子任务需要实际检查点状态要大。
- Checkpointed Data Size:所有已确认子任务的状态大小。
- 在对齐期间缓冲:在对齐所有已确认子任务期间缓冲的字节数。如果在检查点期间发生流对齐,则此值仅为> 0。如果检查点模式是
AT_LEAST_ONCE这将始终为零,因为至少一次模式不需要流对齐。 - Sync Duration:Checkpoint 同步部分的持续时间。这包括 operator 的快照状态,并阻塞 subtask 上的所有其他活动(处理记录、触发计时器等)。
- Async Duration:Checkpoint 的异步部分的持续时间。这包括将 checkpoint 写入设置的文件系统所需的时间。对于 unaligned checkpoint,这还包括 subtask 必须等待最后一个 checkpoint barrier 到达的时间(checkpoint alignment 持续时间)以及持久化数据所需的时间。
- Alignment Duration:处理第一个和最后一个 checkpoint barrier 之间的时间。对于 checkpoint alignment 机制的 checkpoint,在 checkpoint alignment 过程中,已经接收到 checkpoint barrier 的 channel 将阻塞并停止处理后续的数据。
- Start Delay:从 checkpoint barrier 创建开始到 subtask 收到第一个 checkpoint barrier 所用的时间。
历史大小配置
您可以通过以下配置键配置记住历史记录的最近检查点的数量。默认是10。
# Number of recent checkpoints that are remembered
web.checkpoints.history: 15检查点的相关配置
- Checkpointing Mode正好一次或至少一次。
- Interval:配置的检查点间隔。在此时间间隔内触发检查点。
- Timeout: 超时后,JobManager取消检查点并触发新的检查点。
- Minimum Pause Between Checkpoints: 检查点之间所需的最小暂停时间。检查点成功完成后,我们至少等待这段时间才能触发下一个检查点,这可能会延迟定期间隔。
- Maximum Concurrent Checkpoints:可以同时进行的最大检查点数。
- Persist Checkpoints Externally:启用或禁用。如果启用,则还列出外部化检查点的清除配置(删除时取消或保留)。
检查点恢复与保存
1.Checkpoin设置与保存
-
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前
- Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数。
state.checkpoints.num-retained: 20这样设置以后就查看对应的Checkpoint在HDFS上存储的文件目录 hdfs dfs -ls hdfs://namenode:9000/flink/checkpoints 如果希望回退到某个Checkpoint点,只需要指定对应的某个Checkpoint路径即可实现2.Checkpoint恢复
-
如果Flink程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个Checkpoint点进行恢复
-
-s 后面接的就是待恢复checkpoint的路径。
bin/flink run -s hdfs://namenode:9000/flink/checkpoints/467e17d2cc343e6c56255d222bae3421/chk-56/_metadata flink-job.jar程序正常运行后,还会按照Checkpoint配置进行运行,继续生成Checkpoint数据
SavePoint 剖析
1 全局一致性快照
- Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断
- 全局,一致性快照。可以保存数据源offset,operator操作状态等信息
- 可以从应用在过去任意做了savepoint的时刻开始继续消费
2 checkpoint理论
- 应用定时触发,用于保存状态,会过期
- 内部应用失败重启的时候使用
3 savePoint 理论
- 用户手动执行,是指向Checkpoint的指针,保存点包含检查点的元数据,不会过期,在升级的情况下使用
- 注意:为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐通过 uid(String) 方法手动的给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。
- 只要这些 ID 没有改变就能从保存点(savepoint)将程序恢复回来。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动的设置 ID。




分配Operator的ID
这是强烈建议为每一个Operator设置ID。主要的必要更改是通过该uid(String)方法手动指定操作员ID 。这些ID用于确定每个运算符的状态。
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID如果您未手动指定ID,则会自动生成它们。只要这些ID不变,您就可以从保存点自动恢复。生成的ID取决于程序的结构,并且对程序更改很敏感。因此,强烈建议手动分配这些ID。
保存点状态
您可以将保存点视为Operator ID -> State包含每个有状态运算符的映射:
Operator ID | State
------------+------------------------
source-id | State of StatefulSource
mapper-id | State of StatefulMapper在上面的例子中,打印接收器是无状态的,因此不是保存点状态的一部分。默认情况下,我们尝试将保存点的每个条目映射回新程序。
操作
您可以使用命令行客户端,以触发保存点,取消作业用的保存点,从保存点恢复和处置保存点。
使用Flink> = 1.2.0,也可以使用webui 从保存点恢复。
触发保存点
触发保存点时,会创建一个新的保存点目录,其中将存储数据和元数据。可以通过配置默认目标目录或使用触发器命令指定自定义目标目录来控制此目录的位置(请参阅:targetDirectory参数)。
注意:目标目录必须是JobManager(s)和TaskManager(例如分布式文件系统上的位置)可访问的位置。
例如,使用FsStateBackend或RocksDBStateBackend:
# Savepoint target directory
/savepoints/
# Savepoint directory
/savepoints/savepoint-:shortjobid-:savepointid/
# Savepoint file contains the checkpoint meta data
/savepoints/savepoint-:shortjobid-:savepointid/_metadata
# Savepoint state
/savepoints/savepoint-:shortjobid-:savepointid/...注意: 虽然看起来好像可以移动保存点,但由于_metadata文件中的绝对路径,目前无法进行保存。请按照FLINK-5778了解取消此限制的进度。
请注意,如果使用MemoryStateBackend,则元数据和保存点状态将存储在_metadata文件中。由于它是自包含的,您可以移动文件并从任何位置恢复。
注意:不建议移动或删除正在运行的作业的最后一个保存点,因为这可能会影响故障恢复。保存点对完全一次的接收器有副作用,因此为了确保一次性语义,如果在最后一个保存点之后没有检查点,则保存点将用于恢复。
触发保存点
$ bin/flink savepoint :jobId [:targetDirectory]这将触发具有ID的作业的保存点:jobId,并返回创建的保存点的路径。您需要此路径来还原和部署保存点。
使用YARN触发保存点
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId举例:
./flink savepoint 121d542db04cb1622b7e7b24b1a42297 hdfs://xxxxxx/savepoints1 -yid application_15874884738_0119这将触发具有ID :jobId和YARN应用程序ID 的作业的保存点:yarnAppId,并返回创建的保存点的路径。
使用Savepoint取消作业
$ bin/flink cancel -s [:targetDirectory] :jobId这将以原子方式触发具有ID的作业的保存点:jobid并取消作业。此外,您可以指定目标文件系统目录以存储保存点。该目录需要可由JobManager和TaskManager访问。
从保存点恢复
$ bin/flink run -s :savepointPath [:runArgs]这将提交作业并指定要从中恢复的保存点。您可以指定保存点目录或_metadata文件的路径。
案例
#!/bin/bash
source /etc/profile
nohup /usr/local/service/flink/bin/flink run \
-s hdfs://namenode/flink//savepoint-31940d-1fb580773f57 \
-m yarn-cluster \
-yn 5 \
-yjm 2048 \
-ytm 4096 \
-yqu rte \
-ys 2 \
-p 10 \
-ynm test \
-c cn.Data2Kafka \
/data/alg_realtime_feature_as_order_etl-1.0.jar \
--kafkaBrokers ip \
--sourcetopic zsc_as_order \
--groupId gd_004 \
--sinktopic ature_etl > /data/as_order_etl.log 2>&./flink run -s hdfs://HDFS_path/savepoints4/savepoint-9b45b4-3ee0d1660b06/_metadata -m yarn-cluster -yn 5 -yjm 1024 -ytm 4096 -ys 2 -p 10 -ynm kafka2kafka -c examples.Kafka2Kafka /data/wangzh/flink/kafka2kafka/bifrost-flink-1.0-SNAPSHOT-jar-with-dependencies.jar 删除任务并触发保存点
./flink cancel -s hdfs://xxxxxx/savepoints1 121d542db04cb1622b7e7b24b1a42297 -yid application_1550dsdsd8468_0119允许非恢复状态
默认情况下,resume操作将尝试将保存点的所有状态映射回您要还原的程序。如果删除了运算符,则可以通过--allowNonRestoredState(short -n:)选项跳过无法映射到新程序的状态:
$ bin/flink run -s :savepointPath -n [:runArgs]处置保存点
$ bin/flink savepoint -d :savepointPath这将处理存储的保存点:savepointPath。
请注意,也可以通过常规文件系统操作手动删除保存点,而不会影响其他保存点或检查点(请回想一下,每个保存点都是自包含的)。直到Flink 1.2,这是一个更乏味的任务,使用上面的savepoint命令执行。
4 savePoint的使用
1:在flink-conf.yaml中配置Savepoint存储位置
不是必须设置,但是设置后,后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置:
state.savepoints.dir: hdfs://namenode:9000/flink/savepoints
2:触发一个savepoint【直接触发或者在cancel的时候触发】bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
3:从指定的savepoint启动job
bin/flink run -s savepointPath [runArgs]数据源和接收器的容错保证
Flink的容错机制在出现故障时恢复程序并继续执行它们。此类故障包括机器硬件故障,网络故障,瞬态程序故障等。
只有当源参与快照机制时,Flink才能保证对用户定义状态的一次性状态更新。下表列出了Flink与捆绑连接器的状态更新保证。
请阅读每个连接器的文档以了解容错保证的详细信息
| Source | Guarantees | Notes |
|---|---|---|
| Apache Kafka | exactly once | Use the appropriate Kafka connector for your version |
| AWS Kinesis Streams | exactly once | |
| RabbitMQ | at most once (v 0.10) / exactly once (v 1.0) | |
| Twitter Streaming API | at most once | |
| Collections | exactly once | |
| Files | exactly once | |
| Sockets | at most once |
为了保证端到端完全一次的记录传递(除了精确一次的状态语义之外),数据接收器需要参与检查点机制。下表列出了Flink与捆绑接收器的传送保证(假设一次状态更新):
| Sink | Guarantees | Notes |
|---|---|---|
| HDFS rolling sink | exactly once | Implementation depends on Hadoop version |
| Elasticsearch | at least once | |
| Kafka producer | at least once | |
| Cassandra sink | at least once / exactly once | exactly once only for idempotent updates |
| AWS Kinesis Streams | at least once | |
| File sinks | at least once | |
| Socket sinks | at least once | |
| Standard output | at least once | |
| Redis sink | at least once |
窗口
窗口是一种机制。允许许多事件按照时间或者其他特征进行分组,将每一组作为整体去分析计算。Flink中的窗口主要有时间窗口,计数窗口,回话窗口。并且我们要知道flink是唯一一个支持回话窗口的开源流处理器,这里主要介绍用处组多的时间窗口。
时间窗口
时间窗口是最简单,最有用的一种窗口,它支持滚动和滑动,几个简单的例子,对传感器的发出的数据进行求和
一分钟滚动窗口收集最近一分钟的数值,并在一分钟结束时输出总和,如下图
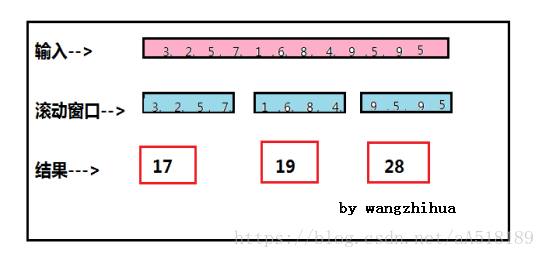
一分钟滑动窗口计算最近一分钟的数值总和,但是每半分钟滑动一次并输出结果,如下图
第一个滑动窗口对 3,2,5,7求和得到17,半分钟后窗口滑动,然后对2,5,7,1求和得到结果15以此类推。
时间窗口代码
一分钟的滑动窗口:
Stream.timeWindows(Time.minute(1))
每半分钟(30秒)滑动一次的一分钟滑动窗口
Stream.timeWindows(Time.minute(1),Time.second(30))
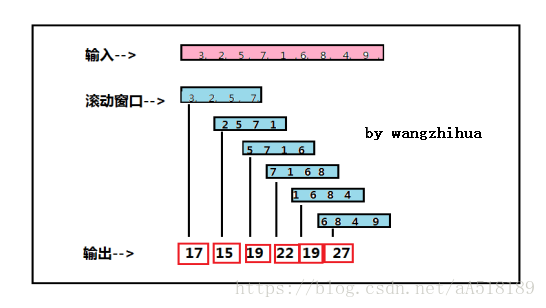
计数窗口
计数窗口的分组依据不再是时间,而是元素的数量。例如在上面的图-2也可以解释为由4个元素组成的计数窗口,并且每两个元素滑动一次,滚动和滑动计数窗口定义如下
Stream.countWindow(4)
Stream.countWindow(4,2)
注意;
计数窗口不如时间窗口那么严谨,要谨慎使用,比如其定义的元素数量为100,然而某一个key对应的元素永远达不到100个,那么计数窗口就会永远不关闭,则被该窗口占用的内存就浪费了,一种解决办法就是用时间窗口触发超时。
会话窗口
会话指的是活动阶段,其前后都是非活动阶段,例如某用户在与网站进行一系列的交互之后,关闭浏览器或者不在交互(非活动阶段)。会话需要有自己的处理机制,因为他们通常没有固定的持续时间,或者说固定的交互次数(有的可能点击3次就购买了物品,有的可能点击40次才购买物品)。
在flink中。会话窗口由时间设定。既希望等待多久认为会话已经结束。举例来说,以下代码表示,用户处于非活动时间超过五分钟既认为会话结束
input
.keyBy(<key selector>)
.window(sessionWindow.withGap(Time.minutes(5)))水印
现在有一个问题就是:如何判断所有的事件是否都已经到达,以及何时计算和输出窗口的结果?换言之就是:如何追踪事件时间,并知晓输入数据已经流入到某个事件时间呢?为了追踪事件时间,需要依靠由数据驱动的时钟,而不是系统时间。
水印是衡量事件时间进度的机制,Flink通过水印来推进事件时间。水印是嵌入在流中的常规记录(简单理解就是一个时间戳)。计算程序通常通过水获知某个时间点已到。比如对于一分钟的滚动窗口,假设水印标记时时间为:10:01:00,那么收到水印的窗口就知道不会再有早于该时间的记录出现,因为所有时间戳小于或等于该时间的事件都已经到达。这时,窗口就可以安全的计算并给出结果。水印使得事件时间和处理时间完全无关。迟到的水印并不会影响到结果的正确性,而会影响到结果的速度。
水印如何生成
在flink中,水印的生成由开发人员生成,这通常需要对相应的领域有一定的了解。完美的水印:时间戳小于水印标记时间的事件不会再出现。在特殊情况下(如非乱序事件流),最近一次事件的时间戳就可能是完美的水印。启发式水印则相反,它只估计时间,因此有可能出错,既迟到的时间:晚于水印出现。如果知道时间的迟到时间不会超过5秒,就可以将水印时间设为收到最大时间戳减去5秒。另一种做法是,采用一个flink作业的监控事件流,学习事件的迟到规律,并以此构成水印的生成模型。
水印案例图解
数据产生
假设源分别在时间13秒,第13秒和第16秒产生类型a的三个消息。(窗口大小只有10秒)。
这些消息将落入Windows中,如下所示。在第13秒产生的前两个消息将落入窗口1 [5s-15s]和window2 [10s-20s],第16个时间生成的第三个消息将落入window2 [ 10s-20s]和window3 [15s-25s] ]。每个窗口发出的最终计数分别为(a,2),(a,3)和(a,1)。
该输出可以被认为是预期的行为。现在我们将看看当一个消息到达系统的时候会发生什么。
消息到达延迟
现在假设其中一条消息(在第13秒生成)到达延迟6秒(第19秒),可能是由于某些网络拥塞。你能猜测这个消息会落入哪个窗口?
延迟的消息落入窗口2和3,因为19在10-20和15-25之间。在window2中计算没有任何问题(因为消息应该落入该窗口),但是它影响了window1和window3的结果。我们现在将尝试使用EventTime处理来解决这个问题。
解决方案
EventTime+Watermark
现在将水印设置为当前时间-5秒,这告诉Flink希望消息最多有5s的延迟,这是因为每个窗口仅在水印通过时被评估。由于我们的水印是当前时间-5秒,所以第一个窗口[5s-15s]将仅在第20秒被评估。类似地,窗口[10s-20s]将在第25秒进行评估,依此类推。

有状态的计算
流失计算分为有状态计算和无状态计算。无状态计算是观察每一个独立时间,并根据最后一个时间输出时间结果,有状态计算则是根据多个事件输出结果。
例如:
计算过去一个小时的平均温度就是有状态的计算,需要涉及多个事件共同计算出的结果。
广播变量
广播变量允许您为操作的所有并行实例提供数据集。这对于辅助数据集或与数据相关的参数化非常有用。然后,操作员可以将数据集作为集合访问。
- 广播:广播集通过名称注册withBroadcastSet(DataSet, String)
- 访问:可通过getRuntimeContext().getBroadcastVariable(String)目标运营商访问。
val data = env.fromElements("a", "b")
data.map(new RichMapFunction[String, String]() {
var broadcastSet: Traversable[String] = null
override def open(config: Configuration): Unit = {
// 3. Access the broadcast DataSet as a Collection
broadcastSet =getRuntimeContext().
getBroadcastVariable[String("broadcastSetName").asScala
}
def map(in: String): String = {
}}).withBroadcastSet(toBroadcast, "broadcastSetName")
注意:由于广播变量的内容保存在每个节点的内存中,因此不应该变得太大。对于标量值之类的简单事物,您可以简单地将参数作为函数闭包的一部分,或者使用该withParameters(...)方法传递配置。
控制延迟
默认情况下,元素不会逐个传输到网络上(这会导致不必要的网络流量),但会被缓冲。可以在Flink配置文件中设置缓冲区的大小(实际在计算机之间传输)。虽然此方法适用于优化吞吐量,但当传入流速度不够快时,可能会导致延迟问题。要控制吞吐量和延迟,您可以env.setBufferTimeout(timeoutMillis)在执行环境(或单个运算符)上使用以设置缓冲区填充的最长等待时间。在此之后,即使缓冲区未满,也会自动发送缓冲区。此超时的默认值为100毫秒。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);为了最大化吞吐量,设置setBufferTimeout(-1)哪个将删除超时和缓冲区只有在它们已满时才会被刷新。要最小化延迟,请将超时设置为接近0的值(例如5或10 ms)。应避免缓冲区超时为0,因为它可能导致严重的性能下降。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











